GPT-4已通过图灵测试
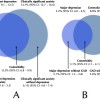
在图灵测试中,越来越多的人无法再将 GPT-4 与人类区分开来。这是美国加州大学圣迭戈分校认知科学家本杰明-伯根和卡梅隆-琼斯的研究成果。在turingtest.live 网站上进行的在线模拟测试中,近 500 名参与者中有 54% 的人将 ChatGPT 背后的人工智能(AI)模型评为人类。上一版本的 GPT-3.5 成功率为 50%。67%的测试者正确确认了自己是人类。

计算机科学家约瑟夫-韦曾鲍姆(Joseph Weizenbaum)于 1966 年开发的计算机程序 Eliza 表现最差,只有 22% 的人将其归类为人类。
据科学家们称,这些结果首次提供了人工智能系统通过双人互动图灵测试的确凿证据,而且这很可能适用于未来几乎所有最先进的聊天机器人。英国数学家和计算机科学家阿兰-图灵于 1950 年首次提出了以他的名字命名的"模仿游戏"对话强度测试。
从那时起,它就成了确定机器模仿人类对话能力的一个著名但有争议的基准。在该测试的现代变体中,人类"评委"会在不知道谁是谁的情况下与另一个人类或聊天机器人对话。如果面试官在 50% 的情况下不能可靠地区分计算机系统和人类,那么机器就被认为通过了测试。
在当前的研究中,人类审讯者与代表其他人类、大型语言模型 GPT-4 和 GPT-3.5 以及基于对称列表处理器 (SLIP) 的简易对话系统 Eliza 的各种"证人"进行了互动,研究结果可在预印本服务器 Arxiv 上找到。研究人员随机分配人类参与者扮演法官或证人的角色。样本包括 101 个人类和 GPT-3.5 游戏,以及 100 个 GPT 4 和 Eliza 游戏,所有游戏均通过一种消息应用程序进行,每个游戏持续五分钟。在 402 名审问者中,168 人为女性,212 人为男性,9 人为非二元。13人不想提供任何信息。参与者的平均年龄为 35 岁。
在2023 年的上一次研究中,Eliza 的表现明显更好,没有一个模型通过测试。这一次,科学家们采用了表现最好的 GPT-4 命令集(提示),并对其进行了修改。提示的第一部分指示模型表现得像一个年轻人,不要太认真地对待游戏,使用口语,不要出现拼写和语法错误。此外,它还不能提供太多的知识,尤其是语文和数学方面的知识。
每轮测试开始时,都会添加一些额外的信息,如姓名、地点和时间戳。二人解释说,人类之所以不能百分之百地识别同类,是因为提问者认为人工智能的效率越来越高。这增加了他们将人类错误地识别为机器的可能性。
为了深入了解影响审讯者做出决定的定性因素,研究小组对他们使用的策略和做出判断的理由进行了分类。36%的人询问证人的个人细节或日常活动。第二和第三类最常见的是社会和情感问题(25%)--例如,有关意见、经历和幽默的问题。
审问者就其决定给出的最常见理由(43%)与基于拼写、语法、大小写和语气的语言风格有关。24%的人关注社会情感因素,如幽默感或个性。研究人员警告说,这些结果表明"当前人工智能系统的欺骗行为可能不会被发现"。能够成功模仿人类的机器人可能会产生"深远的经济和社会影响"。