云服务可靠性再敲警钟 Cloudflare披露5小时中断事故详情
云服务可靠性再次敲响警钟。当地时间11月18日,互联网基础设施巨头Cloudflare发生服务中断,导致全球多家主要网站无法访问。根据网站故障追踪机构Downdetector(该网站自身也一度无法被部分用户访问),Anthropic的Claude聊天机器人、特朗普的Truth
Social以及马斯克旗下社交媒体平台X等都受到了影响,美国新泽西公交系统的部分数字服务也因中断而瘫痪。
同时,OpenAI的状态页面在当天晚些时间也显示,ChatGPT及其Sora短视频应用在因“第三方服务提供商”问题出现故障后已完全恢复。
Cloudflare自2009年开始组建于哈佛大学,并在2010年正式推出首批测试版,2019年在纽约证券交易所上市,目前已服务30%的财富1000强公司。其核心服务包括DDoS(防御分布式拒绝服务),这种攻击通过海量虚假请求淹没目标网站致其瘫痪。据外媒报道,该公司流量管理及安全防护服务覆盖约20%的互联网流量。
受事件影响,截至美股18日收盘,Cloudflare股价下跌2.83%。
Cloudflare联合创始人、CEO马修·普林斯(Matthew Prince)表示,此次是Cloudflare自2019年以来最严重的中断,“今天这样的中断是不可接受的……我谨代表Cloudflare全体团队,为给互联网造成的困扰道歉。”
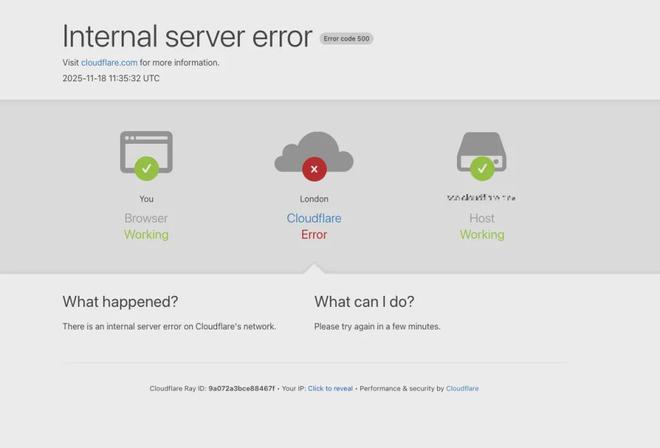

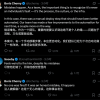
受影响网站出现的报错信息
Cloudflare CTO戴恩·克内切特(Dane Knecht)也在社交平台发文,对故障深表歉意,表示此次事故系公司支撑发现僵尸程序缓解功能的某个服务中存在潜在缺陷,在进行常规配置变更后开始崩溃,进而引发网络及其他服务的大范围退化,而非遭受攻击所致。
克内切特表示,此次故障及其造成的影响与恢复时长都是不可接受的。“我们已着手开展工作确保此类事件不再发生,但深知确实造成了实际影响。客户给予我们的信任是最宝贵的财富,我们将不惜一切代价重新赢回这份信任”。

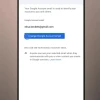
Cloudflare CTO戴恩·克内切特推文截图
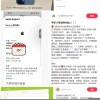
当地时间11月19日一早,Cloudflare发布完整报告,详细描述了持续近5个小时的事件经过:当地时间18日上午11:28开始出现影响,并在客户HTTP流量上首次观察到错误;14:30主要影响解决,下游受影响服务开始观察到错误减少,大多数服务开始正确运行;17:06所有下游服务重启,所有操作完全恢复,影响结束。
Cloudflare表示,在故障发生时,公司“最初错误地怀疑所见症状是由超大规模DDoS攻击引起”,之后正确识别出了核心问题——底层生成此文件的ClickHouse查询行为发生了变化,文件包含大量重复的“特征”行,致使Bot Management模块触发错误,导致核心代理系统对任何依赖于该模块的流量返回了HTTP 5xx错误码,同时,当包含超过特征数量限制的错误文件传播到服务器时,触发了Cloudflare的系统恐慌。此外,这也影响了该公司客户依赖核心代理的Workers KV和Access两项服务。
随后,Cloudflare通过停止生成和传播错误的特征文件,并手动将一份已知良好的文件插入特征文件分发队列来解决了问题,然后强制重启核心代理,5xx错误码数量此后恢复正常。

Cloudflare此次中断事故时间线
Cloudflare表示,“鉴于Cloudflare在互联网生态系统中的重要性,我们任何系统的任何中断都是不可接受的”,对给客户和整个互联网带来的影响深表歉意。
Cloudflare称,公司已开始着手研究如何加强系统以防未来发生类似故障,包括强化Cloudflare生成的配置文件的摄入处理,采用与处理用户生成输入相同的方式;为功能启用更多全局紧急停止开关;消除核心转储或其他错误报告耗尽系统资源的可能性;审查所有核心代理模块中错误条件的故障模式等措施。
据外媒报道,此次事故发生前不到一个月,亚马逊云服务也刚刚经历过导致多项网络服务瘫痪的整日故障,随后微软Azure云服务及365办公套件也曾出现全球性中断。
而早在2024年7月,网络安全公司CrowdStrike就曾因有缺陷的软件更新引发大规模系统故障,造成航班停飞、金融服务受阻及医院推迟手术等连锁反应。