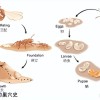
大多数AI在读取时钟与计算日期方面都很吃力 错误率甚至高达75%
生成式人工智能工具能够执行那些曾经似乎是科幻小说中的任务,但它们中的大多数在许多基本技能方面仍然很吃力,包括阅读模拟时钟和日历。 一项新的研究发现,总体而言,人工智能系统正确读取钟面的时间不到四分之一。

爱丁堡大学的一个研究小组测试了一些顶级多模态大型语言模型,看看它们能在多大程度上回答基于钟表和日历图像的问题。
接受测试的系统包括Google DeepMind 的 Gemini 2.0、Anthropic 的 Claude 3.5 Sonnet、Meta 的 Llama 3.2-11B-Vision-Instruct、阿里巴巴的 Qwen2-VL7B-Instruct、ModelBest 的 MiniCPM-V-2.6,以及 OpenAI 的 GPT-4o 和 GPT-o1。
图像中出现了各种类型的时钟:有罗马数字的、有秒针的、没有秒针的、不同颜色表盘的等等。
系统正确读取时钟的比例不到 25%。 对于使用罗马数字和风格化指针的时钟,它们的表现更为吃力。
去掉秒针后,人工智能的表现并没有改善,这让研究人员认为,问题来自于检测时钟的指针和解释钟面上的角度。
研究人员利用 10 年的日历图像,提出了一些问题,如元旦是星期几?即使是最成功的人工智能模型,也有 20% 的时间把日历问题做错了。
成功率因所使用的人工智能系统而异。 双子座-2.0 在时钟测试中得分最高,而 GPT-01 在日历问题上有 80% 的准确率。
研究负责人、爱丁堡大学信息学院的罗希特-萨克塞纳(Rohit Saxena)说:"大多数人从小就会看时间和使用日历。研究结果凸显了人工智能在完成人类基本技能方面存在的巨大差距。 如果要将人工智能系统成功整合到时间敏感的现实世界应用中,如调度、自动化和辅助技术,就必须解决这些不足。"
爱丁堡大学信息学院的另一位研究员阿里奥-盖马(Aryo Gema)说:"当今的人工智能研究往往强调复杂的推理任务,但具有讽刺意味的是,许多系统在处理较简单的日常任务时仍然相当吃力。"
这些发现将在同行评审的论文中报告,论文将于4月28日在新加坡举行的第十三届国际学习表征会议(ICLR)的大型语言模型推理与规划研讨会上发表。 研究结果目前可在预印本服务器 arXiv上查阅。
这并不是本月第一项表明人工智能系统仍然会犯很多错误的研究。 陶氏数字新闻中心对八个人工智能搜索引擎进行了研究,发现它们有 60% 的时间是不准确的。 最糟糕的是 Grok-3,其准确率高达 94%。