微软开发可高效揪除代码错误的BugLabs人工智能解决方案
微软研究院首席研究员 Miltos Alamanis 与高级首席研究主管 Marc Brockschmidt,刚刚在一篇博客文章中介绍了他们新开发的 BugLabs 人工智能。顾名思义。这是一套专门用于发现代码中的错误,帮助开发者更精准、高效地调试其应用程序的 AI 解决方案。而且它的开发过程,与创建生成对抗网络(GAN)的形式大致相同。

(来自:Microsoft Research Blog)
在《借助深度学习查找并修复错误》一文中,微软研究员介绍了他们设置的两个相互对抗的网络。其中一个旨在将小错误引入代码,另一个则旨在发现这些 bug 。
随着深度学习训练的持续推进,AI 的能力也变得愈加完善,最终成为了我们看到的这个特别擅长识别“隐藏在真是代码中的 bug”的人工智能。

这种方法的优点,在于全程无需自我监督或标记数据。Miltos Allamanis 与 Marc Brockschmidt 在报告中提到:
理论上,我们可以将之广泛地应用于‘捉迷藏’游戏 —— 教授机器去识别任务复杂的错误。遗憾的是,这些 bug 通常超出了现代人工智能方法的运用范围。
有鉴于此,研究团队决定更加专注于一组常见的错误 —— 包括不正确的比较(例如使用 <= 而不使用 < 或 > 符号、不适当的布尔运算符(与 / 或)、滥用变量(误用 i 而不是 j)等。

系统测试期间,微软研究员特别专注于 Python 代码。一旦检测器通过了训练,即可将它用于检测和修复实际代码中的 bug 。
不过为了均衡性能,他们还是手动注释了 Python Package Index 中包含的某些类型的小错误数据集。
最终与随机错误插入等其它替代方案相比,其“hide-and-seek”训练模型有高达三成的领先优势,前景很是光明。
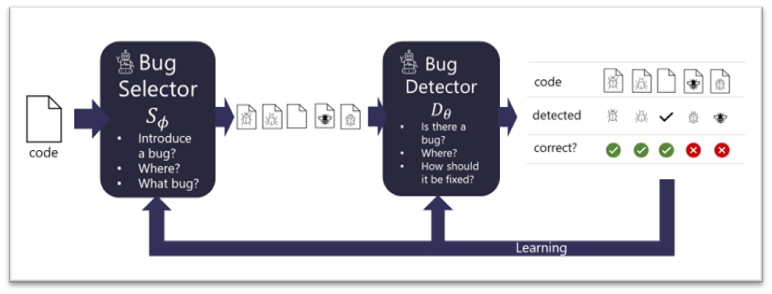
具体说来是,hide-and-seek 能够自动找到并修复大约 26% 的错误,且其中包括了 19 个此前未知的真实开源 GitHub 代码中的 bug 。
与此同时,现阶段的 AI 模型仍存在许多误报。在投入实际运用之前,显然还需要开展更多的改进。
最后,鉴于微软已经成功地推动了 GitHub 上的 GPT-3 项目,预计 hide-and-seek 也将很快迎来商业化应用。