GPT-5训练背后隐藏大佬:靠一篇博客入职OpenAI
今天,AI云服务商Hyperbolic的联合创始人兼CTO Yuchen Jin在社交平台X上曝料:研究员Keller Jordan仅凭一篇博客文章就加入了OpenAI,并可能正用博客提及的神经网络隐藏层的优化器Muon训练GPT-5。

“许多博士(包括以前的我)都陷入了这样一个误区:认为在顶级会议上发表论文才是最终目标。但发表论文≠影响力。Muon只作为一篇博客文章发布,它让Keller加入了OpenAI,他现在可能正在用它训练GPT-5。”Yuchen Jin说。

▲Yuchen Jin的X推文及Yuchen Jin的自述
Yuchen Jin提及的这篇博客发布于2024年12月,题为《Muon:神经网络隐藏层的优化器(Muon: An optimizer for hidden layers in neural networks)》。

博客地址:https://kellerjordan.github.io/posts/muon/
从职场社交平台领英可知,Keller Jordan正是在2024年12月加入OpenAI,由此我们也可以推测他正是凭去年12月发布的一篇博客,成功进入了如日中天的头部大模型企业。

这篇博客厉害在那儿?Muon凭什么成为OpenAI的敲门砖?让我们从这篇博客文章内容说起。
一、Muon定义:一个神经网络隐藏层的优化器
Muon是神经网络隐藏层的优化器。它被用于NanoGPT和CIFAR-10的快速运行,刷新了当时训练速度的记录。
Keller Jordan的博客文章主要关注Muon的设计。首先他定义了Muon并概述其在当时已取得的实证结果;然后他详细讨论了Muon的设计,包括与先前研究的联系以及对其工作原理的最佳理解;最后他讨论了优化研究中的证据标准。
具体来说,Muon是一个针对神经网络隐藏层二维参数的优化器,其定义如下:

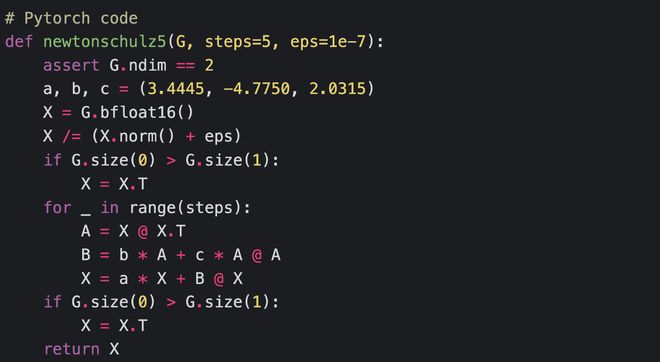
其中“NewtonSchulz5”定义为以下Newton-Schulz矩阵迭代:
使用Muon训练神经网络时,应使用AdamW等标准方法优化网络的标量和矢量参数以及输入层和输出层。Muon可用于四维卷积参数,方法是将其最后三个维度展平。
Muon取得了以下实证成果:
1、将CIFAR-10上的训练速度记录提高到94%准确率,从3.3秒提高到2.6秒。
2、将FineWeb(一项称为NanoGPT快速运行的竞赛任务)上的训练速度记录提高至3.28 val loss,提高了1.35倍。
3、在扩展到774M和1.5B参数的同时,继续显示训练速度的提升。
4、在HellaSwag上用10个8xH100小时训练了一个1.5B参数转换器,使其达到GPT-2 XL级别的性能。使用AdamW达到相同结果则需要13.3小时。
以下是针对NanoGPT快速运行的不同强力优化器的比较:

▲按样本效率比较优化器(可复现日志:https://github.com/KellerJordan/modded-nanogpt/tree/master/records/102924_Optimizers)

▲按挂钟时间比较优化器
此外,以下是Muon和AdamW在训练15亿参数语言模型时的对比。两个优化器均已进行调整。

▲Muon与AdamW在15亿参数短时间训练中的对比(可复现日志:https://github.com/KellerJordan/modded-nanogpt/tree/master/records/102024_ScaleUp1B)
二、Muon设计:牛顿-舒尔茨迭代法作为后处理步骤
Muon通过采用SGD-momentum生成的更新来优化二维神经网络参数,然后在将它们应用于参数之前,对每个更新应用 Newton-Schulz (牛顿-舒尔茨迭代法,简称NS)迭代作为后处理步骤。
NS迭代的作用是使更新矩阵近似正交化,即应用下列操作:

换句话说,NS迭代实际上用最接近的半正交矩阵替换了SGD-momentum的更新矩阵。
为什么正交化更新可行?出于实证研究的动机,作者基于人工检验观察到,SGD-momentum和Adam对基于Transformer的神经网络中的二维参数产生的更新通常具有非常高的条件数。也就是说,它们几乎是低秩矩阵,所有神经元的更新仅由少数几个方向主导。
作者推测,正交化有效地增加了其他“稀有方向”的规模,这些方向在更新中幅度较小,但对学习仍然很重要。
除了NS迭代之外,还有其他几种方法可以对矩阵进行正交化。但作者没有使用其中两种方法,他是如何排除的?
一个是SVD方法,它太慢了,所以作者没有使用它。另一个是Coupled Newton iteration (耦合牛顿迭代法),它必须至少以float32精度运行才能避免数值不稳定,这导致它在现代GPU上运行速度较慢,所以作者也没有采用。
相比之下,作者发现NS可以在bfloat16中稳定运行,因此选择它们作为正交化更新的首选方法。
在Keller Jordan的实验中,当使用具有调整系数的Muon来训练Transformer语言模型和小型卷积网络时,只需运行5步NS迭代就足够了。
此外,Keller Jordan还分析了Muon的运行时间和内存要求。对于典型的语言训练场景,无论规模大小,Muon的FLOP开销都低于1%。
三、Muon实证考虑:批判糟糕的基线,提出新方法
根据设计,Muon仅适用于二维参数,以及通过展平的卷积滤波器,因此网络中其余的标量和矢量参数必须使用标准方法(例如 AdamW)进行优化。
根据经验,Keller Jordan发现使用AdamW优化输入和输出参数也很重要,即使这些参数通常是二维的。具体来说,在训练Transformer时,应该将AdamW用于嵌入层和最终分类器头层,以获得最佳性能。嵌入层的优化动态应该与其他层不同,这遵循模块化范数理论。输出层的这种动态也不同,这似乎并非来自理论,而是由经验驱动的。
另一个纯经验性的结果是,在他们测试的所有案例中,使用 Nesterov式动量对Muon的效果都比普通的SGD动量略好。因此,他们在公开的Muon实现中将其设为默认设置。
第三个结果是,如果将Muon分别应用于变压器的Q、K、V参数,而不是一起应用于变压器,则Muon可以更好地优化变压器,因为对于将QKV参数化为输出被分割的单个线性层的变压器实现,默认做法是将它们一起应用。
Keller Jordan认为,神经网络优化研究文献目前大多充斥着一堆已死的优化器,它们声称能够击败AdamW,而且往往以巨大的优势获胜,但却从未被社区采用。鉴于业界在神经网络训练上投入了数十亿美元,并渴望降低成本,他们可以推断,问题出在研究界,而非潜在的采用者。
Keller Jordan犀利地提出:这项研究出了问题。仔细研究每篇论文后,他们发现最常见的罪魁祸首是糟糕的基线:论文在将其与新提出的优化器进行比较之前,往往没有充分调整AdamW基线。
发表声称有巨大改进但无法复制/达到宣传效果的新方法,浪费了大量个人研究人员和小型实验室的时间、金钱和士气,他们每天都在为复制和构建此类方法的失败而感到失望。
为了纠正这种情况,Keller Jordan建议采用以下证据标准:研究界应该要求,只要有可能,神经网络训练的新方法就应该在竞争性训练任务中取得成功。
竞争性任务通过两种方式解决了基线欠调问题。首先,竞争性任务的基线是先前的记录,如果该任务很受欢迎,则很可能已经经过了良好的调整。其次,即使在先前记录未经过良好调整的不太可能发生的情况下,也可以通过新的记录进行自我修正,将训练恢复到标准方法。
结语:全新优化器或成为GPT-5中的重要技术
通过定义、拆解设计及实证研究,Keller Jordan发现了Muon神经网络隐藏层的优化器具备优于AdamW的效率。通过最新曝料可知,这一技术很有可能成为OpenAI正在研究的GPT-5的重要部分。
Keller Jordan也提出了一些尚未解决的问题。包括:Muon可以扩展到更大规模的训练吗?是否有可能在大型GPU集群中正确分布Muon使用的Newton-Schulz迭代?Muon是否仅适用于预训练,而不适用于微调或强化学习工作负载?或许在GPT-5的研究中,作者已经知道了这些问题的答案。
来源:X平台、keller Jordan博客