最强开源大模型一夜易主:谷歌Gemma 7B碾压Llama 2 13B 重燃开源之战
一声炸雷深夜炸响,谷歌居然也开源LLM了?!这次,重磅开源的Gemma有2B和7B两种规模,并且采用了与Gemini相同的研究和技术构建。有了Gemini同源技术的加持,Gemma不仅在相同的规模下实现SOTA的性能。而且更令人印象深刻的是,还能在关键基准上越级碾压更大的模型,比如Llama 2 13B。



与此同时,谷歌还放出了16页的技术报告。

谷歌表示,Gemma这个名字源自拉丁语「gemma」,也就是「宝石」的意思,似乎是在象征着它的珍贵性。历史上,Transformers、TensorFlow、BERT、T5、JAX、AlphaFold和AlphaCode,都是谷歌为开源社区贡献的创新。

而谷歌今天在全球范围内同步推出的Gemma,必然会再一次掀起构建开源AI的热潮。同时也坐实了OpenAI「唯一ClosedAI」的名头。OpenAI最近刚因为Sora火到爆,Llame据称也要有大动作,谷歌这就又抢先一步。硅谷大厂,已经卷翻天了!Hugging Face CEO也跟帖祝贺。

还贴出了Gemma登上Hugging Face热榜的截图。
Keras作者François Chollet直言:最强开源大模型,今日易主了。
有网友已经亲自试用过,表示Gemma 7B真是速度飞快。谷歌简直是用Gemini拳打GPT-4,用Gemma脚踢Llama 2!

网友们也是看热闹不嫌事大,召唤Mistral AI和OpenAI今晚赶快来点大动作,别让谷歌真的抢了头条。(手动狗头)
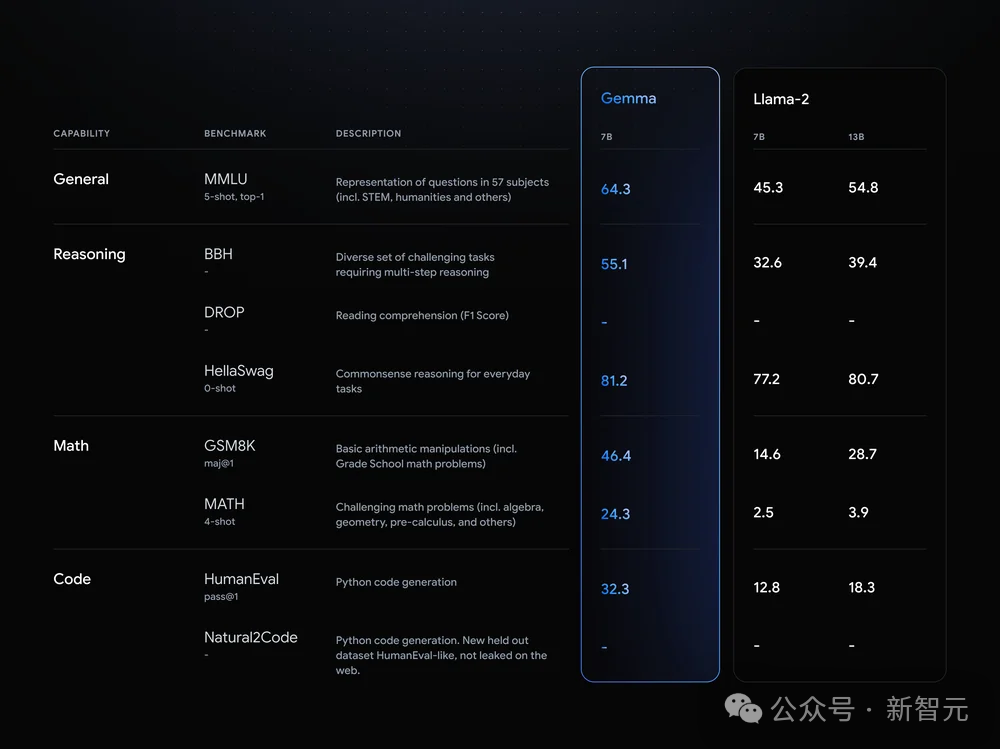
可以看到,Gemma-7B模型在涵盖一般语言理解、推理、数学和编码的8项基准测试中,性能已经超越了Llama 2 7B和13B!
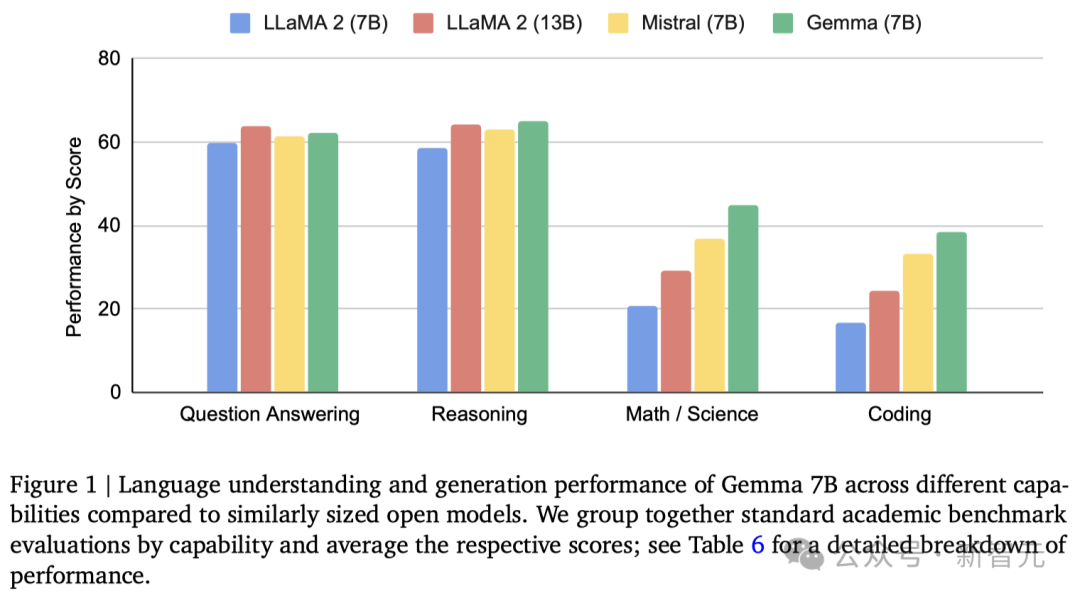
并且,它也超越了Mistral 7B模型的性能,尤其是在数学、科学和编码相关任务中。
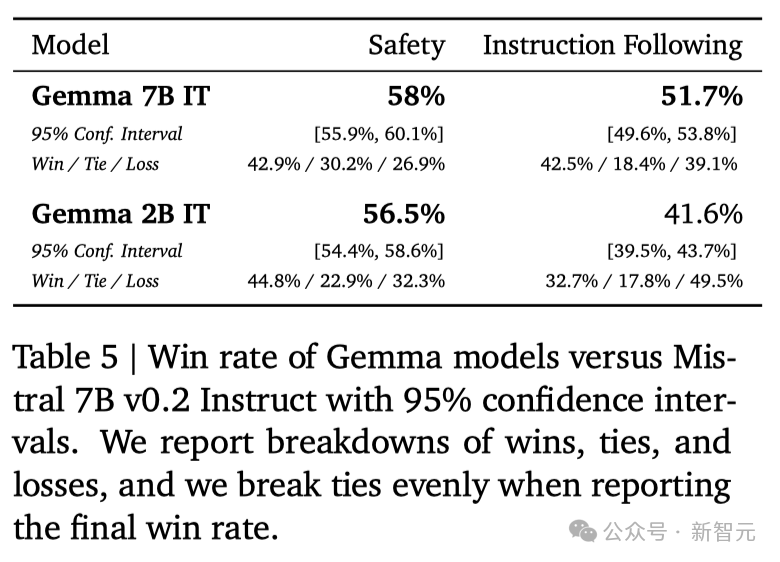
在安全性方面,经过指令微调的Gemma-2B IT和 Gemma-7B IT模型,在人类偏好评估中都超过了Mistal-7B v0.2模型。特别是Gemma-7B IT模型,它在理解和执行具体指令方面,表现得更加出色。
这次,除了模型本身,谷歌还提供了一套工具帮助开发者,确保Gemma模型负责任的使用,帮助开发者用Gemma构建更安全的AI应用程序。
- 谷歌为JAX、PyTorch和TensorFlow提供了完整的工具链,支持模型推理和监督式微调(SFT),并且完全兼容最新的Keras 3.0。- 通过预置的Colab和Kaggle notebooks,以及与Hugging Face、MaxText、NVIDIA NeMo和TensorRT-LLM等流行工具的集成,用户可以轻松开始探索Gemma。- Gemma模型既可以在个人笔记本电脑和工作站上运行,也可以在Google Cloud上部署,支持在Vertex AI和Google Kubernetes Engine (GKE) 上的简易部署。- 谷歌还对Gemma进行了跨平台优化,确保了它在NVIDIA GPU和Google Cloud TPU等多种AI硬件上的卓越性能。并且,使用条款为所有组织提供了负责任的商业使用和分发权限,不受组织规模的限制。

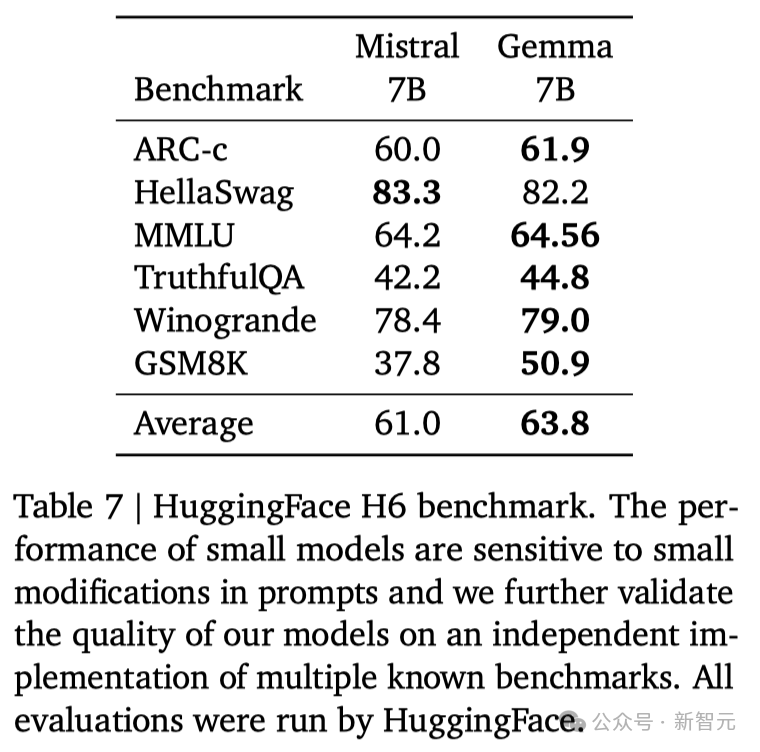
不过,Gemma并没有能够在所有的榜单中,都拿下SOTA。在官方放出的评测中,Gemma 7B在MMLU、HellaSwag、SIQA、CQA、ARC-e、HumanEval、MBPP、GSM8K、MATH和AGIEval中,成功击败了Llama 2 7B和13B模型。
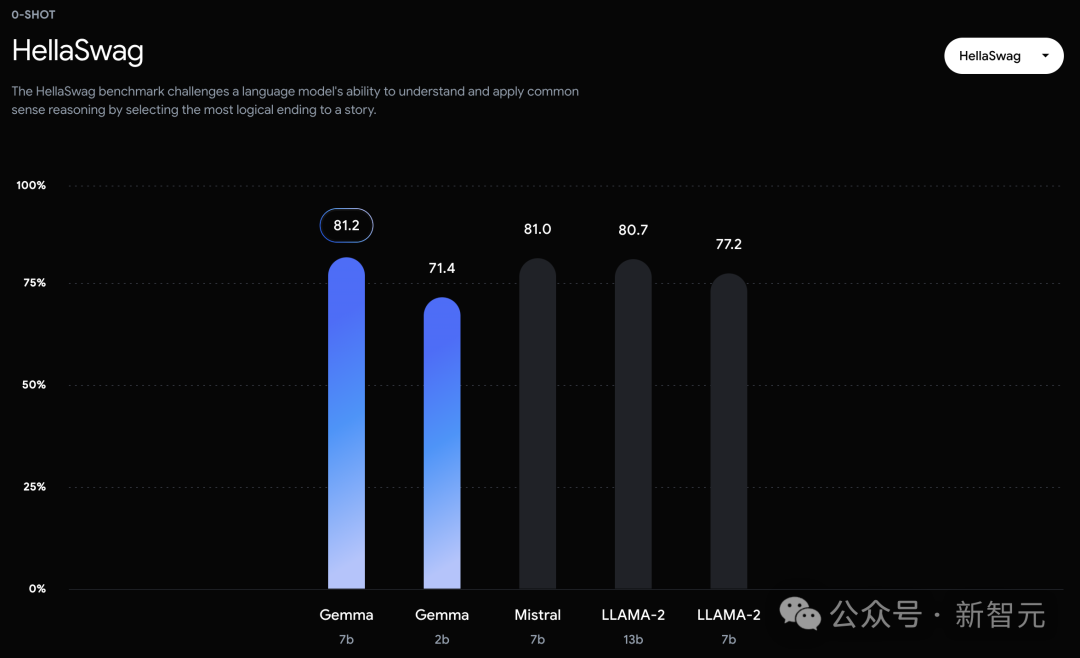
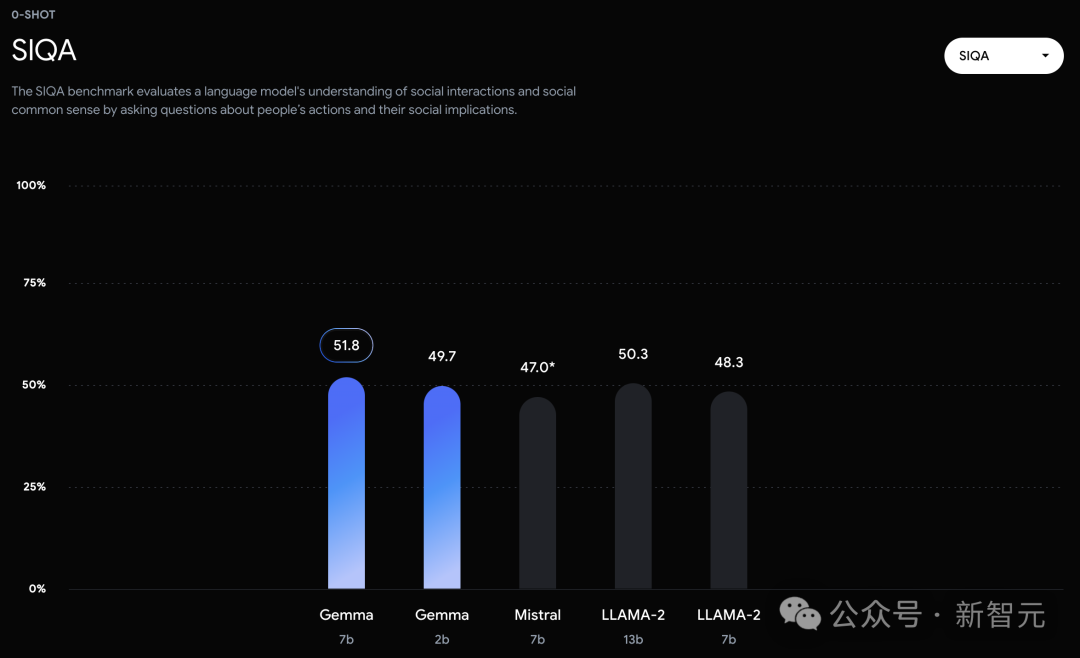
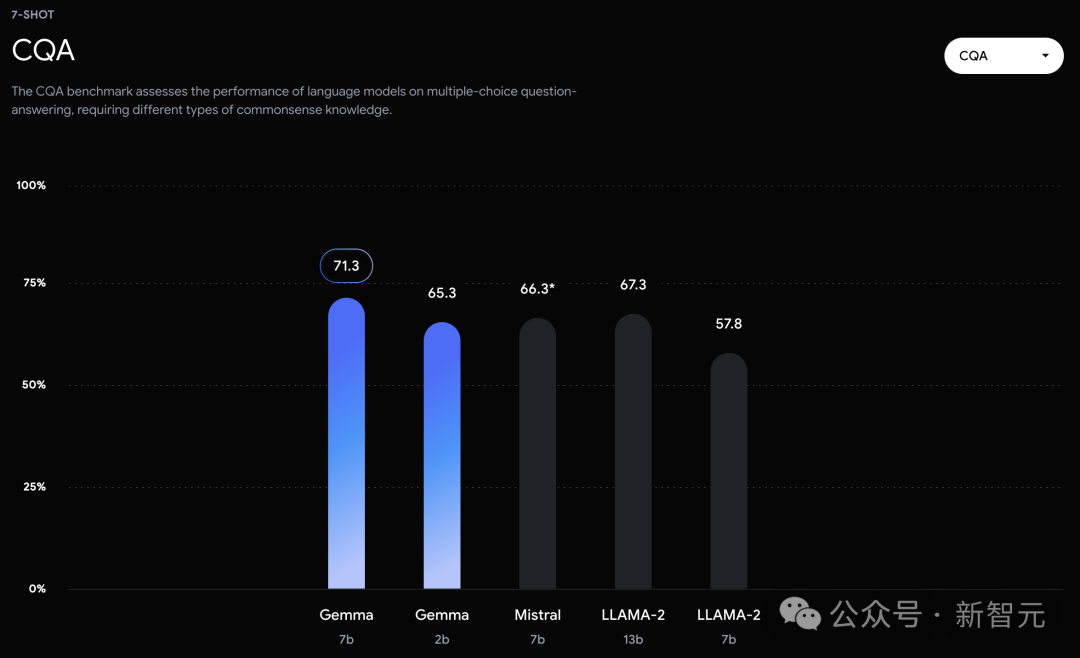
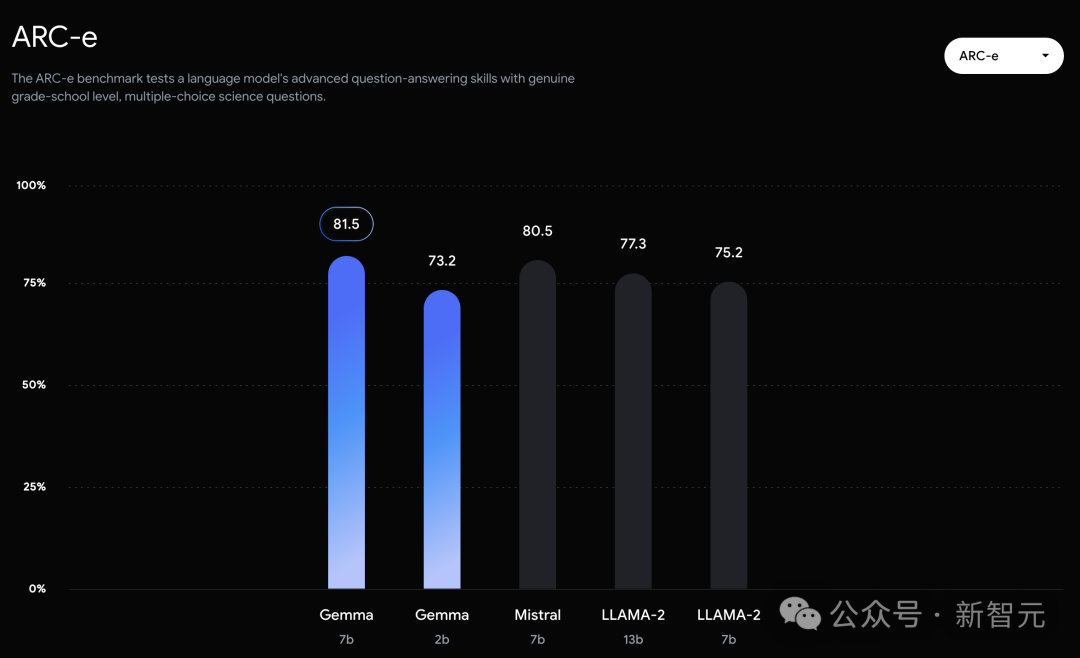
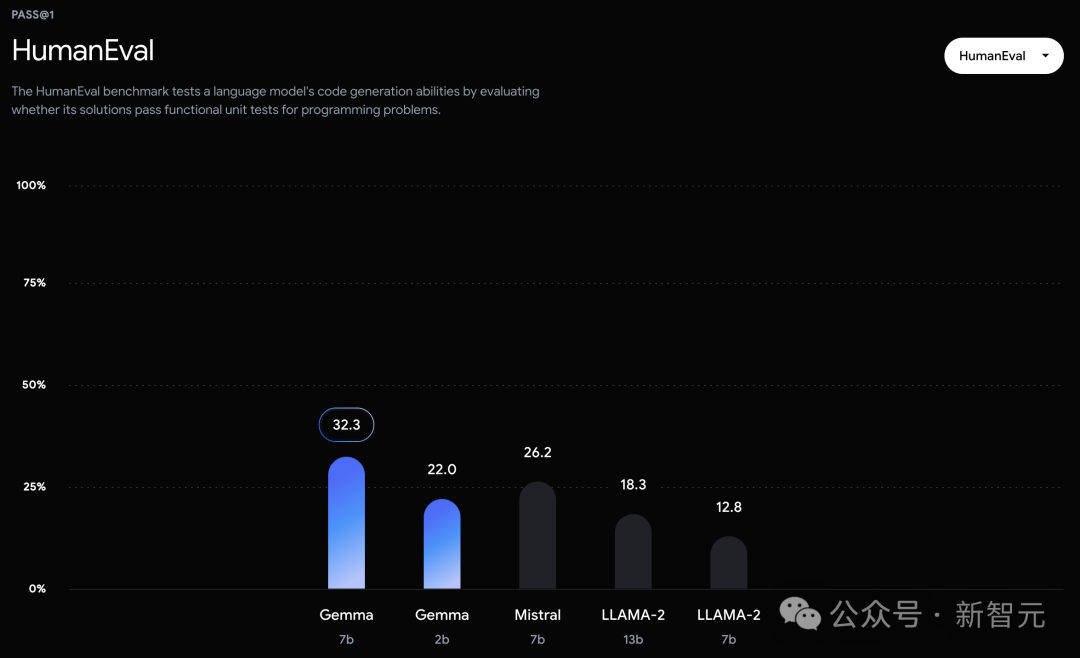
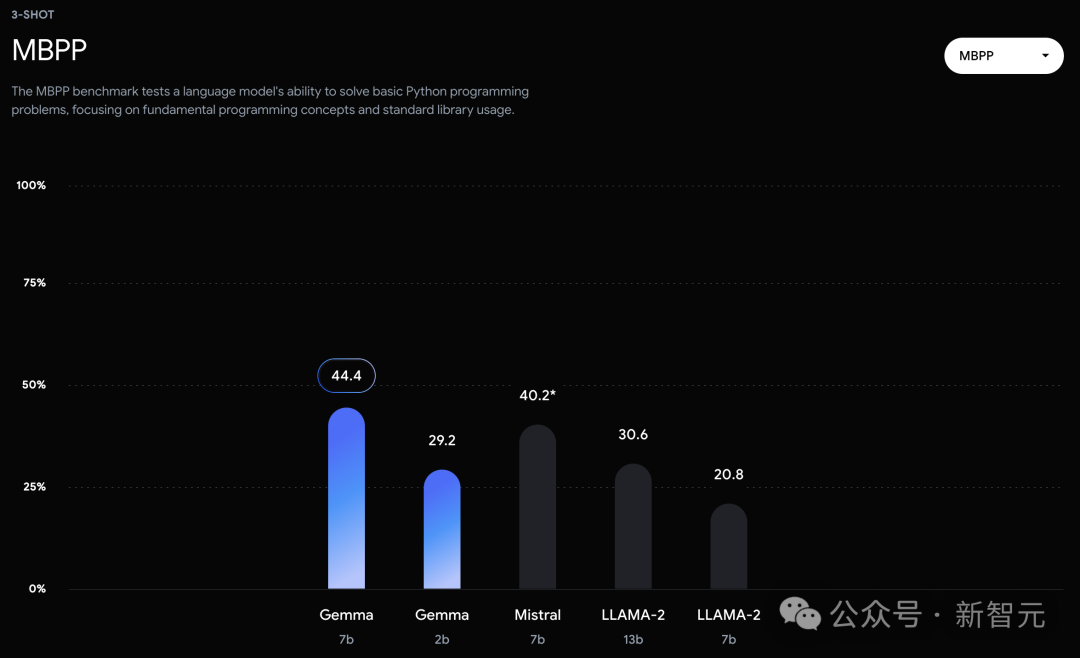
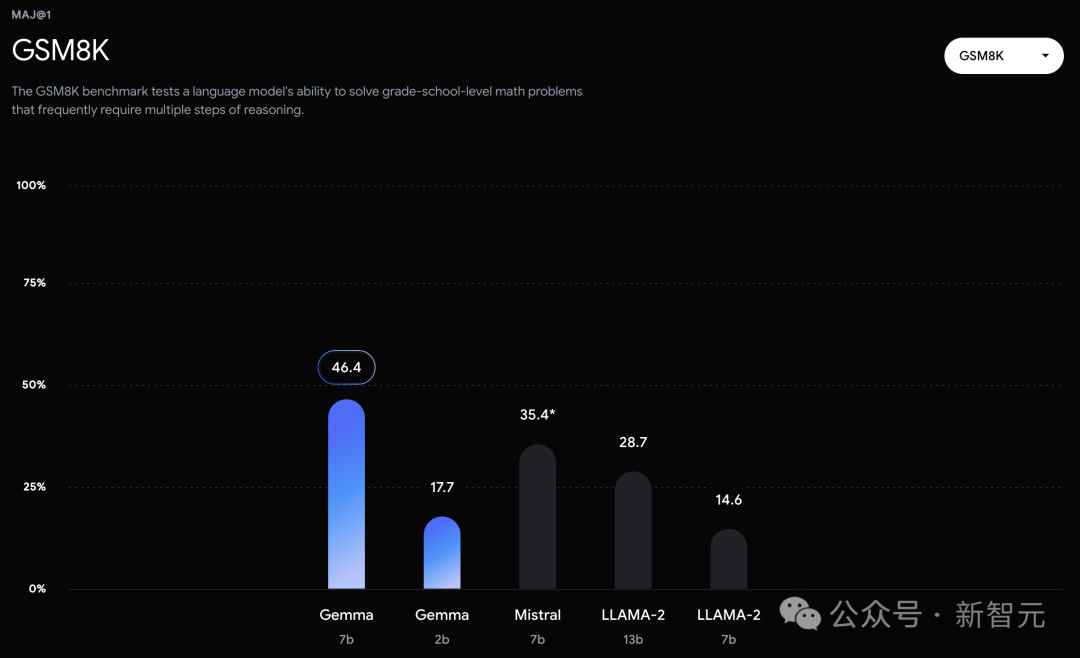
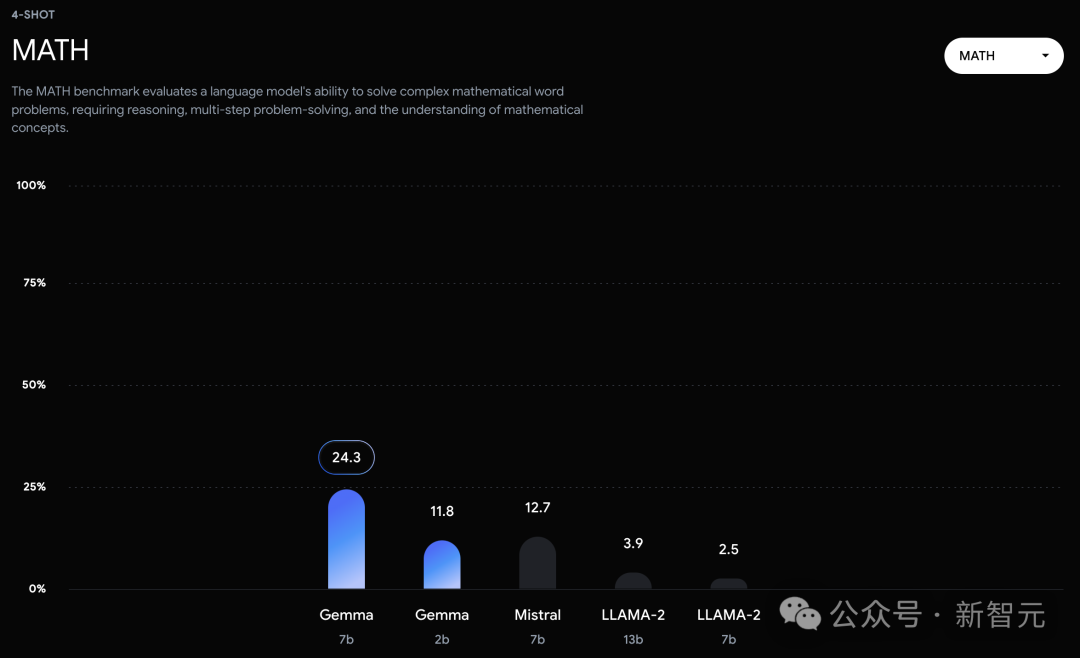
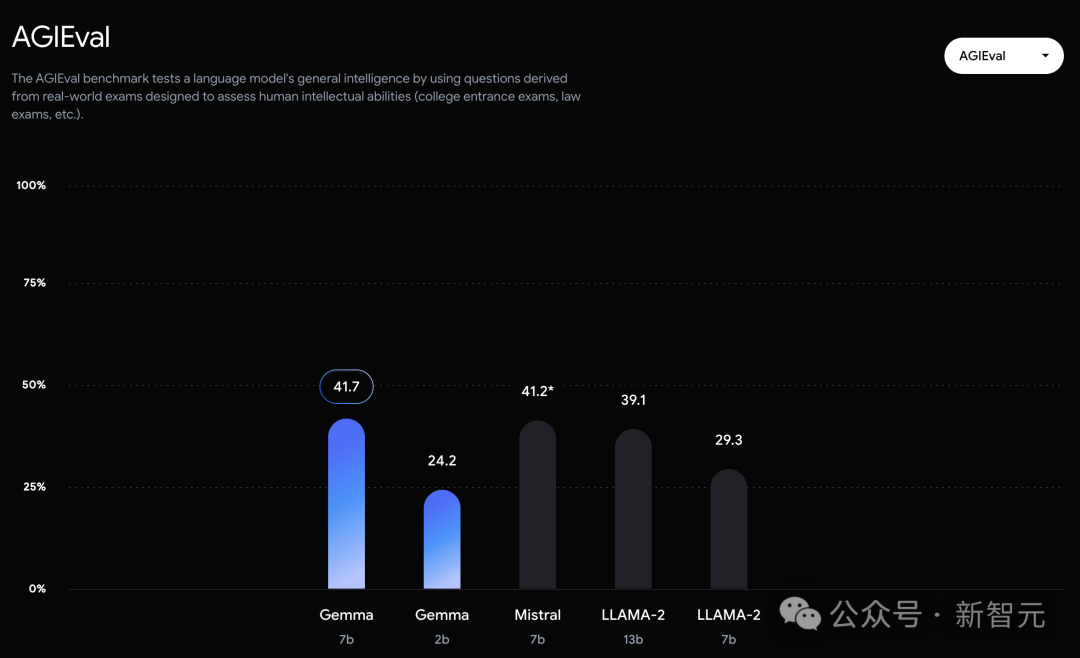
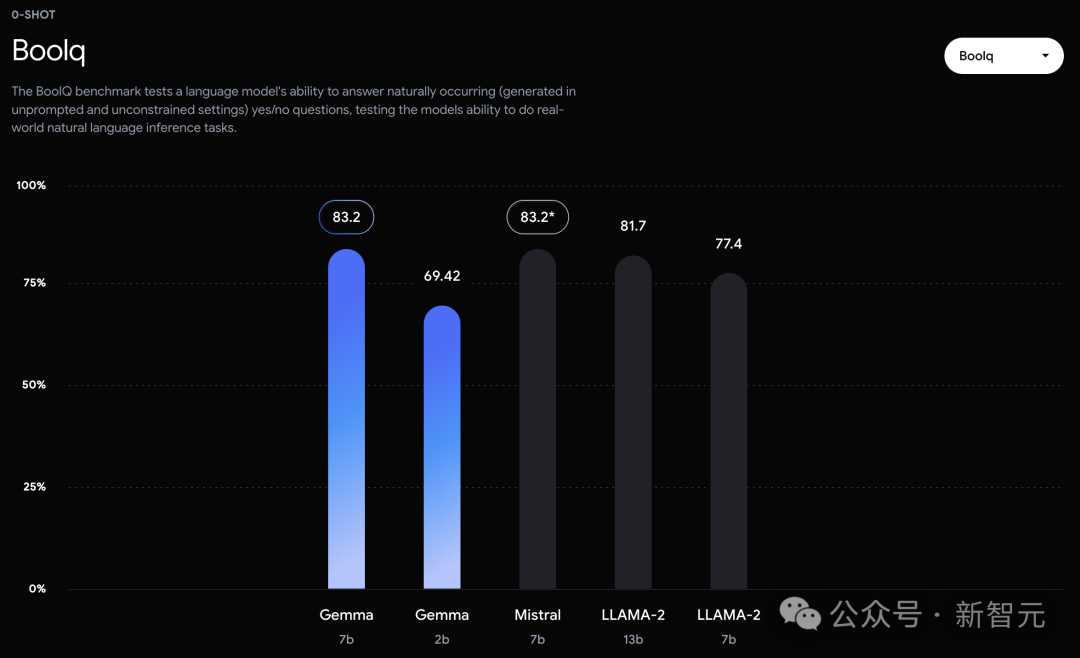
相比之下,Gemma 7B在Boolq测试中,只与Mistral 7B打了个平手。
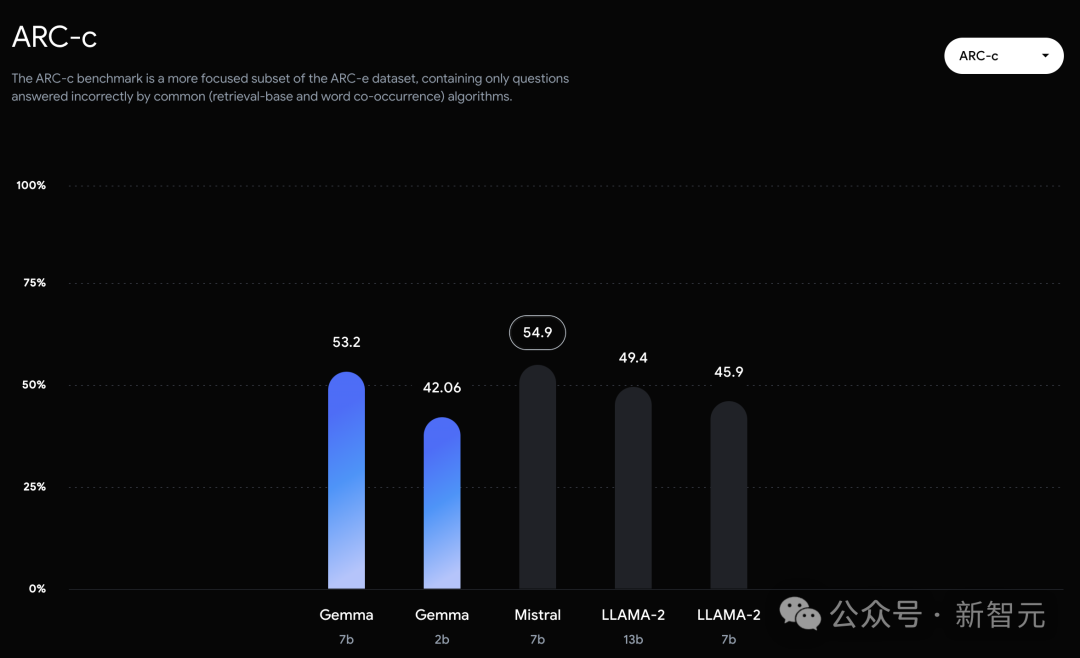
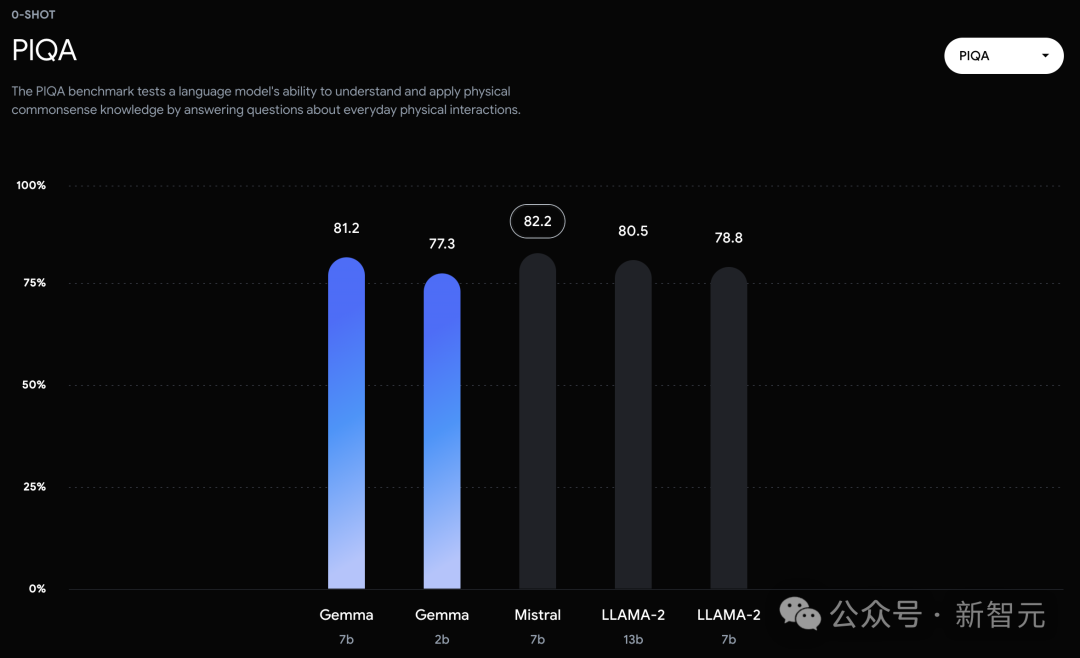
而在PIQA、ARC-c、Winogrande和BBH中,则不敌Mistral 7B。
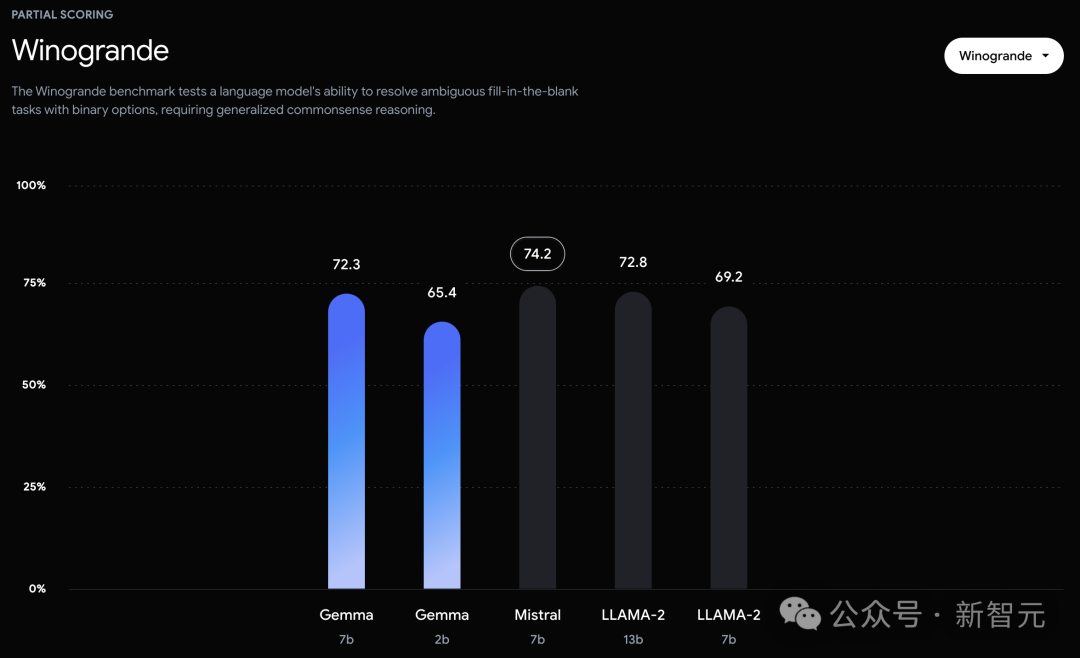
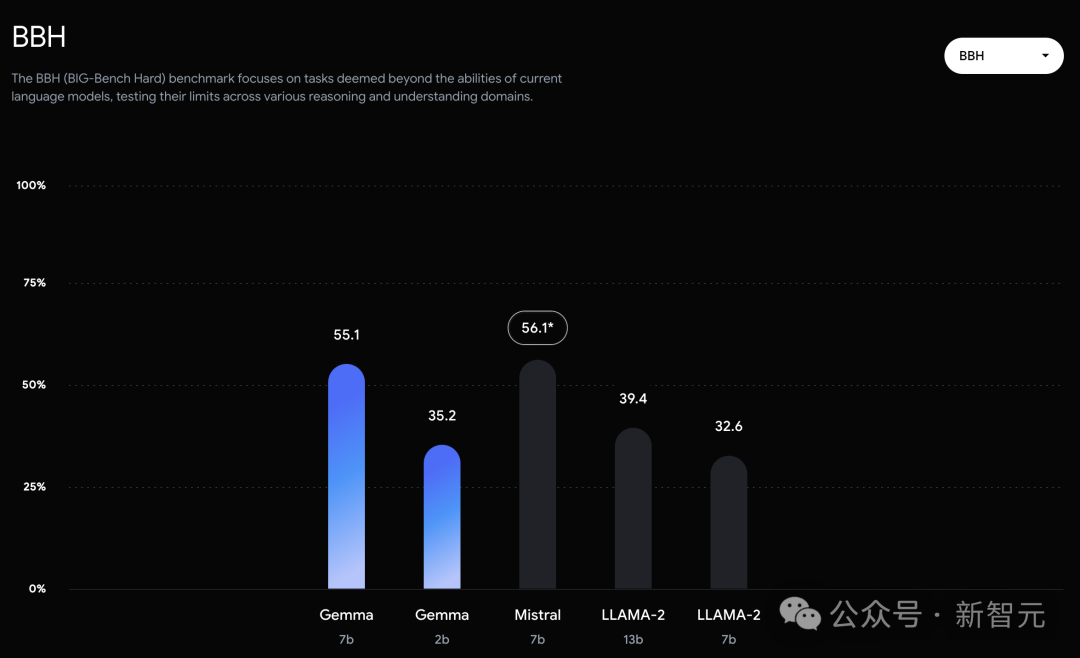
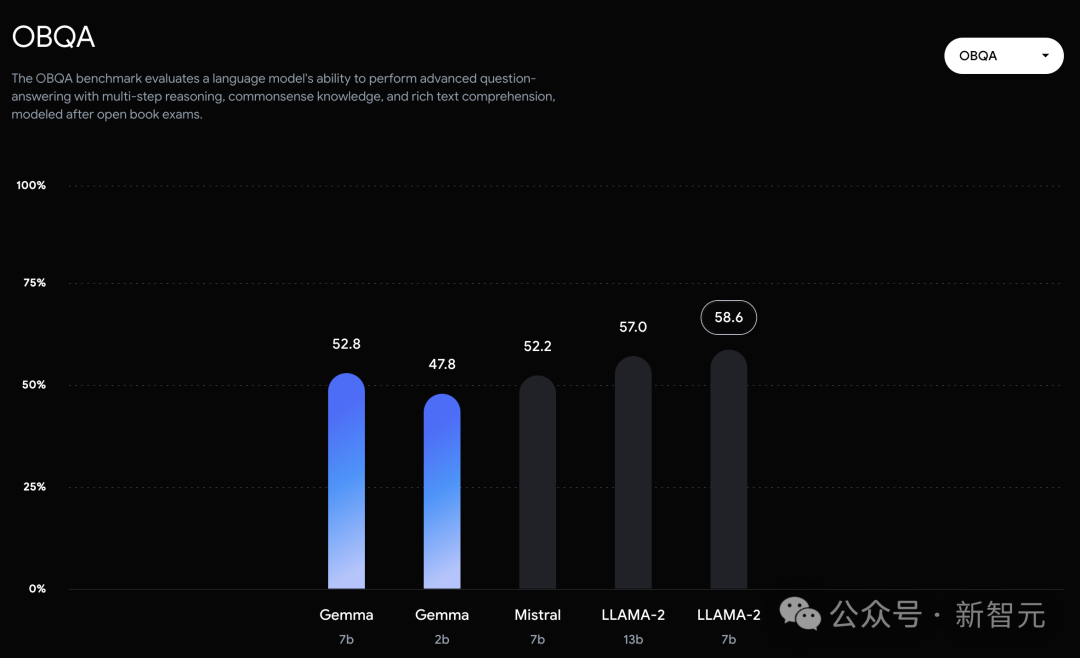
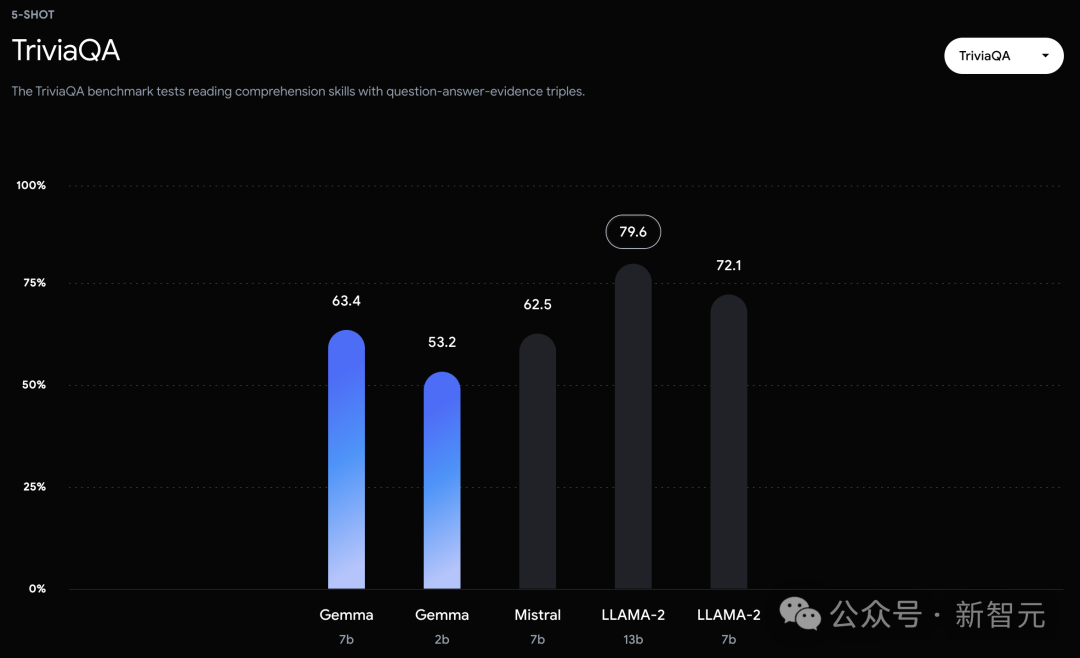
在OBQA和trivalent QA中,更是同时被7B和13B规模的Llama 2 7B斩于马下。
谷歌这次发布的两个版本的Gemma模型,70 亿参数的模型用于GPU和TPU上的高效部署和开发,20亿参数的模型用于CPU和端侧应用程序。在18个基于文本的任务中的11个中,Gemma都优于相似参数规模的开源模型,例如问答、常识推理、数学和科学、编码等任务。模型架构方面,Gemma在Transformer的基础上进行了几项改进,从而在处理复杂任务时能够展现出更加出色的性能和效率。- 多查询注意力机制其中,7B模型采用了多头注意力机制,而2B模型则使用了多查询注意力机制。结果显示,这些特定的注意力机制能够在不同的模型规模上提升性能。- RoPE嵌入与传统的绝对位置嵌入不同,模型在每一层都使用了旋转位置嵌入技术,并且在模型的输入和输出之间共享嵌入,这样做可以有效减少模型的大小。- GeGLU激活函数将标准的ReLU激活函数替换成GeGLU激活函数,可以提升模型的表现。- 归一化化位置(Normalizer Location)每个Transformer子层的输入和输出都进行了归一化处理。这里采用的是RMSNorm作为归一化层,以确保模型的稳定性和效率。架构的核心参数如下:
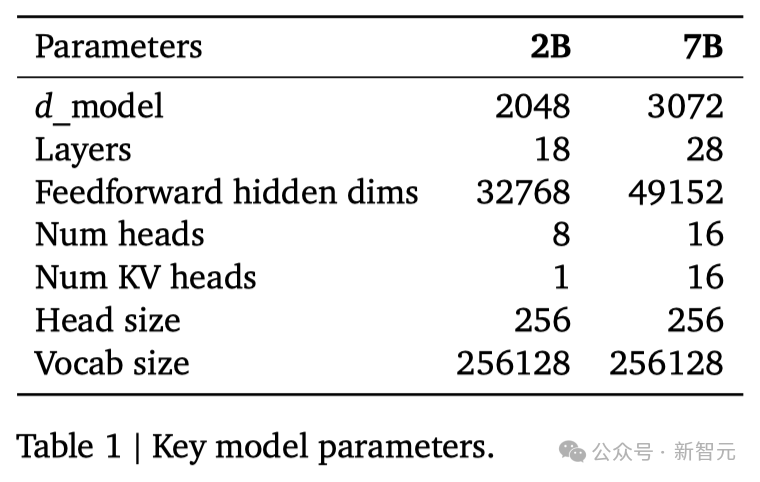
两种规模的参数如下:
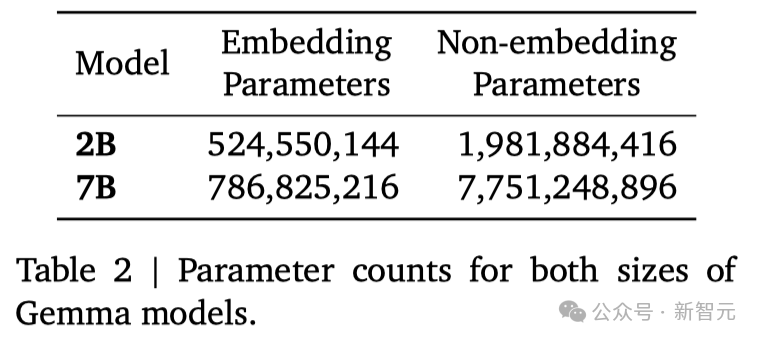
Gemma 2B和7B分别针对来自网络文档、数学和代码的主要英语数据的2T和6Ttoken,进行了训练。与Gemini不同,这些模型不是多模态的,也没有针对多语言任务的SOTA进行训练。谷歌使用了Gemini的SentencePiece分词器的子集,来实现兼容性。团队对Gemma 2B和7B模型进行了微调,包括有监督的微调(SFT)和基于人类反馈的强化学习(RLHF)。在有监督的微调阶段,研究者使用了一个由纯文本、英文、由人工和机器生成的问题-答案对组成的数据集。在强化学习阶段,则是使用了一个基于英文偏好数据训练出的奖励模型,以及一套精心挑选的高质量提示作为策略。研究者发现,这两个阶段对于提升模型在自动评估和人类偏好评估中的表现,至关重要。研究者根据基于LM的并行评估,选择了数据混合物进行监督微调。给定一组保留prompt,研究者会从测试模型中生成响应,从基准模型中生成对相同提示的响应,随机洗牌,然后要求一个更大、能力更强的模型在两种响应之间表达偏好。研究者构建了不同的提示集,以突出特定的能力,如遵循指令、实事求是、创造性和安全性。我们使用了不同的基于LM的自动评委,采用了一系列技术,如思维链提示、使用评分标准和章程等,以便与人类偏好保持一致。研究者进一步利用来自人类反馈的强化学习(RLHF),对已经进行过有监督微调的模型进行了优化。他们从人类评估者那里收集他们的偏好选择,并在 Bradley-Terry 模型的基础上,训练了一个奖励函数,这与Gemini项目的做法相似。研究者采用了一个改进版的REINFORCE算法,加入了 Kullback–Leibler 正则化项,目的是让策略优化这个奖励函数,同时保持与最初调整模型的一致性。与之前的有监督微调阶段相似,为了调整超参数并进一步防止奖励机制被滥用,研究者使用了一个高性能模型作为自动评估工具,并将其与基准模型进行了直接对比。
谷歌在多个领域对Gemma进行了性能评估,包括物理和社会推理、问答、编程、数学、常识推理、语言建模、阅读理解等。
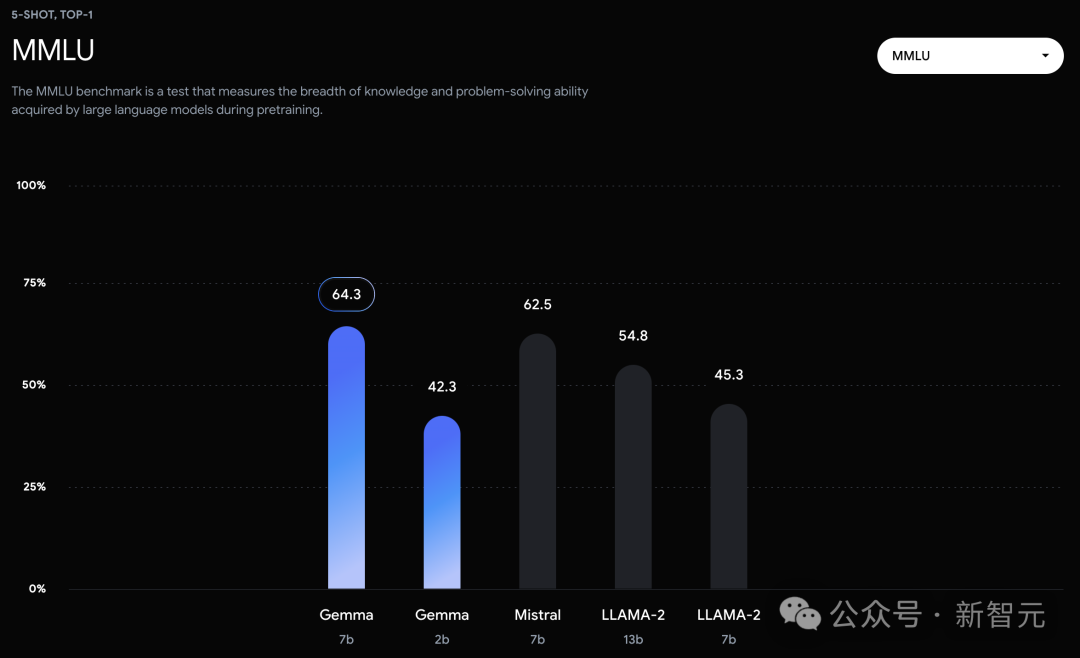
Gemma2B和7B模型与一系列学术基准测试中的多个外部开源大语言模型进行了比较。在MMLU基准测试中,Gemma 7B模型不仅超过了所有规模相同或更小的开源模型,还超过了一些更大的模型,包括Llama 2 13B。
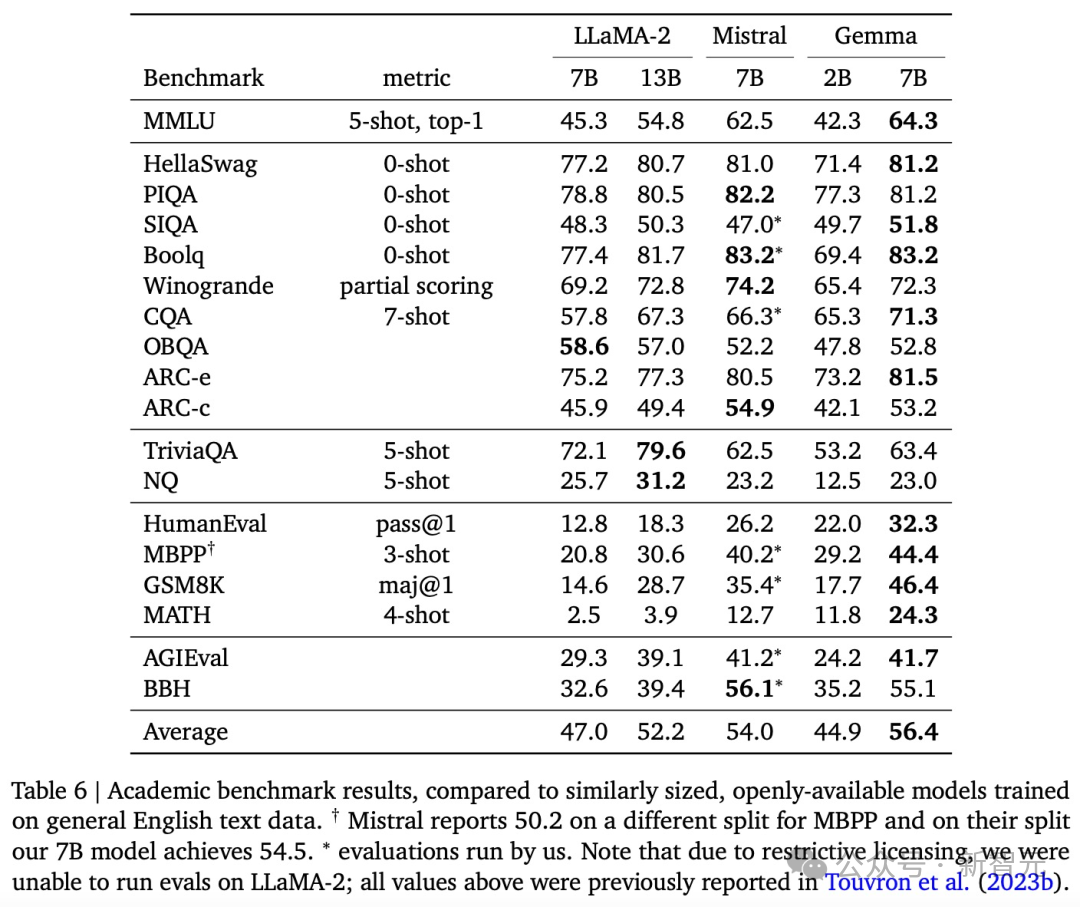
然而,基准测试的制定者评估人类专家的表现为89.8%,而Gemini Ultra是首个超越此标准的模型,这表明Gemma在达到Gemini和人类水平的性能上,还有很大的提升空间。并且,Gemma模型在数学和编程的基准测试中表现尤为突出。在通常用于评估模型分析能力的数学任务中,Gemma 模型在GSM8K和更具挑战性的 MATH基准测试上至少领先其他模型10分。同样,在HumanEval上,它们至少领先其他开源模型6分。Gemma甚至在MBPP上超过了专门进行代码微调的CodeLLaMA 7B模型的性能(CodeLLaMA得分为41.4%,而 Gemma 7B得分为44.4%)。近期研究发现,即便是经过精心对齐的人工智能模型,也可能遭受新型对抗攻击,这种攻击能够规避现有的对齐措施。这类攻击有可能使模型行为异常,有时甚至会导致模型重复输出它在训练过程中记住的数据。因此,研究者专注于研究模型的「可检测记忆」能力,这被认为是评估模型记忆能力的一个上限,并已在多项研究中作为通用定义。研究者对Gemma预训练模型进行了记忆测试。具体来说,他们从每个数据集中随机选择了10,000篇文档,并使用文档开头的50个词元作为模型的prompt。测试重点是精确记忆,即如果模型能够基于输入,精确地生成接下来的50token,与原文完全一致,便认为模型「记住了」这段文本。此外,为了探测模型是否能够以改写的形式记忆信息,研究者还测试了模型的「近似记忆」能力,即允许在生成的文本和原文之间存在最多10%的编辑差距。在图2中,是Gemma的测试结果与体量相近的PaLM和PaLM 2模型的对比。
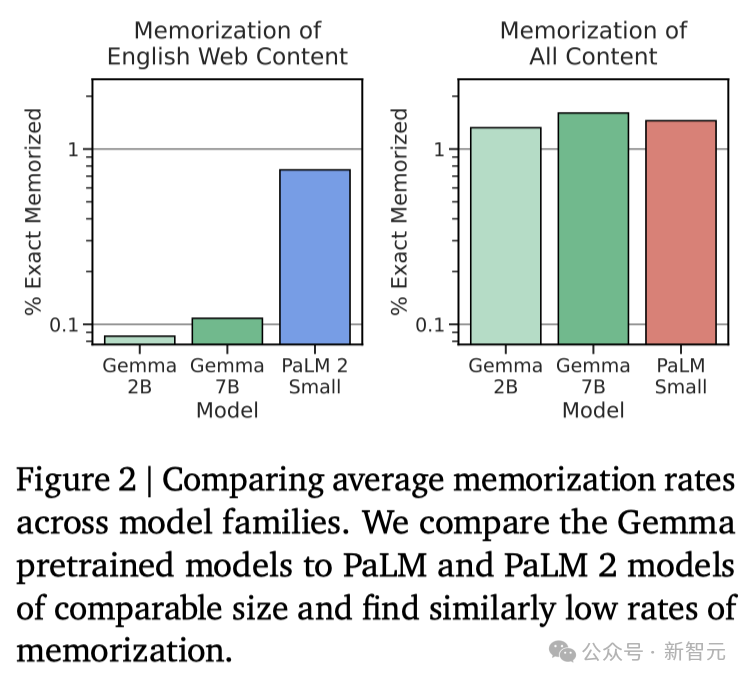
可以发现,Gemma的记忆率明显更低(见图2左侧)。不过,通过对整个预训练数据集的「总记忆量」进行估算,可得一个更为准确的评估结果(见图2右侧):Gemma在记忆训练数据方面的表现与PaLM相当。个人信息的记忆化问题尤为关键。如图3所示,研究者并未发现有记忆化的敏感信息。
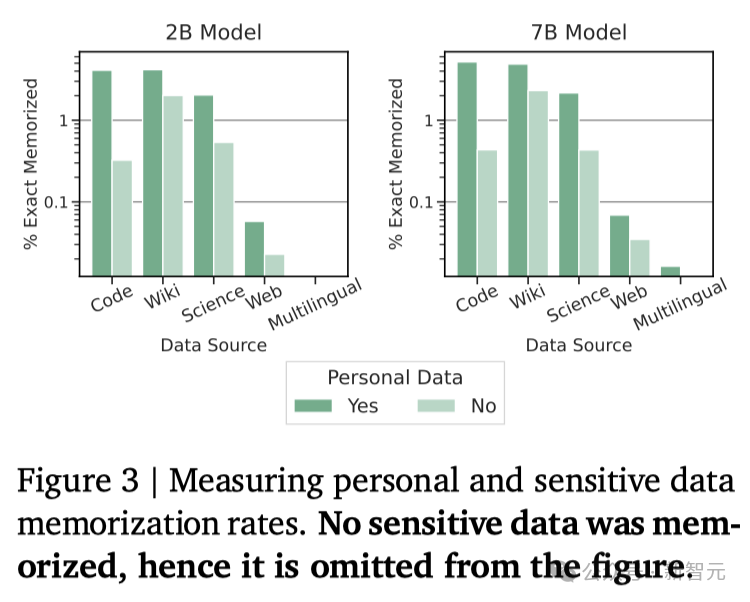
虽然确实发现了一些被归类为「个人信息」的数据被记忆,但这种情况发生的频率相对较低。而且这些工具往往会产生许多误报(因为它们仅通过匹配模式而不考虑上下文),这意味着研究者发现的个人信息量可能被高估了。
总的来说,Gemma模型在对话、逻辑推理、数学和代码生成等多个领域,都有所提升。在MMLU(64.3%)和MBPP(44.4%)的测试中,Gemma不仅展现了卓越的性能,还显示了开源大语言模型性能进一步提升的空间。除了在标准测试任务上取得的先进性能,谷歌也期待与社区共同推动这一领域的发展。Gemma从Gemini模型计划中学到了很多,包括编码、数据处理、架构设计、指令优化、基于人类反馈的强化学习以及评估方法。同时,谷歌再次强调使用大语言模型时存在的一系列限制。尽管在标准测试任务上表现优异,但要创建出既稳定又安全、能够可靠执行预期任务的模型,还需要进一步的研究,包括确保信息的准确性、模型的目标对齐、处理复杂逻辑推理,以及增强模型对恶意输入的抵抗力。团队表示,正如Gemini所指出的,需要更具挑战性和鲁棒性的测试基准。





















