为什么“28nm光刻机”多重曝光也做不到7nm?
今天讨论的主题是:28nm光刻机为什么不能通过多曝工艺实现14nm,甚至7nm的曝光工艺?在了解这个复杂的半导体知识之前,还得先学习前置的知识点。今天知识点内容包括:第一、所谓28nm光刻机是什么?如何定义?第二,决定光刻机的最小精度有哪些因素?什么叫套刻精度?第三、晶体管的实际参数和定义;第四,多曝工艺/SAQP四曝工艺的详细图解。
字数原因分两段,今天讲第一和第二点,第三第四下一次。
全文5100多字。
一、28nm光刻机是如何定义的
首先业内并没有28光刻机这样的叫法,这个说法只存在民间,但是既然是科普,那还得按普通人的视角来解释。
所以所谓的28光刻机,应该到底怎么来定义?
按一般意义上的理解,最小精度能满足28nm线宽的显然就能算28nm光刻机。
那么问题又来了,28nm的实际线宽是多少呢?
芯片的内部结构其实类似高楼大厦,最底下的晶体管间距最小,上面的金属互联层间距相对较大,所谓的28nm光刻机应该是指满足M0/M1最底层的小晶体管特征尺寸的光刻机。
28nm的实际特征尺寸是多大呢?
28nm有两版经典的工艺分别是28HKMG(高K金属栅极)和28Poly(多晶硅氮氧栅极),实际上不仅仅是这2个版本,台积电当年在28nm平台上有延伸出LP,HPM,HPC,HPC+等多个版本,主要是为了针对不同的客户需求,有些客户追求频率和性能,有些客户则追求更低功耗比,因此尽管都是28nm工艺,但是在各个工艺版本略微有区别。
之所以要搞这么多工艺版本,主要原因是这些工艺的变化,会带来设计规则的变化。
更加灵活的设计规则一方面是能减少并改善光刻步骤,第二是不同的工艺能够明显改进栅极间距,目的是改善性能或者漏电。
根据业内大佬的介绍,28HPC/HPC+和28LP/HP/HPL/HPM略有区别,栅极长度分别是HPC版本的40nm/35nm/30nm和LP版本的38nm/35nm/31nm。
从这点上大家就发现了,28nm工艺的实际栅极长度,并不是28nm,最大的有40nm,而最小的则是31nm,实际上一共有6种规格,甚至22nm都能算28nm的一个变种。
从40-28nm工艺开始,工艺节点的标称和实际栅极长度已经不是一一对应,而是相对等效关系的原因。
因此要满足28nm工艺,在不考虑其他工艺因素的情况下,光刻机的极限分辨率应该至少能满足40nm最小曝光线宽,但由于40nm的不是主力量产制程,实际情况应该至少满足CD=35nm左右的才是主力制程光刻机,也就是普通人通常意义上理解的28nm光刻机。
我查阅了ASML光刻机的各个型号的参数,从理论上讲,NXT 1950的精度就可以试试看,咨询了河哥之后也确实得到了肯定的答案,国外FAB研发工程师们最早就是尝试使用1950进行28nm的工艺研发。
但是由于1950问题比较多,很快就被放弃,而且随着工艺演进,国外FAB的28量产主力光刻机变成NXT 1960B和NXT 1970C。
其中1970C最好用,但是国内情况不一样,国内当时28nm进度落后国外先进水平大约4-5年,等真的要上量的时候,1970已经没了,所以国内的28nm量产版本其实用的是NXT 1980D,这里仅做实际情况的说明。
实际上1980去做28nm工艺相当于大炮打蚊子,因为1980比1970贵好多,但是没办法,没有旧的大炮,只能上新的大炮。
因此结合实际情况,到这里我们可以做出一个结论:所谓的28nm光刻机实际应该特指NXT 1970Ci这个型号。
最后插入两个小故事,第一、是某位大佬说HKMG工艺是Intel把全世界带到坑里,走了很多歪路,原因据说这个HK是铝。
第二,从上面的细节各位也可以看到,哪怕同一个公司,同一个工艺平台,不同版本的工艺,设计规则也是不同的。
也就是说,如果今天有个芯片设计公司想要换掉原来的流片工艺,这等于后端设计和仿真工作几乎全部推倒重来,成本是非常高昂的,越是高端的换工艺成本就越高。
IC设计的大公司有钱无所谓,小公司真的要好好思考一下,要不要换厂,要不要换工艺这个问题,不是说话就换的。
所以不要觉得设计公司换个FAB厂流片是件很简单的事,这不是你下楼买菜,这家不好就换一家,这里面可复杂了,半导体领域就从来没有简单的事,不要用日常思维去理解半导体里面的事,实际上根本不是一个概念。
以后有空敲一篇吐槽一下网上哪个项XX啥都不懂的专家,天天喊台积电南京厂扩产会抢光国内FAB生意,卧槽,你以为换一家FAB流片是说换就换的?生意说抢就抢?
第二,决定光刻机的最小精度有哪些因素?什么叫套刻精度?
光刻机是一个非常庞大的光学系统,任何内部或者外部微小的差错都会影响最终效果,光的世界里,错了就是错了,有误差就是有误差。
如果从瑞利判据公式上看:CD=K1*λ/NA。显然影响最小CD的因素太多,如果抛开外部影响因素这个K1,K1代表了光刻胶的聚合度,分子量,颗粒度,感光剂,以及硅片的平整度,光的入射角度,杂质/灰尘的影响量这些因素。
那么如果是同平台,同光源波长放一起做比较,那么影响精度最主要的原因,则是在线量测精度和双工件台运动精度。
双工件台,也就是ASML的独门绝技 “TWINSCAN”平台技术,让ASML保持竞争力的最大秘诀!
插入一个ASML和尼康的小故事,我曾经叫它尼康棺材板上的三颗钉子,这是第二颗。
在《光刻巨人》那本书上也提到过,尽管当年在8英寸工艺上,ASML的PAS 5500也通过了IBM/Intel们的认证,但是实际采购上Intel基本没怎么正眼看过ASML,产线上实际大量采购的还是尼康的S-204/205。
大量采购PAS 5500光刻机,反而是台积电、三星、美光这样的代工和存储客户。
实际上在设备产能这项指标上,PAS 5500是强于S205的,为什么Intel们就不用呢?
原因很简单,因为对于垄断CPU市场的Intel而言,市场蛋糕足够大,完全可以躺赚,生产快一点还是慢一点根本无关痛痒,因此从未要求高产能。一度Intel的产能利用率只有60%,甚至晚上都不开工,慢慢悠悠丝毫不慌,因此这也是哪怕PAS 5500对比尼康的S205有产能优势,但是在前期Intel也对ASML没有兴趣的原因。
但是台积电们不一样,产能就是生命线,60%的产能利用率?晚上就停工不生产?这还不亏炸啊?
对于台积电这类晶圆代工企业而言,必须在成本、效率、产能上有优势,才能杀出这个激烈的战场,才能在竞争中站稳脚跟。
所以竞争使人进步,垄断使人慵懒,ASML使用高产能的光刻机来牢牢抓住台积电们的心,同理存储厂也是,竞争非常激烈,哪像Intel那样能躺着赚钱啊!
不过话说回来,FAB厂的工作,残酷是真的残酷,也只有东亚文化圈培养出来的隐忍,绝对服从工程师才能适应。
以前台积电流传个段子:你在台积电工作会很有钱,因为你根本没有花钱的时间。
残酷度可见一斑,什么996在FAB面前都弱爆了!
FAB的活和制度简直不是人干的!最近网上有个特许出来的哥们,在长篇连载当年他在新加坡特许的工作经理故事叫《一名芯片老兵的回顾》,各位可以去看一下,非常现实。
也许看完以后,你就知道,洒家为什么敢放出豪言“如果台积电的亚利桑州新厂做的好,我就去科罗拉多河里倒立洗头的誓言”。
因为我觉得美国这帮人,就不可能把这项工作做好。要不去湾湾那边搞人过来,但是各位都懂,想去美国的都是为了拿绿卡的润人,心怀鬼胎的那种,能做的好是真的有鬼了。
回到主题上,那ASML是如何提高产能呢?它拿出了什么样的绝活?
回顾起来,解决方案其实很简单。
图案在被曝光到晶圆前,必须对晶圆进行精准量测。量测和曝光都需要时间,为了减少每个过程需要的时间提升效率,为什么不在曝光一个晶圆的同时,对后一个晶圆开始进行量测和对准工作呢?
就这样,TWINSCAN系统诞生了

TWINSCAN系统:一个负责前期对准量测,另外一个负责曝光
TWINSCAN是第一个也是唯一一个具有双晶圆工作平台的光刻系统。
晶圆被交替地装载到TWINSCAN平台上,当一个平台上的晶圆正在曝光时,另一个晶圆被装到二号平台进行对准和测量,然后两个平台交换位置,原来在二号平台的晶圆进行曝光,而一号平台的晶圆完成卸载。然后,新的晶圆被装载,进行对准和测量工作。
这种量测对准和曝光同时进行的并行方案能极大提高光刻机单位小时内的产能,这帮助台积电们极大提高生产效率,提升最终效益。
2001年,首个采用这种革命性技术的TWINSCAN双晶圆平台系统出货了——TWINSCAN AT:750T型光刻机。
750T型光刻机使用的是波长为248nm的KrF光源系统,支持130nm工艺的生产。
不久,ASML的i线光刻机也引入了双晶圆平台,即TWINSCAN AT:400T;随后这项技术又引入到更高端的193nm的ArF光刻机上,即TWINSCAN AT:1100。因此从i线到KrF线,TWINSCAN系统跨越ASML各个平台型号的光刻机,扩大了技术范围,让所有芯片层都能在新平台上曝光。
ASML的持续创新能力为TWINSCAN平台的分辨率、套刻精度和产率提供了渐进式的改进——以平台升级、新系统升级和现场升级等不同方式,总之客户怎么舒服怎么来。
因此,双工件台的运动精度在某种程度上,是光刻机对准精度的关键中的关键!
了解双工件台的工作过程也让人感觉到不可思议,这就是科技的力量。
它们每时每刻都在高速运动,静止的状态瞬间急加速然后瞬间急停下达到的它应该停的位置上,精确度令人叹为观止。
如果按照瞬间的加速度算,已经超过火箭发射升空的速度,下一刻精准的停在位置上,不能出现任何差错,因为这种速度下任何差错都没办法弥补。
错了虽然不至于整片晶圆报废只能重来,但是这样差错多几次,赶紧跑路吧,工程师直接提着40米大刀来砍人了。
双工件台就这样加速-急停-加速-急停,不断重复这一过程,同时保持长期稳定工作的状态。
因此双工件台这套系统某种意义上讲,决定了光刻机最大产能,以及它的精度,在光刻机的世界里这个叫Overlay——套刻精度。
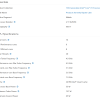
以NXT 1980Di为例,官方给的参数是OPO≤3.5nm,DCO≤1.6nm,MMO≤2.5nm。通常更差4-5
重点来了!科普一个99%都不知道的知识。
OPO是On Product Overlay的意思,产品上的套刻精度,因为芯片制造工艺有点类似盖楼的过程,相当于上次曝光和现在的对齐精度,这个精度是3nm以内。
DCO是Dedicate Chuck Overlay的缩写,相当于同一台设备自己套自己的精度,这个是1.6nm以内。
MMO是Mix-and-Match Overlay的缩写,相当于不同设备之间的套刻精度,这个可以做到小于2.5nm。
还记得多曝工艺吗?多曝工艺其中有很重要的一步,就是把原本一块掩膜板图形,拆分两块分两次曝光,以此来得到更小的图形。
显然,不管是OPO还是DCO,还是MMO,这几个参数共同决定了你能不能用多曝工艺,以及量产之后的曝光图形的一致性,和上下层最终的对准精度。
如果不管是哪个参数不够看,那么多次曝光做出来的图形,一定是歪歪扭扭,惨不忍睹,一塌糊涂,别说良率了,估计整个晶圆都得报废。
今天网上有传这个图:

图片来自群友提供,如有侵权说一声
只能说上面错误百出,什么NXE 3400 写成NXT, 什么NXT 2000早停产了,也根本没有卖进过国内,什么2050能做到5nm,不说了错太多了。
我这里直接上关老师的整理数据:

大家来找茬,看看有多少地方是错的。
回到主题。
之所以,为什么1970只能干到28nm,14nm都很吃力,7nm就更别提了,原因就在这里,1970的Overlay和1980相比,差一截啊!
Overlay的性能不够看,臣妾做不到啊!

所以双工件台,从某种程度上来讲,是除了光源、物镜系统之外,最重要的关键部件。
它的稳定性,对准精度,平均无故障运行时间直接影响着光刻机的实际工作状态,甚至影响整个FAB的工艺水平和产能。
因此一片晶圆上需要曝光多达数百个单元(Field),而先进的光刻机一个小时能曝光超过300片硅晶圆,同时保证每一次曝光量都是相同的。
假设一片12英寸晶圆上有300个单元面积需要曝光,那么相当于一天曝光2160000次,一年788400000次,双工件台以及整个设备的稳定性和效果一致性是个巨大的考验。
也许这些数字并不能让你觉得什么,但是细想之后这些数字的所代表技术含量确实令人震撼。
以前有人曾形象比喻,相当于两架高速飞行的飞机,其中一人拿出刀在另外一架飞机米粒大小的面积上刻字。
这种精密动作到令人发指的机器想要保持7*24小时稳定工作,是工程学上最困难的挑战,有无数技术高峰需要跨越。
之前国内号称某某实验室能做到几纳米,一大堆人吹捧超越ASML指日可待,要知道实验室设备刻两条直线到商用设备全天候稳定运行曝光复杂图形之间可谓是天堑之别。
我知道国内在某些环节的关键技术上有所突破,但是任重而道远,离真正成功还有很长的路要走。