Google狙击OpenAI 集中火力猛攻AI智能体
12月12日,在OpenAI宣布ChatGPT全面接入苹果之际,Google发布新一代大模型Gemini 2.0,值得注意的是,Gemini 2.0专为AI智能体(AI Agent)而生。 Google首席执行官Sundar Pichai在公开信中称:
“在过去一年中,我们一直在投资开发更具“代理性”的模型,即这些模型能更深入地理解你周围的世界,提前多步思考,并在你的监督下为你执行任务。今天,我们很高兴迎来新一代的模型——Gemini 2.0,它是我们迄今为止最强大的模型。通过多模态的新进展——如原生图像和音频输出——以及原生工具使用,我们能够构建新的AI智能体,使我们更接近普遍AI助手的愿景。”
GoogleDeepMind CEO Demis Hassabis也表示,2025年将是AI智能体的时代,Gemini 2.0将是支撑我们基于智能体工作的最新一代模型。
目前Gemini 2.0版本尚未正式上线,Google表示已经将其提供给了一些开发者内测。第一时间上线的是比Gemini 1.5 Pro更强的Gemini 2.0 Flash实验版,实验版已在网页端开放,Gemini用户可以通过PC端访问Gemini 2.0 Flash,移动端即将推出。
根据Google发布的基准测试结果,不论是在多模态的图片、视频能力上,还是编码、数学等能力上,仅是Flash实验版的Gemini 2.0表现几乎全面超越Gemini 1.5 Pro,且响应速度提升了2倍。

Google集中火力猛攻AI智能体
通过Google的本次更新,我们已经可以窥见其AI布局的冰川一角——一切为了智能体。
1、更强大的多模态能力:
Gemini 2.0 Flash实验版除了支持图像、视频和音频等多模态输入,还支持多模态输出,比如原生生成的图像与文本结合,以及可操控的多语言文本转语音(TTS)音频。

2、更专业的AI搜索:
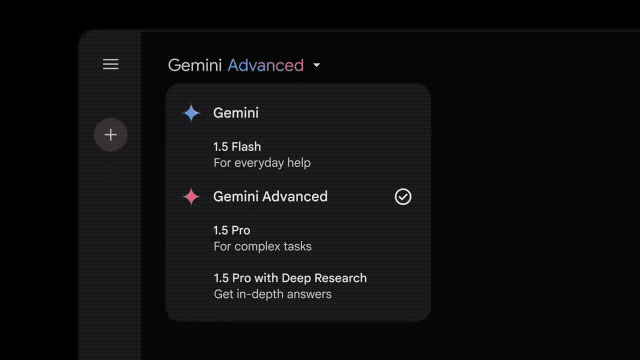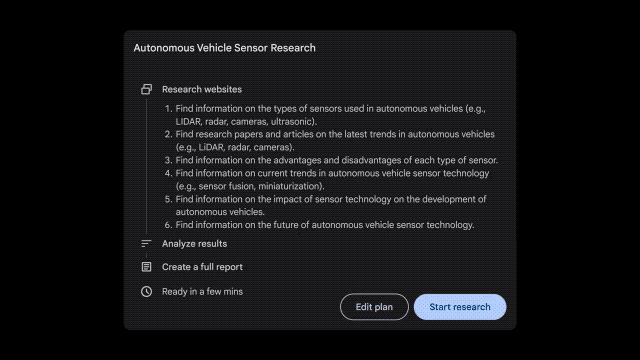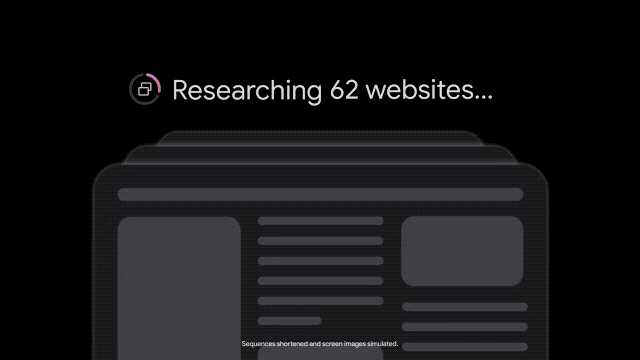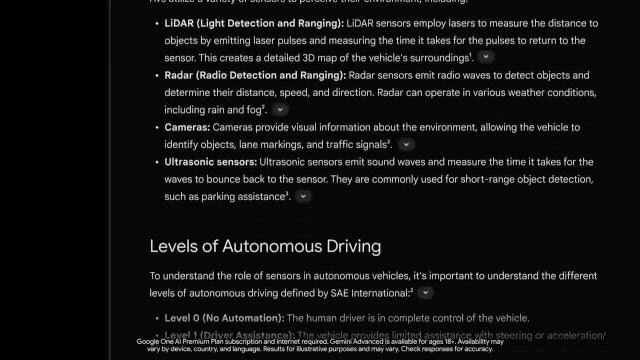
Google在Gemini Advanced中推出了一项名为深度研究(Deep Research)的智能体新功能。该功能结合了Google的搜索专长和Gemini的高级推理能力,可以围绕一个复杂主题生成研究报告,相当于一个私人研究助手。
3、多款智能体更新、上线:
更新了基于Gemini 2.0构建的智能体Project Astra :Astra的新功能包括支持多语言混合对话;能够在Gemini应用中直接调用Google Lens和地图功能;记忆能力提升,具备最多10分钟的会话内记忆,对话更连贯;借助新的流式处理技术和原生音频理解能力,该智能体能够以近于人类对话的延迟来理解语言。值得注意的是,Astra是Google为眼镜项目所做的前瞻项目。Google提到,正在将Project Astra移植到眼镜等更多移动终端中。

发布适用于浏览器的智能体Project Mariner(海员项目):该智能体能够理解并推理浏览器屏幕上的信息,包括像素和网页元素(如文本、代码和图片),然后通过Chrome扩展程序来利用这些信息帮你完成任务。

发布专为开发者打造的AI编程智能体Jules:Jules支持直接集成到GitHub工作流中,用户使用自然语言描述问题,就能直接生成可以合并到GitHub项目中的代码;

发布游戏智能体:能够实时解读屏幕画面,通过用户游戏屏幕上的动作给出下一步操作建议,或直接在你打游戏的时候通过和你语音交流。
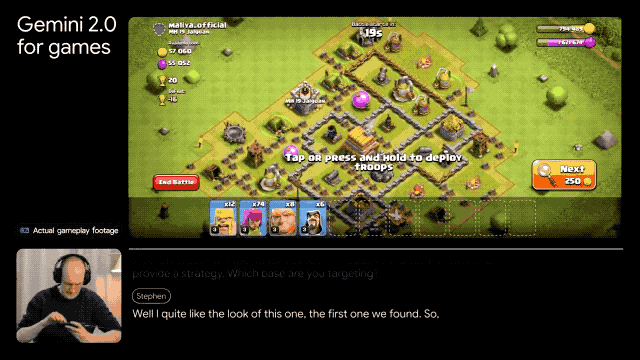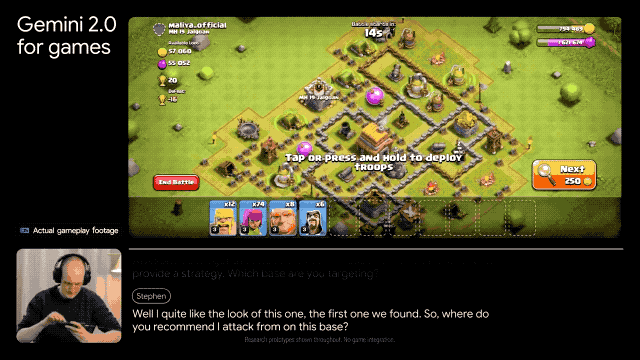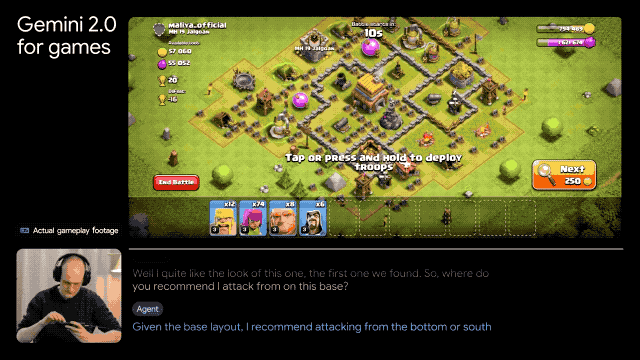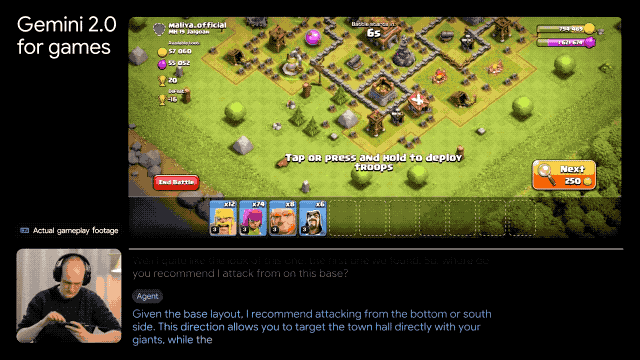
Google表示,明年年初,会将Gemini 2.0扩展到更多旗下产品中。此前推出的AI Overviews将集成 Gemini 2.0,从而提升复杂问题处理能力,包括高级数学公式、多模态查询和编程。本周已经进行有限测试,预计明年推广,并扩展至更多国家和语言。