小米新技术落地:能将图片中的表格转化成Excel文件
今天下午,小米创办人雷军介绍了小米自研的一套表格识别算法,该算法高效准确地将图片中的表格转化为可编辑的Excel文件,大幅提升使用体验。表格识别是指将图片中的表格结构和文字信息识别成计算机可以理解的数据格式,在办公、商务、教育等场景中有着广泛的实用价值,也一直是文档分析研究中的热点问题。
围绕这个问题,小米研发了一套表格识别算法,该算法高效准确地提取图片中的表格,转化为可编辑的Excel 文件。目前算法已经成功落地于小米10S系列、MIX Fold 2等旗舰机型,大家可以从相册-更多-表格识别,或者扫一扫进入体验。

表格检测算法
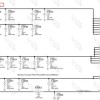
小米表示,表格检测算法主要是从图片中准确的提取表格区域,并对表格进行矫正,得到平整的表格图片以便下一步的表格识别;
表格识别算法主要是从图片中提取表格结构和表格文字内容,然后将这些信息有效的结合在一起,输出可编辑的Excel表格。
表格检测有以下难点:一方面是手机上的算法和内存有限,另一方面是对表格检测结果要求非常高,表格周围往往包含其他文字,如果检测结果不准,会对后面的识别结果造成负面影响。
小米的表格检测算法会同时检测到表格区域和表格的四个角点,通过透视变换和我们自研的抗扭曲算法得到只有表格区域的平整表格,效果如图所示。

由于算法运行在手机端,需要保证运行速度和模型大小,小米采用了一个非常轻便的一阶段检测框架,backbone采用shuffleNetV2;
在检测出表格框的同时,回归出关键点信息,便于表格的透视矫正,并用Wing loss代替L1 loss让关键点回归更加准确;
数据方面,用算法低成本地从公开数据中挖掘大量表格检测数据,显著性地提高表格检测效果。最终模型大小为1M左右,顺畅地运行在小米手机上。

表格识别算法
表格识别算法在服务端运行,主要包含的模块有:文本检测、文本识别、表格结构预测、单元格匹配、对齐算法、Excel导出。
目前主流的方法是将表格用HTML的超文本表示,然后对HTML进行编码,预测HTML序列和对应的坐标信息。
该方法在开源数据集上取得了不错的效果,中国平安科技和百度也采用了这种方案,但是HTML 的标签过多导致表格结构识别容易出错。
针对该方法的不足,我们对表格采用全新的编码方式,仅用四个标签就能表示任意结构的表格,极大地提高了表格结构识别准确率。
表格识别在部署过程中,采用Fastertransformer推理框架进行加速,官方称小米的推理速度提升了大约20倍,明显改善用户体验。
总结
该算法能高效方便地从图片中提取表格,极大地提高办公效率。小米表示,工程师们将持续提升小米手机中文档类图片的识别体验。

















热门评论
>>共有0条评论,显示0条