谷歌又闹大乌龙 Jeff Dean参与的新模型竟搞错Hinton生日
最近,谷歌研究员发布了关于指令微调的最新工作!然而却宣传图中出现了可笑的乌龙。几个小时之前,谷歌大脑的研究员们非常开心地晒出了自己最新的研究成果:“我们新开源的语言模型Flan-T5,在对1,800多种语言的任务进行指令微调后,显著提高了prompt和多步推理的能力。”
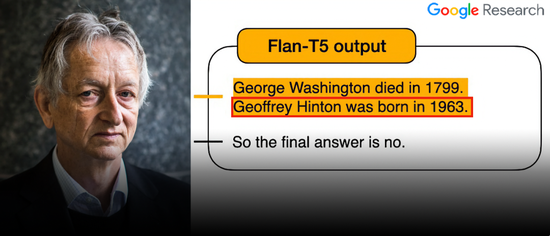
然而,就在这张精心制作的“宣传图”上,竟藏着一个让人哭笑不得的bug!

请注意看Geoffrey Hinton的出生日期:

但实际上,Hinton出生于1947年……

虽然没有必然联系,但是Google自己的模型,竟然会把自家大佬的生日搞错?
马库斯同志看完直接就惊了:你们Google,没人负责审核的吗……

理论上,这篇拥有31位作者,外加Jeff Dean这种大佬参与的论文,不应该发生这种“低级错误”才对啊。

“复制”的时候“打错了”而已!
很快,论文的共同一作就在马库斯的推文下面进行了回复:“我们都知道,模型的输出并不总是符合事实。我们正在进行负责任的AI评估,一旦有了结果,我们将立即更新论文。”

没过多久,这位作者删除了上面那条推文,并更新留言称:“这只是在把模型的输出复制到Twitter上时,『打错了』而已。”

对此,有网友调侃道:“不好意思,你能不能给我翻译翻译,什么叫『复制』来着?”

当然,在查看原文之后可以发现,“图1”所示的生日,确实没错。
至于在宣传图中是如何从“1947”变成“1963”的,大概只有做图的那位朋友自己知道了。

随后,马库斯也删除了自己的这条推文。
世界重归平静,就像什么也没有发生一样。
只留下Google研究员自己推文下面的这条在风中飘摇——

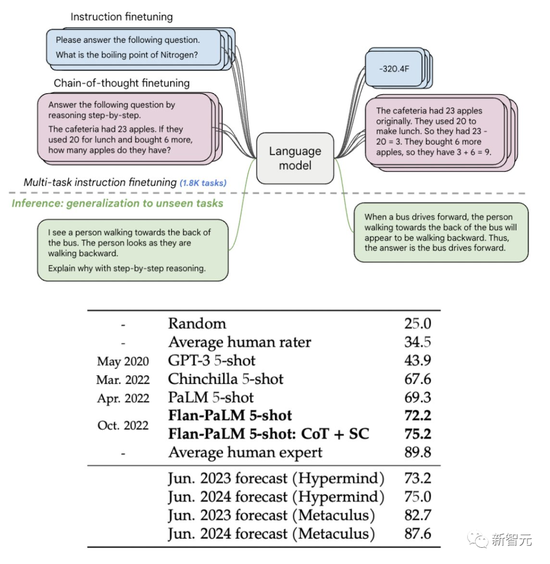
扩展指令微调语言模型
既然误会解除了,我们就让话题重新回到论文本身上来吧。
去年,Google推出了一个参数量只有1370亿的微调语言网络FLAN(fine-tuned language net)。

https://arxiv.org/abs/2109.01652
FLAN是Base LM的指令调优(instruction-tuned)版本。指令调优管道混合了所有数据集,并从每个数据集中随机抽取样本。
研究人员称,这种指令调节(instruction tuning)通过教模型如何执行指令描述的任务来提高模型处理和理解自然语言的能力。
结果显示,在许多有难度的基准测试中,FLAN的性能都大幅超过了GPT-3。
这次,Google将语言模型进行拓展之后,成功刷新了不少基准测试的SOTA。
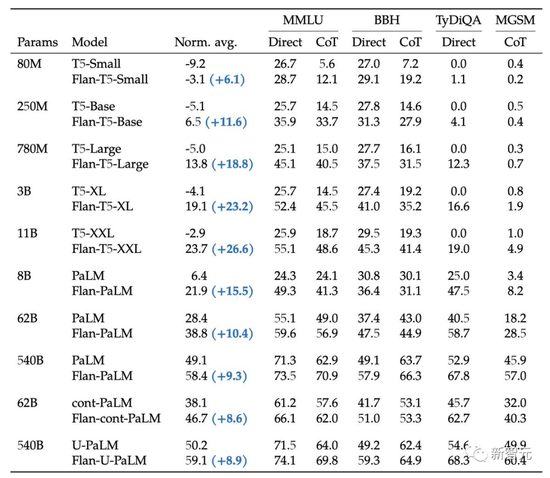
比如,在1.8K任务上进行指令微调的Flan-PaLM 540B,性能明显优于标准的PALM 540B(平均 + 9.4%),并且在5-shot的MMLU上,Flan-PaLM也实现了75.2%的准确率。
此外,作者还在论文中公开发布Flan-T5检查点。即便是与更大的模型(如PaLM 62B)相比,Flan-T5也能实现强大的小样本性能。

论文地址:https://arxiv.org/abs/2210.11416
总结来说,作者通过以下三种方式扩展了指令微调:
扩展到540B模型
扩展到1.8K的微调任务
在思维链(CoT)数据上进行微调
作者发现具有上述方面的指令微调显著提高了各种模型类(PaLM、T5、U-PaLM)、prompt设置(zero-shot、few-shot、CoT)和评估基准(MMLU、BBH、 TyDiQA、MGSM、开放式生成)。
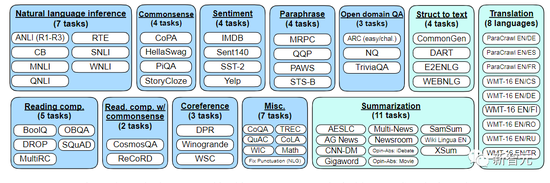
这次的微调数据包括473个数据集、146个任务类别和1,836个总任务。
作者是通过结合之前工作中的四种混合(Muffin、T0-SF、NIV2 和 CoT),缩放(scale)成了下图中的1836个微调任务。
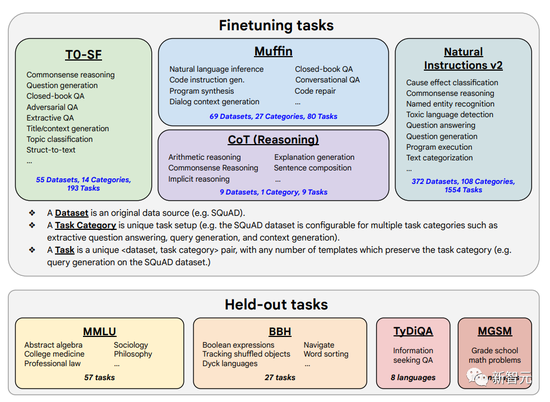
在研究中,微调数据格式如下图这样组合。研究者在有样本/无样本、有思想链/无思想链的情况下进行了微调。要注意的是,其中只有九个思维链(CoT)数据集使用CoT格式。
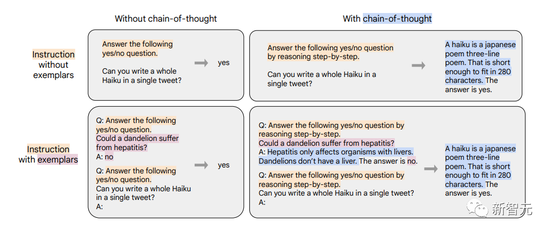
第四种微调数据的混合涉及CoT注释,作者用它来探索CoT注释的微调是否可以提高看不见的推理任务的性能。
作者从先前的工作中创建了9个数据集的新混合,然后由人类评估者手动为训练语料库编写CoT注释。这9个数据集包括算数推理、多跳推理(multi-hop reasoning)和自然语言推理等。
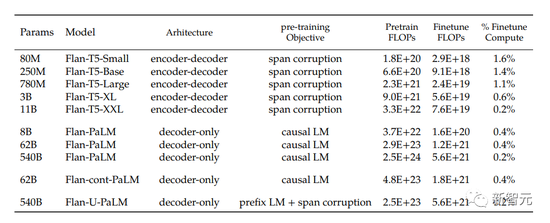
作者在广泛的模型中应用了指令微调,包括T5、PaLM和U-PaLM。对于每个模型,作者都采用了相同的训练过程,使用恒定的学习率,并使用Adafactor优化器进行了微调。
从下表中可以看出,用于微调的计算量仅占训练计算的一小部分。
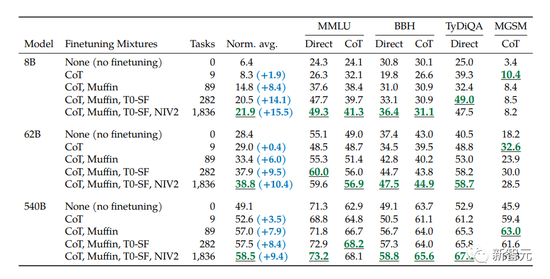
作者根据模型的大小和微调任务的数量,在保留任务的性能上检测了缩放的影响。
作者从对三种大小的PaLM模型(8B/62B/540B)进行实验,从任务最少的混合开始,一次添加任务混合,然后再到任务最多的混合(CoT、Muffin、T0-SF 和 NIV2)。
作者发现,扩展指令微调后,模型大小和任务数量的扩展都会大大改善性能。
是的,继续扩展指令微调就是最关键的要点!
不过,在282个任务之后,收益开始略微变小。
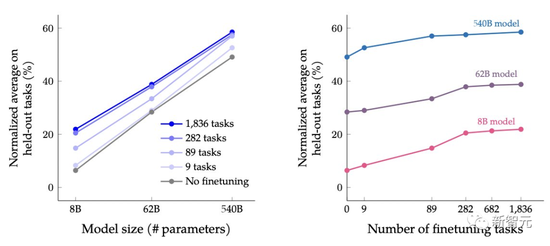
从下表中可以看出,对于三种大小的模型,多任务指令微调后,相比没有微调时,性能有很大的提高,性能增益范围从9.4%到15.5%。
其次,增加微调数量可以提高性能,尽管大部分的改进来自282个任务。
最后,将模型规模增加一个数量级(8B→62B或62B→540B)会显著提高微调和非微调模型的性能。
为什么282个任务之后增益就变小了呢?有两种解释。
一是附加任务不够多样化,因此没有为模型提供新知识。
二是多任务指令微调的大部分收益,是因为模型学习更好地表达了它在预训练中已经知道的知识,而282个以上的任务并没有太大的帮助。
另外,作者还探讨了在指令微调混合中包含思想链(CoT)数据的效果。
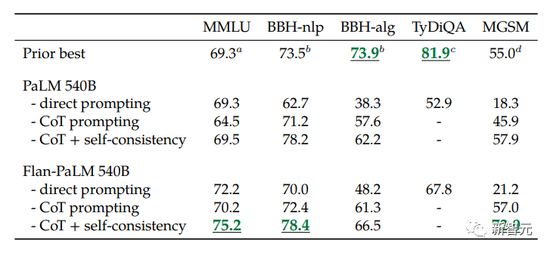
可以看出,Flan-PaLM在所有评估基准上都优于PaLM。
不过令人惊讶的是,以前的指令微调方法(如FLAN,T0)显著降低了non-CoT的性能。
对此的解决方案是,只需在微调混合中添加9个CoT数据集,就可以在所有评估中获得更好的性能。
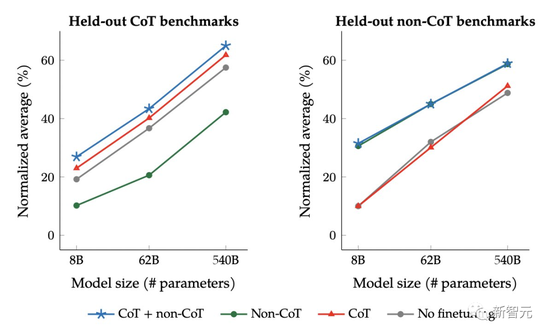
虽然思维链(Chain-of-Thought)prompting通常非常有效,但只能编写少量样本,而且零样本CoT并不总是有效果。
而Google研究者的CoT微调显著提高了零样本推理能力,比如常识推理。
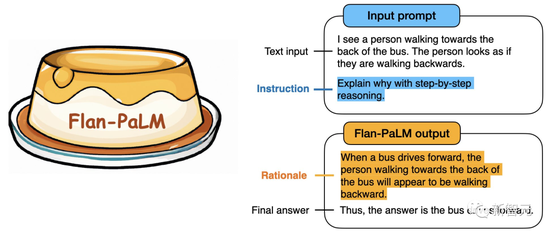
为了展示方法的通用性,研究人员训练了T5、PaLM和U-PaLM。其中参数量的覆盖范围也非常广,从8000万到5400亿。
结果证明,所有这些模型都得到了显著提升。
在以往,开箱即用的预训练语言模型可用性通常都很差,比如对输入的prompt没有反应。
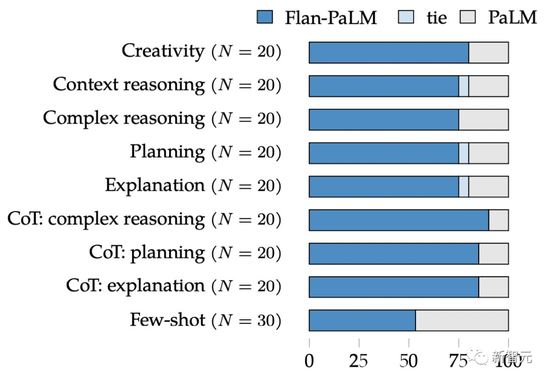
Google的研究者要求人类评估者来评估开放式生成问题的“模型可用性”。
结果显示,Flan-PaLM 的可用性比PaLM基础模型要高79%。
此外,指令微调还补充了其他的模型适应技术,比如UL2R。
同样的,Flan-U-PaLM取得了很多优秀的结果。

论文地址:https://arxiv.org/abs/2210.11399
Google的另一起“翻车”事件
可以说,刚刚发生的这个剧情,既视感相当强了!
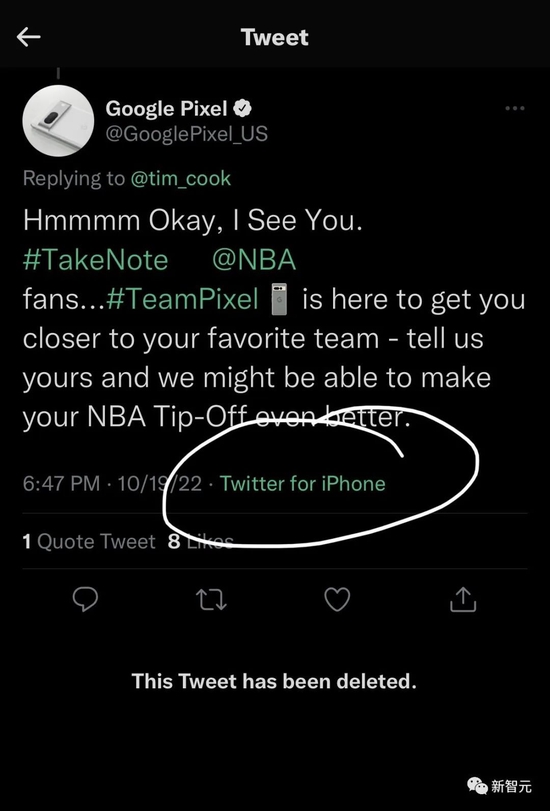
没错,就在10月19日,当GooglePixel的官方账号试图挖苦苹果CEO库克时,被网友抓包:是用iPhone发的推文……
显然,这种事情早已不是第一次了。
2013年,T-Mobile的CEO就在Twitter上对三星Note 3赞不绝口,但用的是iPhone。
同样是2013年,黑莓的创意总监Alicia Keys在发布会上说,她已经抛弃了自己之前的iPhone,换了黑莓Z10。随后,就被发现用iPhone发推,甚至在被抓到后发推狡辩说是因为自己被黑了。
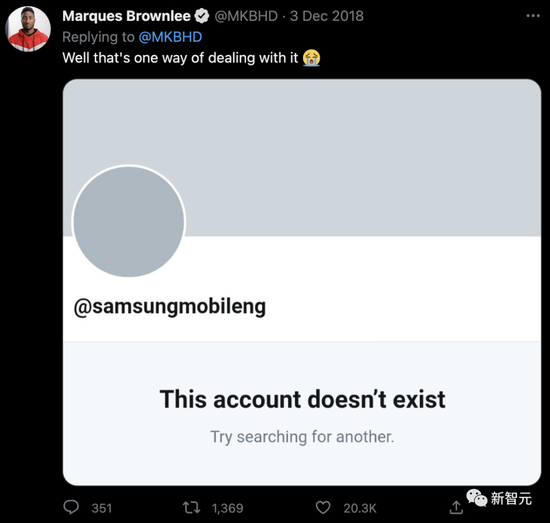
三星,也不例外:
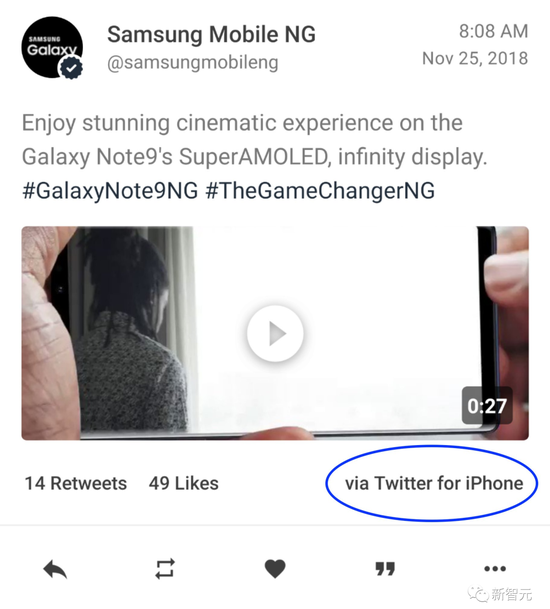
而且,相比于Google的这次删推,三星当时做得更加决绝:直接删号!
看来,营销课程有必要加上这样的一条戒律了:如果你要推广一个产品,请不要用竞争对手的产品来做。
这并不是一个难以传授的信息,甚至还可以做得直白:在推销其他产品时,手里请不要拿着iPhone。





















