我用400块的“洋垃圾” 跑通了DeepSeek
在我看来,2025年绝对能称得上是中文大模型的颠覆之年。DeepSeek的横空出世,不仅打破了英伟达主导的“算力决定一切”的刻板印象,也打破了美国在大模型领域的长期主导地位,甚至一度挑起了全球大模型领域的价格战,让更多的人能够体验到大模型带来的乐趣。
至少从抖音、快手上的反应来看,对普罗大众而言,DeepSeek的出现确实把“人工智能”这样一个遥不可及的概念带到了人们身边。
哪怕是我这个浸淫大模型两年半的雷科技练习生,在过年期间不仅没少给身边的父母亲戚介绍这DeepSeek到底是什么,自己也是时不时就拿起手机来玩一下,没办法,能在不要钱的基础上提供这种问答质量的中文大模型,目前也就DeepSeek能做到了。
要说有什么问题嘛,还得是这服务器的问题了。

特别是我这边发出请求,然后看着DeepSeek在那里转个半天,最终却只能憋出个“服务器繁忙,请稍后再试”的时候,那种挫败感是真的难受,让人迫切想要在本地部署一个属于自己的DeepSeek推理模型。
问题就出在成本上,按照常理来说,想要购入一台能在本地运行大模型的设备,那要不就是售价在5000元以上的AI PC笔记本,要不就得自己着手去装配一台搭载独立显卡的整机,不管哪个选择对普通消费者来说都不够友好。
不过将预算压缩到极致,然后搭配出一套“能用”的主机,正是每一位DIY玩家的终极乐趣,而这给我带来的挑战就是,如果真的想弄一台可以本地运行DeepSeek模型的电脑,到底需要多少钱?
我的答案是,400元。
尽管近期正经的内存和硬盘有价格上涨的趋势,但是在洋垃圾这边其实价格变化倒是不大,甚至一批早年的洋垃圾CPU和矿卡GPU还有价格下跌的趋势。在如今大模型潮流席卷而来的背景下,我甚至不准备拘泥于办公影音需求,决定挑战一下用四百块钱的预算,试着去打造出一套性价比颇高的入门级本地大模型主机。
至于具体应该怎么操作,最终成效是否如意,跟着我一起看下去自然就知道了。
1 越陈越香的洋垃圾
既然说了要在400块内搞定,那么如何在尽量低的价钱内完成整机的装配就变得至关重要了。
在CPU的选择上,我直接从PDD上捡了一颗Intel® Core™i3-4170,售价22元。
该处理器为二核四线程,3.7GHz主频,没有睿频能力,具备3MB智能缓存,采用22nm制程工艺的Haswell架构,而它最大的特点就是拥有一颗HD4400核显,这也是我选择它的关键。

(图源:PDD)
俗话说得好,低价U配低价板嘛。
所以主板的话,我就选择购入了一块铭瑄MS-H81M Turbo,只有两根DDR3内存插槽不说,甚至都没有HDMI输出接口,也没有M2硬盘位,USB 3.0、SATA III接口都只有两个,但是它在PDD上面只要79块钱。
这加起来仅需100左右的板U套装,性价比放在今时今日也是出类拔萃的。

(图源:雷科技)
这种CPU,散热就不用太担心了。
PDD上面14.9包邮寄过来的双热管风冷散热器,虽然外观上是丑了一点,简陋了一点,但是用来压我这一套超低价配置肯定是绰绰有余了。

(图源:雷科技)
至于显卡嘛,近期闲鱼上面流出了一大堆P106-090和P106-100矿卡,其中前者的价格普遍在70块钱左右,后者的价格普遍在120-140块钱左右。
两者之间最大的差别在显存上,P106-090仅有3GB显存,而P106-100则有6GB显存,尽管我这次的初衷并不是为了游戏而来,但是更高的显存规格确实可以运行更高效的本地大模型,所以我最终还是拿下了一张技嘉的P106-100,售价130元。

(图源:雷科技)
最后,给它简单配上两根杂牌DDR3内存,组成内存双通道,用一个300W长城电源供电,一块120GB SATA SSD做系统盘,用上次装机剩下来的大水牛硅脂凑合凑合,最后再配上个20块钱的电脑城小机箱...
完成!请欣赏一下我用四百元装机的成果吧。

(图源:雷科技)
然后是我给出的参考价格表,感兴趣的大伙也可以试着照这张表格上的配置自己配一下,总之价格上不会差太多。
你要是更追求性价比的话,甚至把机箱换鞋盒也不是什么大问题。

(图源:雷科技)
装机完成,点亮主机!
先做个简单的性能测试,作为多年服役的老将,Intel® Core™i3-4170的性能也就那样,即便是在用TrottlesStop解锁功耗的情况下,也就差不多相当于移动端酷睿六代、酷睿七代处理器的水平。

(图源:雷科技)
在实测环节中,CPU-Z测试单核跑分有373.4分,多核跑分有1025.2分,在CINEBENCH测试标准下,CINEBENCH R20多核824cb、单核346cb,CINEBENCH R23多核1914cb、单核905cb。
亮眼肯定是不够亮眼,但是拿来日常办公、轻度娱乐倒是够了。

(图源:雷科技)
再看看GPU部分,我手上这张技嘉P106-100采用16nm工艺打造,显卡核心为GP106,核心频率为1506MHz,可提升到1709MHz,具有1280个着色单元,支持DirectX12,显存规格为6144MB/192Bit GDDR5内存,显存频率可达2002MHz。
在测评DX11性能的Fire Strike测试中,P106-100在Extreme测试中取得了6490分的图形分数;在测评DX12性能的TimeSpy测试中,P106-100在基本测试中取得了4428分的图形分数。


(图源:雷科技)
这个性能表现和GTX1060差不多,甚至能和移动端RTX 3050碰一碰了。
存储方面,我们斥资40元购入的这块杂牌128GB SATA SSD硬盘,顺序读写速度达到505.24MB/s和369.63MB/s,随机4K读写达到132.06MB/s和246.55MB/s,虽然和M2 SSD硬盘没得比,但是作为系统启动盘肯定是绰绰有余了。

(图源:雷科技)
至于这对双通道的DDR3内存,使用AIDA64进行内存缓存测试,测得的读取速度为18557MB/s,写入速度为19889MB/s,复制速度为17914MB/s,延迟为67.2ns,给这台电脑用可以说是刚刚好。

(图源:雷科技)
2 百元机,用上DeepSeek
既然目的是在几百块钱的预算下,打造出一套可用的本地DeepSeek主机,那么体验肯定是我们最关注的一环。
首先,要说真正的DeepSeek-R1,那便只有一个版本,即671B的原始版本,其中包含大量的参数,推理精度确实高,但需要大量计算资源,而且显存至少为1342GB。

(图源:HuggingFace)
这显然是P106-100承受不起的,也没有哪张消费级显卡能承担得起就是了,官方推荐的方法是用16张NVDIA-A100 80GB显卡,或者是组成Mac电脑集群,用高速度的统一内存去跑。
像我们这种消费级显卡,就只能用“蒸馏模型”。
所谓蒸馏模型,可以看成“老师教学生”,通过知识蒸馏,教更精简的模型学会复制较大模型的行为,扩充性能,减少资源需求,而用DeepSeek-R1蒸馏的话,主要就是给这些模型加入“深度推理”的概念。
再降低一下模型精度,就能看到我们能够部署的蒸馏模型。

(图源:HuggingFace)
然后根据Unsloth提供的报告,DeepSeek-R1-Distil-Qwen-7B是符合需求的蒸馏模型中表现最出色的,各方面测试成绩均超越了理论参数更多的DeepSeek-R1-Distil-Llama-8B。
那么我们今天要部署的,自然就是DeepSeek-R1-Distil-Qwen-7B。

目前想在PC本地部署DeepSeek有两种办法,其中最常见的应该是Ollama+Chatbox AI的组合。
所谓Ollama,其实就是一款比较流行的本地大模型服务端工具,部署起来也很简单,只要在Ollama官网搜索DeepSeek-r1,下面就会有不同大小的蒸馏模型渲染,然后搭配客户端启动就行了。

(图源:Ollama)
安装后,Ollama一般就在本地的11434端口开启服务了,但此时你只能在终端中进行交互,但是要获得像DeepSeek官网一样的体验,还是需要额外的前端客户端才行。
而Chatbox AI,就是最常见的一款前端产品。
不同于服务端的纯文字内容展示 ,Chatbox AI将大部分设置、功能进行了图形化,使用户的体验更加直观,而且这款产品支持众多本地AI模型和API接口,自然也可以使用本地Ollama 11434端口的服务。
接入之后,大概就是这个样子。
(图源:雷科技)
你可以在Chatbox AI定义自己想要交互的模型人设,
但要论角色扮演的话,第二种部署方法或许会更适合一点。
为你介绍Koblodcpp,这是一款整合Koblod.AI界面的llamacpp启动程序,可以运行目前外网流行的GGUF格式本地大模型,甚至可以整合语音大模型和绘图大模型,实现在对话的同时,生成语音和对应场景的效果。
只要在HF-Mirror下载对应的大模型,然后就能用Koblodcpp启动了。
(图源:雷科技)
使用Koblodcpp,你就可以加载通用格式的角色卡,实现和各种不同的角色对话交流的独特体验。
如果这还不够,你还能够借助Koblodcpp的端口部署SillyTarven,后者是目前全网公认的最好用的大模型角色扮演前端,能够帮助用户实现对话逻辑的定义,对用户自身人设的定义,加载补充世界观的Lorebook和载入图片、动图以及互动代码来完善角色扮演体验。
甚至...可以让DeepSeek实现破限,做到一些云端大模型做不到的事情。
简单介绍完部署方法后,接下来就该进入实测环节了。
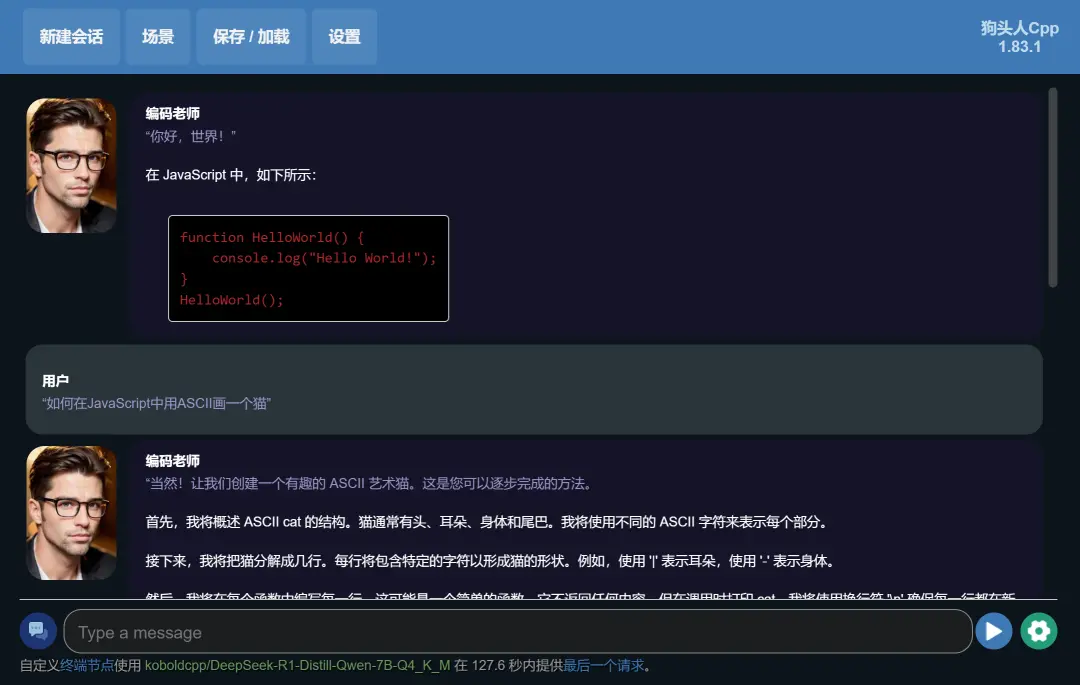
用一些常规问题和它进行交互,就能看到详细的推理过程,应付一些正经的初高中语文、数学、英语问题,本地部署的DeepSeek体验起来还是不错的。
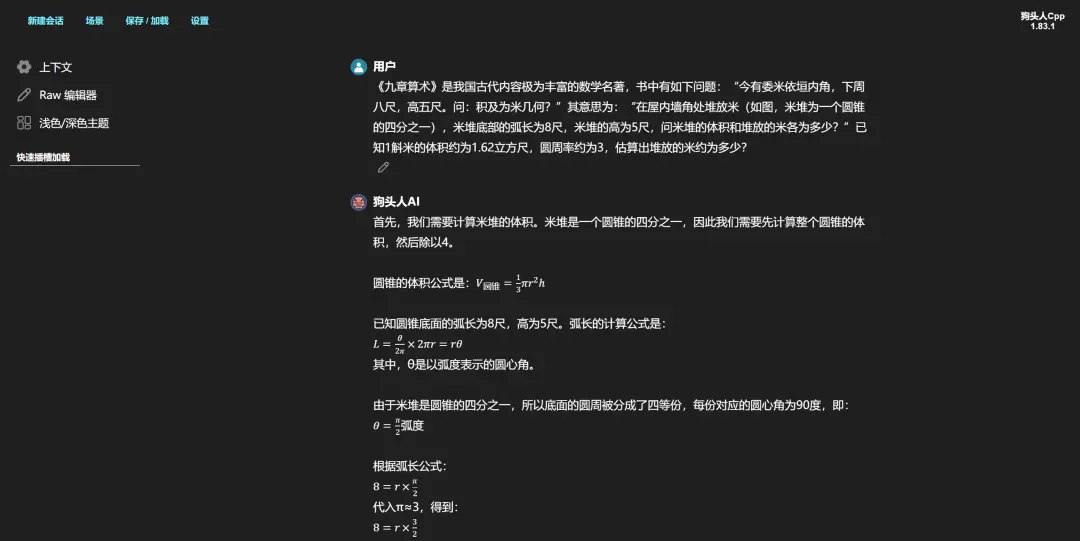
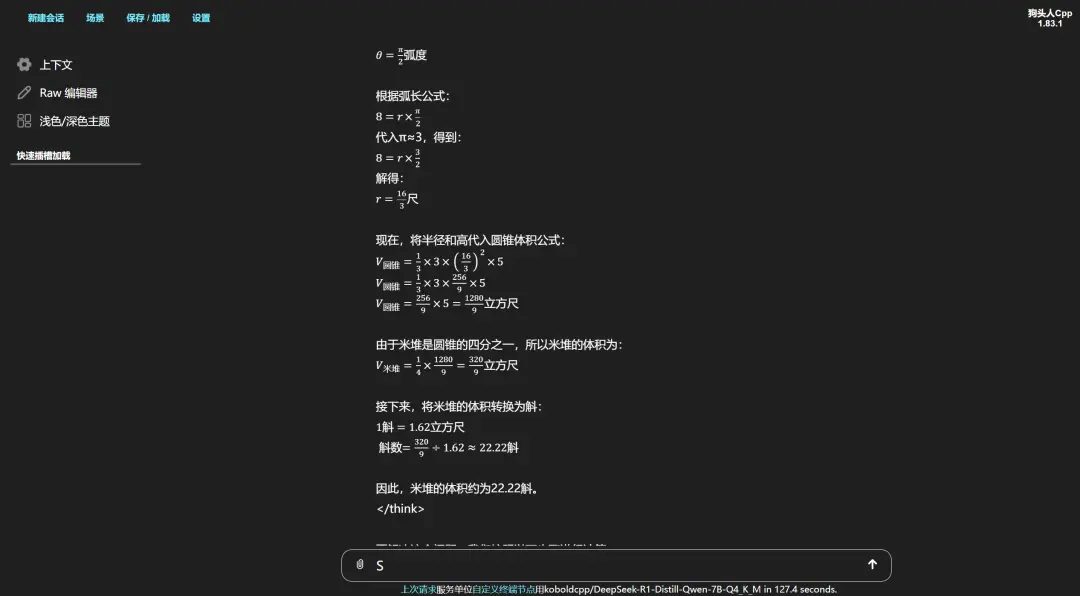
(图源:雷科技)
询问一些关公战秦琼的问题,文学创作能力看起来也不赖。

(图源:雷科技)
不过在比较复杂的数学、逻辑难题里,本地部署的DeepSeek表现就比较一般了,有不少逻辑推理题甚至会出现算不出答案的情况。

(图源:雷科技)
因为没有联网的缘故,目前本地部署的DeepSeek模型的知识库是截至2023年的,没有比较新鲜的素材,因此一些有时效性的问题自然无法作答。

(图源:雷科技)
至于速度的话,在限制回复长度为1024代币的情况下,应付一道高中数学题的思考过程为127s(即两分钟)左右,这个速度和原版DeepSeek之间差别不大,深度思考的特性让本地和云端的体验大大拉近。
(图源:雷科技)
当然了,因为思考太长的原因,本地部署的DeepSeek确实就不大适合聊天用了,喜欢聊天的建议更换Casuallm大模型进行体验。
3 总结:低配置也能跑,
但稳定性欠佳
优点:
1、成本预算低廉;
2、确实能运行本地大模型。
缺点:
1、二手零部件无保障;
2、矿卡驱动非常容易掉,白屏问题时有发生。
论性能,这款预算不到400元的电脑主机其实还不错。
尽管CPU规格老旧、矿卡表现不稳定,但是这台廉价主机确实能完成DeepSeek本地大模型的部署,在组装完成后的这段时间里,它一度成为公司局域网内部的AI终端,还可以部署本地AI绘图等一系列能力,算是实至名归的AI PC。
虽然没有具体测试,但是近4500分的TimeSpy图形分,即便是《孤岛惊魂6》这样的3A大作,这款机子也能在FHD低画质下保证60帧稳定运行,应付《英雄联盟》这类网游应该是绰绰有余的,也可以当一台入门的游戏主机来用。

说是这么说,问题当然还是有的。
先说这台机子,为了搞好这台机子我也是前后折腾了半天。 P106-100这张矿卡多次出现掉驱动导致电脑白屏,需要用DDDU卸载驱动再重装的情况,至于那个二手电源后面直接瘫痪了,还得去PDD上面扯皮商家才肯换货。
目前闲鱼上面还有不少和我组装起来的这台机子配置类似的洋垃圾整机,售价普遍在350-400元左右,目标受众很明显是刚上大学或者走出社会的年轻群体,个人建议大伙别去购买这些产品,一分钱一分货可不是开玩笑的。
再说说DeepSeek,目前市面上所有的本地DeepSeek部署教程,包括我们在内,实际上部署的都是经过DeepSeek蒸馏的通义千问模型,回答一些基础问题,简单测试深度思考还行,复杂一点的逻辑思考能力,这本地部署的版本和全参数的版本之间的差别可不是一星半点。
只能说,真要想追求不卡的全参数DeepSeek体验,整个API接口可能是更加合理的方法。