Cloudflare推出AI爬虫红黑榜 字节跳动因不遵守抓取协议直接垫底
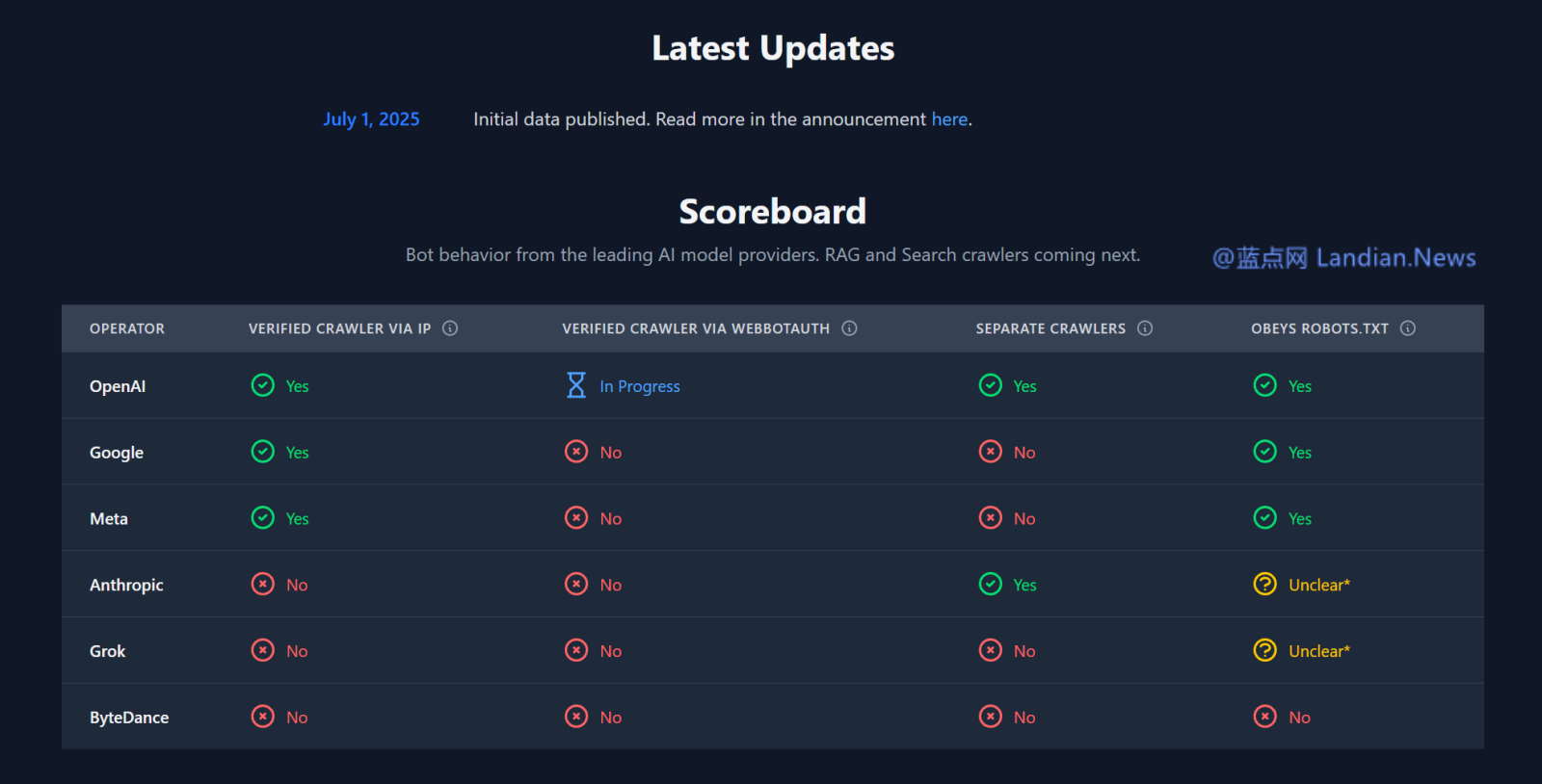
网络服务提供商 Cloudflare 日前推出 AI 爬虫红黑榜,通过四个维度对人工智能公司的爬虫进行验证、识别和统计,首批被评测的爬虫包括 OpenAI、Google、Meta、Anthropic、xAI 和字节跳动。
目前评价比较优秀的只有 OpenAI 的 ChatGPT 系列爬虫,而垫底的则是 xAI Grok 爬虫和字节跳动爬虫,其中字节跳动爬虫因各种项目全部没有达标而排在末尾。
接下来这个红黑榜网站还会记录 RAG 和搜索引擎爬虫并给出得分,后续也会陆续增加更多爬虫的识别和评分,而网站则可以根据红黑榜决定是否要通过更激进的手段屏蔽这些爬虫 (毕竟 robots.txt 已经没啥用)
点击这里查看最新的红黑榜排名:https://goodaibots.com/
四个维度如下:
爬虫 IP 是否已验证:AI 公司是否已经公布爬虫的 IP 地址段,公布后有助于准确识别避免其他爬虫冒充
是否通过 WebBotAuth 验证:WebBotAuth 是一种通过加密签名验证爬虫身份的协议,比通过 IP 识别更准确
爬虫是否分离:分离爬虫很重要,因为网站可以根据不同类型的爬虫做出相应处理,例如有爬虫专门为了抓取数据就可以直接屏蔽,而有些爬虫则为了搜索引擎使用可能可以提供流量,这种爬虫可以被保留抓取。
是否遵守 robots.txt 协议:该协议用来指示爬虫是否允许抓取以及允许抓取哪些路径,这是个行业约定俗成的规范,部分爬虫完全不遵守该协议
字节跳动的爬虫每天会在整个互联网上抓取数据但却不遵守 robots.txt 协议,字节跳动也没有公开 IP 地址段导致网站管理员无法判断自称 Bytespider 是否真的来自字节跳动。
蓝点网此前就因为字节跳动的爬虫高频次抓取内容且不遵守 robots.txt 协议而不得不直接在服务器配置文件中阻断 UA 包含任何 Bytespider 字符串的请求以减少服务器开支。
不过除了字节跳动外其他爬虫也好不到哪去,例如 Anthropic 和 xAI Grok 的爬虫可能也不遵守 robots.txt 协议,由于这些公司都没有提供 IP 地址段可以用来验证爬虫,所以 Cloudflare 无法判断它们是否遵守 robots.txt 协议。