iPhone 13 的刘海为什么缩小了?
iPhone 13 系列视频的第一期节目,我们先从最表层的变化开始聊起——刘海。今年 iPhone 13 刘海缩短,普遍认为的原因是,结构光模组中的点阵投射器体积缩小了。我们分别拆解了 iPhone 13 和 iPhone 12 的 Face ID 模组,对比发现,iPhone 13 的点阵投射器,芯片面积约 0.46 mm²,相比 iPhone 12 的 0.99 mm²,确实减少了 53%。

但如果从整体的封装体积上看,两者并没有太大的差距:

这是因为在今年的点阵投射器里,还把之前独立封装的泛光灯也集成了进去。而且今年泛光灯的芯片面积,也比前代减少了 48 %。

点阵和泛光合二为一, 是刘海缩小的第一大功臣。而更重要的,是原来听筒开孔的位置,从中间,移到了边框上。

但问题是,在安卓阵营,把听筒放到边框里在很多年就已经是基本操作了。如果移个听筒就可以省空间,那苹果为什么不早移呢?
要探究这个问题的答案,我们就要先搞明白,刘海里最重要的元件——Face ID 前前后后的所有事情。
何为结构光?
看过《亮剑》的同学可能会记得,李云龙带着炮兵,用大拇指测距,炮击敌人的桥段。这种用视差粗略判断距离的“跳眼法”,和结构光的原理十分相似。


大部分手机的摄像头,就是用两个镜头之间的视差,来估算主体深度,做背景虚化的。但这种方法,有一个明显的缺点:对于一些光滑、或者缺乏纹理的表面,摄像头因为找不到特征点,会很难做匹配。
就像一堵大白墙,往前 10 厘米,和往后 10 厘米,对摄像头来说,都是一片大白墙。只要墙够光滑,深度信息就判断不出来。

既然缺纹理,那我们就给它创造一点纹理。我们把其中一颗摄像头,变成一个投射器,主动往目标上投射纹理,再由另一颗摄像头捕获,这就是最基本的结构光模型了。

接下来,我们就来把苹果的 Face ID 里里外外拆个干净,一步一步地看,它是怎么实现的。
Face ID 模组的拆解和原理
苹果把 Face ID 模组中的点阵投射器、前摄和红外摄像头,放在了同一个金属支架上。这么做的原因,是为了让几个组件之间的相对位置,始终保持一致。

大家不要小看这一个小支架,这个支架可太讲究了,它的重要度,甚至不亚于里面任何一个元件,重要到苹果专门为它,和它的装配方式,都单独申请了一个专利。

因为在结构光系统中,投射器和红外摄像头,需要做非常精确的位置匹配,这个动作就叫做“标定(calibration)”。两者的距离、角度、哪怕有一点点变动,都会严重影响识别的准确度,甚至让整个系统罢工。
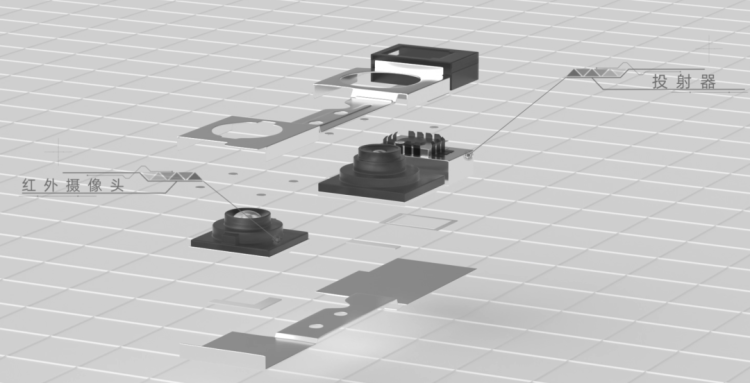
而为了让它们的位置保持相对固定,苹果在支架的连接处,专门做了用来增加强度的一个小“坡”,防止模组在装配的过程中,受外力作用在 Y 轴发生弯折,导致标定失效。在支架的侧面,还另有一条金属横梁,焊在上面,加固整体结构。

Face ID 组件在安装的时候,并不是用螺丝固定在机身里,而是用两块簧片压在屏幕和后盖之间,我们推测,这样做的目的,是为了让整个组件允许存在微小的整体位移。也就是说你的手机如果摔了,这些部件可能会松动,但是,点阵和摄像头,它们要动只会一起动,不会有相对的位移。

这一切的目的,是为了把点阵和摄像头之间距离的公差控制在 ±80 微米之内。
定好了两个组件的位置之后,下一步,我们来看模组里最关键的部件——点阵投射器。投射器的光源,苹果用的是 VCSEL——垂直腔面发射激光器。 叫它“垂直”,是因为它的发光方向,是垂直于硅基板的。相比于向水平方向发光的“边发射激光器”,VCSEL 的好处是,它可以投射出更圆的光斑,而且因为是垂直发光,它可以很容易地在一块硅基板上,用光掩模直接蚀刻出密集的阵列,而整个元件的厚度,可以做到很薄。

(左为 VCSEL,右为边发射激光器)
对于手机来说,它投射出的可分辨的点阵越多越密,识别的精度就越高。要把光点做多,有两种选择:要么把整块芯片做大,要么把点阵之间的间距做小。把芯片做大,面临两个问题:首先,VCSEL 成本很高,越大越花钱;而且手机里的空间,也不可能摆得下太大的器件。而如果保持芯片面积不变呢,点阵的密度,也是不能无限叠加的。依照目前的技术,VCSEL 点阵间距,一般不低于 18 微米。倒不是因为工艺上做不到,而是因为如果再做小,又要保证每个发光点的功率,它的散热压力会很大。

iPhone 12 上的 VCSEL,去掉导线,面积大概是 0.81mm²,一共放进了 321 个点。iPhone 13 又把密度增加了一倍,在 0.37 mm² 里,放进了 284 个点。平均密度已经达到 868个/ mm², 再做密,压力会越来越大。

那用这块两三百个点的芯片,要怎么投出 Face ID 需要的三万个光点呢?两个关键词:复制,和拼接。
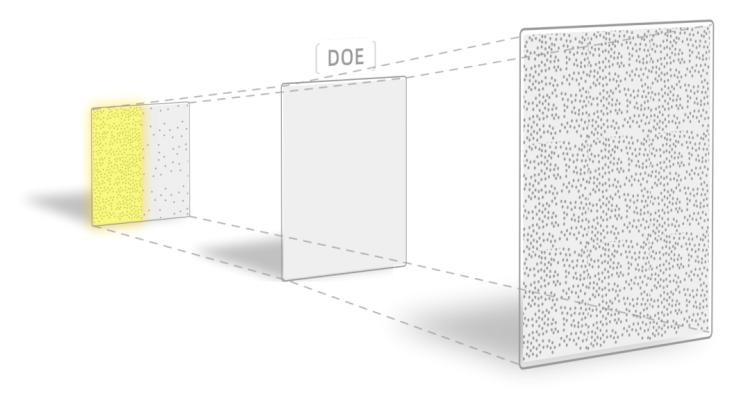
激光从 VCSEL 发射出来后,首先经过准直透镜,然后通过两块棱镜的反射,到达另一个关键组件——光学衍射元件(DOE)。DOE 的作用,是把一个图案复制成很多份,然后呈扇形射出。
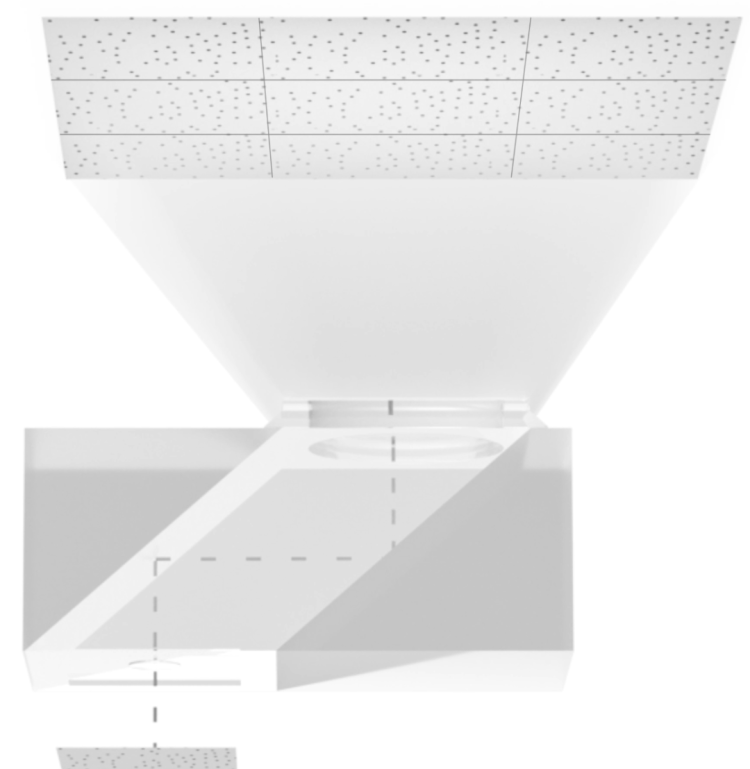
通常情况下,DOE 应该是一个无源器件。但是 iPhone 上的 DOE 上面是有电极的。这是因为苹果做了一个检测机制:它把 DOE 和基板当成了一个电容,如果 DOE 的表面发生破损,引起了电容的变化,苹果会直接把整个 Face ID 模块禁用。这是因为如果 DOE 失效,激光没有被正确的分散开来,那激光的能量,就可能会超出安全范围,从而对人眼造成伤害。

这就是为什么 Face ID 是 iPhone 非常容易损坏的一个部件。闲鱼的二手 iPhone,带面容和不带面容,就是两个价格。如果你在手机店看过维修师傅修手机,你会发现有的师傅拆开手机后,会马上拿一张胶带,把 Face ID 贴上,怕碰坏了,就是这个原因。
硬件的部分,重点我们都说完了。在得到了这样一个漂亮的点阵图案之后,我们的下一步,就是脸部的三维重建,和比对了。
三角测量
结构光的原理,是通过视差,来判断物体的深度。
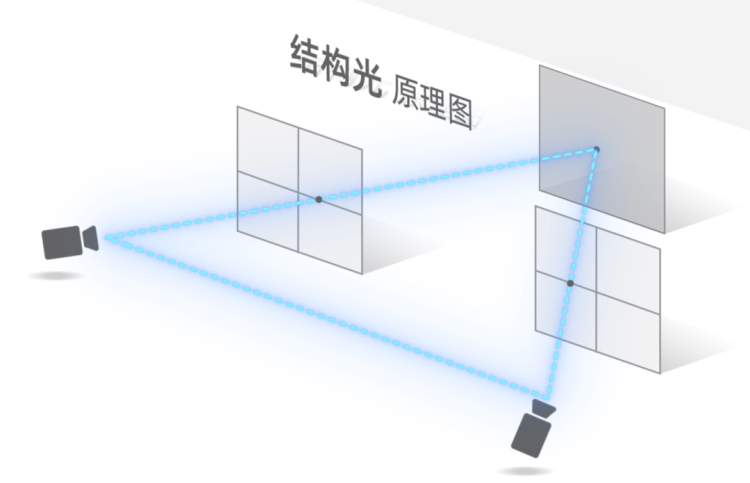
就像我们拿一根激光笔,把一个光点,投射在一块白板上。如果从激光笔的右边观察,当白板向前移动的时候,这个光斑会朝视线的左边偏移。木板向后移动的时候,光斑则偏向右边。偏移得越远,说明白板的深度越深。

你可能会注意到,要从画面里看出光点的偏移,摄像机和激光笔之间,必须保持一定的距离,如果距离太短,光点的偏移量就会很低,摄像机就很难捕捉它的变化,导致精度下降。而摄像机和激光笔之间的距离,就被称为“基线”。

从 iPhone X 第一次引入面容解锁开始,在长长的刘海里,红外摄像头和点阵投射器,就一直占据着最左边和最右边的位置,因为它要保证基线的长度,以满足识别的准确性。

但是在今年的 iPhone 13 上,红外和点阵第一次变成了邻居,基线长度从之前的 27 毫米,缩短到了 6 毫米。对于 iPhone 来说,这道题的难度,可谓直线上升。

可是,我们实测却发现,iPhone 13 的解锁体验,和前代相比,无论是解锁角度、距离、还是速度,都完全保持了一致水准。那么,它到底做了什么,来抹平基线缩短所带来的性能损失呢?
“无间道”
为了搞明白这件事,我们只能继续找两台手机的不同,希望能发现一些线索。
我们用红外相机拍摄了 iPhone 12、iPhone 13 点阵投影的过程发现,两台手机在投射的图案、投射流程上,都有所区别。
iPhone 13 在投射点阵的时候,会以伪随机的形式,加入一些空帧,比如亮一帧、停一帧,再亮一帧;或者先空两帧,再亮一帧。每次解锁,点阵亮起的时间间隔,都不一样。
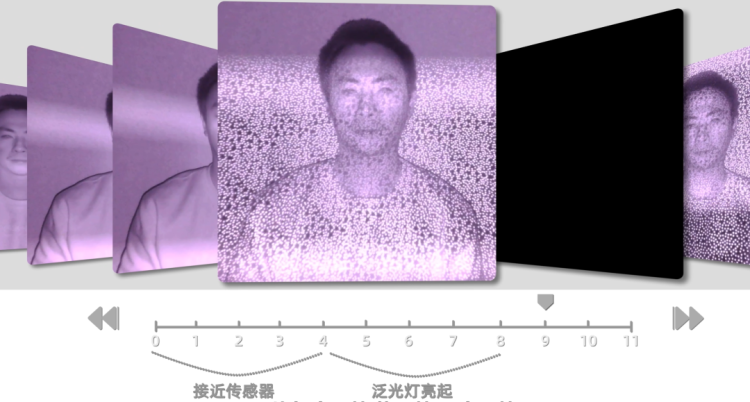
我在苹果的一份专利里,找到了这个做法的用意——增加安全性。
点阵投影仪发信,摄像头收信,这就像是一个特工在和总部联络:我们相约,在星期一、星期三、和星期五,分别给你三份情报。那如果总部在星期二收到了一份情报,哪怕情报信息完全正确,伪造得天衣无缝,但只要时间对不上,那它就是假的。

因为每次交接的时间,都是伪随机的,具体哪一天来交接,只有特工,和总部,两个人知道。这就可以防止有心人士,拿伪造的红外图来欺骗系统。
除了投射的时隙不同之外,两台手机投射的图案,也不一样。iPhone 13,每次投射的点阵密度,都是相同的。而 iPhone 12,则有几套不同的图案,有时候疏一点,有时候密一点。这一点,从 iPhone 12 的VCSEL上,也能看得出来。
整块 VCSEL 一共分成了 4 块区域,4 块区域用了不同的引脚,可以独立控制通断。

也就是说,手机通过 4 块区域的不同组合,理论上,最多可以投出 15 种不同的图案。用这 15 种图案,再配合上伪随机的发报时隙规则,就可以做出更复杂的编码,来防止欺骗。
但是!这还不是全部。
妥协与平衡
在另一份专利里,我们又找到了这四块区域的另一个用途。
我们知道,结构光是依靠图案的不相关性,来进行匹配的。简单说,就是手机在投射出一个个的斑点之后,它要知道这些斑点,对应的是参考图中的哪里。如果张冠李戴,就会出现误匹配,深度当然也就解不出来了。

所以,一片理想的散斑图案,应该是具有高度“不相关性”的——每一个小区域,在整张图里,最好都是唯一的。但是对于手机来说,因为每一个光点,长得都一模一样,完全没有特征,所以手机必须把图像分割成一个个的“窗口”,再以“窗口”为单位,去整张图里找匹配。

而这个时候,窗口怎么画,画多大,就很重要了。对于手机来说,点阵越稀疏,窗口画得越大,它的计算压力就越小,识别起来就越快。但是,也正是因为窗口大了,所以分辨率上不去,只能做低精度的扫描。
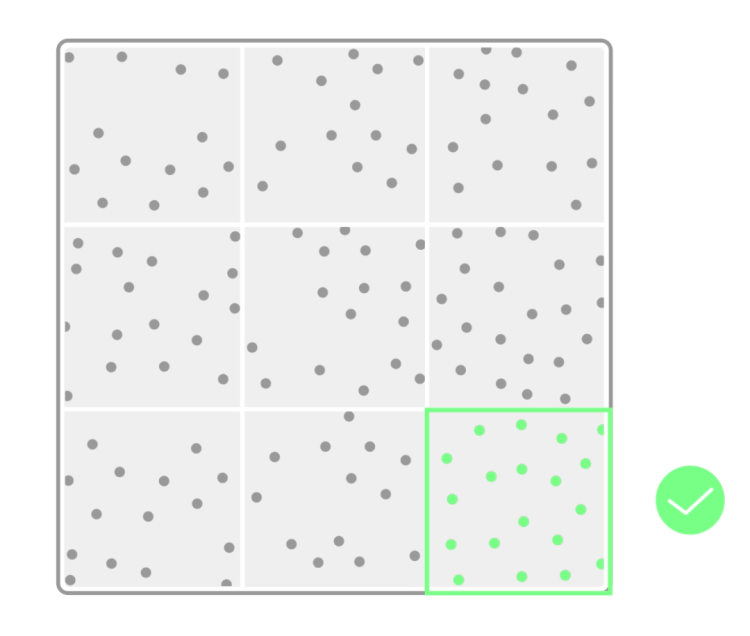
而要得到更高的精度,我们需要让点阵更加密集,把窗口画小,但是在匹配的时候,因为每个窗口都要经过更多次的迭代,以寻找最佳配对,所以速度,当然就要慢一些。

所以在算力有限的前提下(记住这个前提!),苹果采用多个分区、疏、密结合的方案,就是要在速度,和精度之间找一个平衡。
比如它可以先扫一遍稀疏的图案,先分出大概的区块,然后再在重点区域用精细图案做精细匹配。再比如人脸解锁这个场景,精度是第一优先级,所以疏加密,全部图案一起上。但是用前摄拍视频的时候,手机只需要知道一个大概的景深信息,用来做虚化就可以了,那它就可以偷偷懒,只用稀疏的点阵。否则,以它的算力,是无法支持每秒 60 帧的运算的。

那到了 iPhone 13 这边,可以看到,苹果取消了中间的分界线,用同一张图案,来应对所有的场景。哪怕是前摄算个主体深度,iPhone 13 也是把所有的点全部堆进去,火力全开地计算。
这也就说明,得益于 SoC 更强的算力,苹果今年很有可能是跳过了用稀疏图案,进行低精度扫描的这一步,而是直接用密集图案做高精度扫描。
从这些现象,我们可以推测,对于苹果来说,200 毫秒的解锁时间,和 100 万分之一的错误率,可能是他们内部,划给 Face ID 的一条红线。只要这两个关键性能达标,工程师就可以做各种 trade off。
所以,我们的推论是,今年 Face ID 形态的变化,一方面,是得益于封装技术的进步,让 VCSEL 和泛光合二为一,省掉了一个传感器的空间;另一方面,是得益于 SoC 算力的提升,让手机可以容忍更短的基线。
因为计算变快了,所以手机可以实现在任何场景下的高帧率、高精度扫描,可以忍受更短基线带来的信噪比降低,但同时,还把人脸解锁的速度,维持在 200 毫秒,这一根红线之内。
当然,在苹果所有的公开资料里,我们并没有找到任何具体地讲解 Face ID 算法、和识别流程的内容,这也让我们的推测,也只能止步于推测。
但在综合了所有的已知信息之后,这,已经是我们认为,最接近事实的可能了。




















热门评论
>>共有0条评论,显示0条