李彦宏说DeepSeek幻觉高,是真的吗?
李彦宏点名批评DeepSeek幻觉高。这回,他真的没错。但大模型的幻觉问题,又远非错与对那么简单。DeepSeek-R1作为今年年初的新晋国产开源大模型,以强大的推理能力和更懂国人的文笔,在苹果美区App免费下载排行榜上力压ChatGPT一头,甚至一度成为“AI”的代言词。
然而,自从R1席卷全网后,关于它经常“胡说八道”的批评就不绝于耳,比如它实在太能编了,让人真真假假分不清。
除了用户端之外,李彦宏及其代表的大厂们也“苦”DeepSeek已久:一方面,大厂不得不依赖DeepSeek的泼天流量导入自身门户入口;另一方面,尽管投入大量人力物力研发深度推理模型,其成果却难以突破用户心智。
在2025百度AI开发者大会的开幕上,李彦宏直接点出全民AI大模型 DeepSeek-R1 的痛点:“只支持单一模态、幻觉率较高、又慢又贵”。一番犀利评论,再度引发了各界对DeepSeek-R1以及大模型“幻觉”的评议。
但出现强烈幻觉的并不止DeepSeek一家,OpenAI在其内部测试中发现:o3/o4-mini虽然全面替换了o1系列,但是幻觉现象越来越强了;国内第一个混合推理模型——阿里通义的Qwen3也在X上被网友指出幻觉现象仍旧大量存在。

关于幻觉的解释有很多,尤其是当推理模型问世后,大家都认为推理模型的思考模式和模型性能攀升后,幻觉就会被消灭,但事实证明:幻觉的生存能力太强了,用户们还是常常被“LLM生编硬造,逻辑闭环的幻觉操作”看呆。
不过,另有一说:大模型的幻觉也算是创作力的副产品,并不完全是桎梏。
今天我们重新讲讲大模型幻觉,看看AI圈子最大的黑箱问题到底解决了没有,解决进度到哪了?
01
李彦宏对DeepSeek-R1的批评确实有据可循。
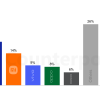
AI数据服务公司Vectara的一项HHEM幻觉评估中,DeepSeek-R1的幻觉率高达14.3%,而其前代基础模型DeepSeek-V3仅为3.9%,R1的幻觉甚至要比V3的幻觉高出4倍。阿里通义的QwQ-32B-Preview的幻觉率则高达16.1%。


更值得注意的是,除了DeepSeek-R1和Qwen系列之外,纵观业内,几乎所有最先进的大模型都遭到了幻觉问题的挑战。一般来说,当新模型出现,幻觉程度就会低于其前身模型,但是这一常理性的现象并不在推理模型上适用。
OpenAI的内部评估系统卡里提供了一个具有代表性的例子:他们设计了一项名为PersonQA的基准测试,用于衡量模型回答人物信息问题的准确性。结果发现,o3在PersonQA上的幻觉率上升到了33%,几乎是被全面替代的前代模型o1(16%)的两倍。轻量版推理模型o4-mini的幻觉率高达48%。

在最新出炉的一版Vectara的幻觉测试中,马斯克 xAI的Grok-3比Grok-2幻觉更严重,GoogleGemini 2.0系列中强调深度推理的Flash-Thinking版本比标准版幻觉问题更突出。
当业界追求更强推理能力的大语言模型时,事实准确性与生成内容一致性几乎无法“鱼与熊掌兼得”。

可见,“幻觉”是当下大模型领域的通病,而DeepSeek-R1正是该问题的显著案例之一。
每当新模型发布时,大家往往先入为主:当推理模型出来后,模型能力大幅度提升,幻觉就会被逐渐消灭;相反,也有一种猜测,推理模型往往要比通用模型幻觉更强。但这些观点其实全都是错的。
比如 o1 相对于 4o 并没有增加太多的幻觉,反过来也可以说,o1并没有大幅度降低幻觉。

o3和o4-mini 幻觉的提升连OpenAI的研究人员在系统卡论文中也说道“仍需继续研究”。可以说,在一定程度上,LLM的幻觉现象仍然是个黑盒,随着模型的不断发展,这层迷雾仍然笼罩在各大基础模型厂商的上空。
广义上,普遍认为像DeepSeek-R1这样的推理模型往往喜欢多轮思考,放大幻觉。
推理模型和深度思考模型通常采用多轮推理或长链式思考策略,通过逐步分解问题、生成中间步骤,最终得出答案。这种设计本来是为了模拟人类复杂的逻辑推理过程。但是,多轮思考也可能导致模型在每一步生成中引入微小的偏差或错误,这些偏差在后续步骤中被放大,促成多米诺骨牌效应的出现。
为什么大家再谈LLM的幻觉?除了百度等厂商为了应对DeepSeek的竞争,破除唯“DeepSeek论”之外,还有一个原因:普通用户们在实际体验中越来越感到恐惧了。
这主要是因为大模型通过大规模训练数据,已经能够构建高度自洽、逻辑几乎闭环的知识体系,模型对语义上下文的理解和生成能力越来越强,幻觉却也越来越真实了。甚至产生了一种“性能与幻觉齐飞”的诡异现象。
可以说,幻觉已经事实上不再是评判模型性能的主要标准了。
大家在日常使用中,肯定都有过这样的体验:AI 杜撰不存在的信源、生成看似真实的学术引用、“现场”构造伪造的网页链接,甚至在长长的思维链里不断“故意迎合”用户,谄媚用户。
如果只是普通的日常使用场景,幻觉现象的隐蔽性并不会降低用户信任。但是,当大模型商业化后,涉及专业领域或复杂问题时,这种不确定性就会引发用户对可靠性的质疑,甚至产生对AI本身的恐惧感。
02
李彦宏2024年曾说,过去24个月里AI行业经历的最大变革之一是大模型基本消除了“幻觉”问题。这一说法一时让各路网友觉得他出现了幻觉。
确实,某些领域(例如文生图、视频等多模态输出方面)随着模型能力的提升,幻觉现象确实已经大幅降低了。
但是,尽管幻觉问题在这些受控场景下大幅改善,在生成长文本或复杂视觉场景时仍未解决。
最直观的例子就是:每当各大厂商推出新一轮的深度思考模型时,都不得不再度老调重弹幻觉问题。可以说,幻觉问题已经被研究了好几年了,但直到今天都没有办法找到一个极好的方式克服幻觉,arXiv上一篇一篇的论文砸向这个黑盒领域。
不过,技术开发者应对 AI 幻觉,也确实有一些手段。目前比较主流的方式还是检索增强生成(RAG),这个方式有点老了但是管用,也是最广的应用思路。

RAG,即在模型回答前先检索资料。英伟达 CEO黄仁勋就强调,要让AI减少幻觉,很简单,“给每个回答加一道规则:先查证再作答”。 具体而言,模型接到问题后,像搜索引擎那样查询权威来源,然后依据检索到的信息作答。如果发现引用的信息与已知事实不符,就丢弃该信息并继续查找 。通过这种方式,模型不再仅凭参数记忆回答,而是有据可依。让模型能够引入最新的网页/数据库内容,在内部机制里学会对不知道的事物说“我确实不知道”。
百度2024年发布的检索增强的文生图技术iRAG,就是为了解决文生图中的幻觉问题,结合了自身的亿级图片资源库,让生成的图片更真实、更贴合现实。
此外,一个更基本的方法是“严格控制训练数据的质量”。
当然,全面的数据治理过于困难,因为互联网语料过于复杂且知识随时间变化,像是“弱智吧”的语料就极难正确过滤。
腾讯此前发布的混元深度思考模型T1,针对长思维链数据中的幻觉和逻辑错误,训练了一个Critic批判模型来进行严格筛选。这种“双重把关”策略——即模型先产出回答,然后再核对其中的关键实体和事实,再决定是否输出,也能在一定程度上降低幻觉率。
即使有上述手段的加持,要彻底根治幻觉仍充满挑战。OpenAI就在最新报告中坦承:“为什么模型规模变大、推理能力增强后幻觉反而更多,我们目前也不完全清楚,还需要更多研究”。
03
幻觉,也并非全无益处。各大厂商正站在一个幻觉与创造力交汇的十字路口:幻觉并非纯粹的缺陷,同样也能带来模型更佳的创造力。
大模型的幻觉一般分为:事实性幻觉和忠实性幻觉。当大模型回答的内容与用户的指令或者上下文信息不一致时,可能就会出现所谓的“灵感”。 不管是违背输入文本,还是违背客观事实, “幻觉”产生的部分往往是模型发挥想象的结果。
有个专业术语叫“外箱式创意”,指的是“跳出既有框架的创作力” ,这正是大模型区别于检索引擎的魅力所在。大家往往潜意识里认为AI做的是低“创意密度“的任务,无法占领诸如科幻文学这类的高创造力写作。
然而,刘慈欣对此有话说。

前段时间,刘慈欣在一次采访中说他曾拿自己所写的长篇中的一章发给 DeepSeek,让它在这个基础上续写。结果发现它写出来的东西,甚至要比自己写得好。这甚至让他有了一种很大的失落感。
但是,刘慈欣本人仍喜爱DeepSeek:“为什么呢?因为我想到,由于人脑的生物特性,有一些没法冲破的认知极限,但 AI 却有可能突破。如果它真的可以突破极限,那么我甘心乐意被 AI 取代。当然,现在它还做不到。未来的路还很遥远。”
OpenAI CEO奥特曼也曾提及AI的幻觉特性并非全然是坏事,在创作领域仍有积极意义。这也可能是未来LLM的一个方向。
面对几乎成为大模型固有特性的幻觉现象,要低到什么地步,我们才可以接受?
这没有固定的答案,而是依赖于应用场景。在需要精准性的高风险or涉及伦理的领域里,LLM 的幻觉固有特性几乎断绝了商业空间。
从哲学上看,这反映了人类对技术的期望:AI应比人类更可靠。折射出人类对 LLM 的角色定位,如果将 AI 仅仅视作锄头而已,那么AI几乎永不可能达到这样的标准。如果将 AI 视作天然具有幻觉特性的工具,接受“幻觉”是AI的固有特质,就要赋予AI区分虚构与现实的能力,让它在需要的时候学会说“我不知道”。
或许我们也应该换种思路研究AI。