智源AI研究院回应大模型论文学术争议
“我们已经注意到对《A Roadmap for Big Model》一文的质疑,正在对相关情况进行核实,智源研究院鼓励学术创新和学术交流,对学术不端零容忍,有关进展将尽快通报。”4月13日,北京智源人工智能研究院回复谷歌大脑(Google Brain)的著名科学家Nicholas Carlini对一项中外合作大型学术论文涉嫌剽窃的指控。
此前4月8日,Nicholas Carlini公开撰文,指控一篇于今年3月26日刊登在论文预印网站Arxiv的论文《关于“大模型”的路线图》(“A Roadmap for Big Model”)一文涉嫌严重抄袭。
该文是前不久国内外多家高校和企业共同完成的长达200页的学术综述论文,有多达100名作者,分别来自于清华大学、北京大学等国内高校,哥伦比亚大学、蒙特利尔大学等国外高校,字节跳动、华为、京东、腾讯等企业以及中科院和北京智源等机构。

Nicholas Carlini在文章《机器学习研究中的一个抄袭案例》(“A Case of Plagarism in Machine Learning Research”)中则详细列举了该论文存在大段抄袭其他论文的嫌疑,证据是大规模的文本重叠,疑似被剽窃的论文也包括他自己的论文“Deduplicating Training Data Makes Language Models Better”。
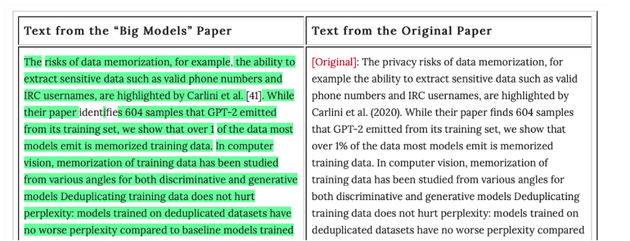
Nicholas Carlini在文章中解释,他们是在阅读这篇论文时发现很多语句都非常的熟悉,然后通过使用论文查重工具发现了更多的证据,进而准确定位《关于“大模型”的路线图》论文中和已有论文中存在剽窃嫌疑的文本内容。
澎湃记者发现,这篇被质疑的论文目前已经被其发表网站Arxiv在页面上备注了该文和Nicholas Carlini的论文有“文本重叠”(text overlap)。

此前3月31日,北京智源社区撰文以《如何炼大模型?200页pdf100+位作者19家单位!北京智源清华唐杰等发布》介绍该篇论文:
“随着以深度学习为代表的AI技术的快速发展,智能模型的训练应用模式逐渐由‘大炼模型’向‘炼大模型’转变。大模型研究在近年来发展迅速,模型的参数量以惊人的速度扩展。北京智源人工智能研究院最近发布的《A Roadmap for Big Model》由悟道大模型研究项目负责人,智源学术副院长,清华大学计算机系教授唐杰牵头,从大模型基础资源、大模型构建、大模型关键技术与大模型应用探索4个层面出发,对15个具体领域的16个相关主题进行全面介绍和探讨。非常值得关注。”
《关于“大模型”的路线图》中的研究主体“大模型”是近几年人工智能的热门关注领域。人工智能发展到今天,GPT和BERT等参数量巨大的模型被人们开发出来,他们在计算机视觉和自然语言处理等领域取得了前所未有的成就。同时,因为大模型参数量巨大,最近学术界开始将它们当作一类特别的人工智能模型进行研究。
在一篇去年发布的,由斯坦福教授李飞飞等领衔的约百名作者署名论文将此类模型称为“基础模型”(Foundation Model),这篇由清华主要参与的论文关注与此相同含义的“大模型”(Big Model)的未来研究路径。在清华的论文中,作者们介绍到“之前论文提及的'基础模型'在中文语境中也被称为‘大模型’”(“The mentioned foundation model is known as the BMs, and it is called Big Model in the Chinese context.” )。

这起“涉嫌抄袭”事件在国外社交媒体上引起热议。滑铁卢大学教授Gautam Kamath表示,对于一篇有如此多作者的文章,他很惊讶没有一个作者注意到相似之处并且去改正它。






















