大语言模型生成的法律文件正在扰乱司法系统
大型语言模型已被用于学校作弊和新闻报道中的虚假信息传播。如今,它们正悄悄潜入法庭,加剧法官在繁重案件中面临的虚假诉讼,给本已捉襟见肘的司法体系带来了新的风险。
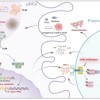
Ars Technica 最近的一篇报道详细介绍了佐治亚州上诉法院的一项裁决,凸显了美国司法体系面临的一个日益严重的风险:人工智能生成的幻觉潜入法庭文件,甚至影响司法裁决。在这起离婚纠纷中,丈夫的律师提交了一份命令草案,其中充斥着对不存在案例的引用——这些案例很可能是由 ChatGPT 等生成式人工智能工具编造的。初审法院签署了这份文件,随后做出了有利于丈夫的裁决。
直到妻子上诉,这些伪造的传票才被曝光。由杰夫·沃特金斯法官领导的上诉小组撤销了该命令,指出这些虚假案件削弱了法院审查判决的能力。沃特金斯直言不讳,称这些传票可能是人工智能生成的幻觉。法院对丈夫的律师处以2500美元的罚款。
这听起来可能只是个例,但今年2月,一位律师在类似情况下被罚款1.5万美元。法律专家警告称,这很可能预示着未来可能发生的事件。众所周知,生成式人工智能工具很容易以令人信服的自信伪造信息——这种行为被称为“幻觉”。专家表示,随着人工智能越来越容易被不堪重负的律师和自行代理的诉讼当事人所接受,法官将越来越多地面临充斥着虚假案件、虚假判例以及伪装成合法的混乱法律推理的诉讼文件。
司法体系本已捉襟见肘,这进一步加剧了这个问题。在许多司法管辖区,法官经常对律师起草的判决不假思索地批准。然而,人工智能的使用则加剧了这一风险。
上诉法院关于虚假法律引证的意见
前德克萨斯州上诉法院法官、法律学者约翰·布朗宁 (John Browning) 表示:“我可以想象,在审判法官处理大量案件的情况下,可能会出现这种情况。”他撰写了大量有关法律中的人工智能伦理的文章。
布朗宁告诉 Ars Technica,他认为这类错误“极有可能”会变得更加普遍。他和其他专家警告称,法院,尤其是基层法院,尚未做好应对这种人工智能驱动的胡乱做法的准备。目前只有密歇根州和西弗吉尼亚州这两个州要求法官在涉及人工智能时保持基本的“技术能力”。一些法官已经完全禁止使用人工智能生成的文件,或强制披露人工智能的使用情况,但这些政策并不完善、前后矛盾,而且由于案件数量庞大,难以执行。
与此同时,人工智能生成的文件并不总是显而易见的。大型语言模型通常会编造听起来很逼真的案件名称、似是而非的引证,以及听起来很正式的法律术语。布朗宁指出,法官可以留意一些蛛丝马迹:错误的法庭记录员、像“123456”这样的占位符案件编号,或者生硬的公式化语言。然而,随着人工智能工具变得越来越复杂,这些蛛丝马迹可能会逐渐消失。
普林斯顿大学北极星实验室的彼得·亨德森等研究人员正在开发追踪人工智能对法庭文件影响的工具,并倡导开放合法案例库,以简化核实工作。其他人则提出了一些新颖的解决方案,例如“赏金制度”,奖励那些在虚假案件落网之前发现它们的人。
就目前而言,佐治亚州的离婚案件是一个警示——不仅关乎粗心的律师,也关乎法院系统可能不堪重负,无力追踪每一份法律文件中人工智能的使用情况。正如沃特金斯法官警告的那样,如果人工智能产生的幻觉继续不受控制地潜入法庭记录,它们可能会削弱人们对司法系统本身的信心。