GPT-5.2降智遭全网差评 OpenAI仍未摆脱被动局面
年终AI大戏,OpenAI败给了Google?GPT-5.2上线48小时,全网吐槽一大片。第三方数据实证,Gemini 3 Pro才是真正的王者。OpenAI打出了GPT-5.2这张“年度王牌”,却没有打赢Google...

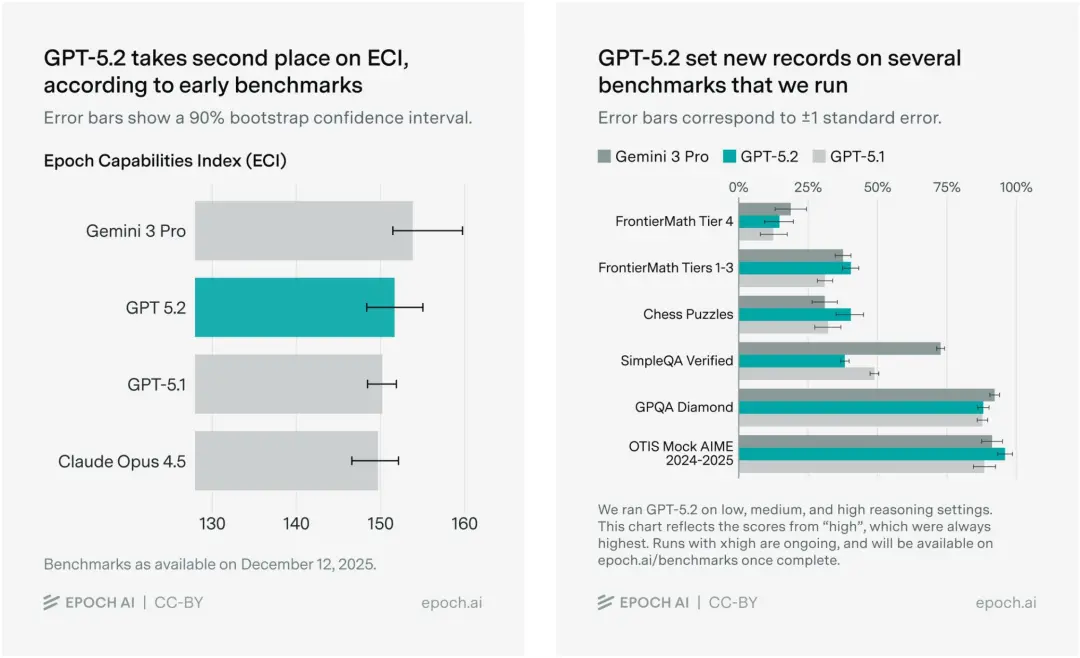
Epoch AI最新报告,GPT-5.2的能力指数(ECI)得分152,仅次于Gemini 3 Pro。

在多项基准测试中,GPT-5.2的实力并没有“全线霸榜”。
在由陶哲轩联手百位数学家出的考题——FrontierMath中,GPT-5.2仅在T1-3级中霸榜,T4还是Gemini 3的高地。
另外,在国际象棋Chess Puzzles中,GPT-5.2拿下了第一的成绩。
唯一例外的是,在SimpleQA Verified上,GPT-5.2都不及GPT-5.1,意味着迭代后的可信度更差了。
不仅如此,多个第三方基准评测显示,GPT-5.2远不及预期,没有打败Gemini 3。
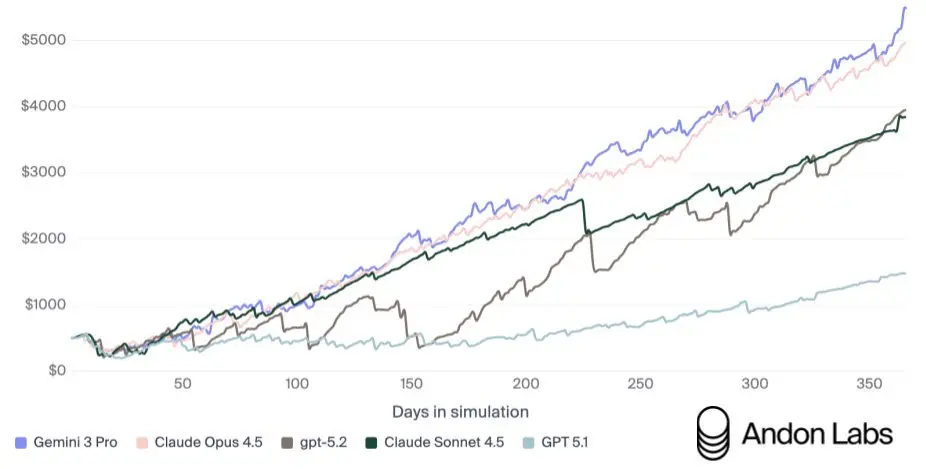
包括OCR-Arena、simple-bench、Live-Bench上,GPT-5.2甚至都排在了Claude Opus 4.5之后。
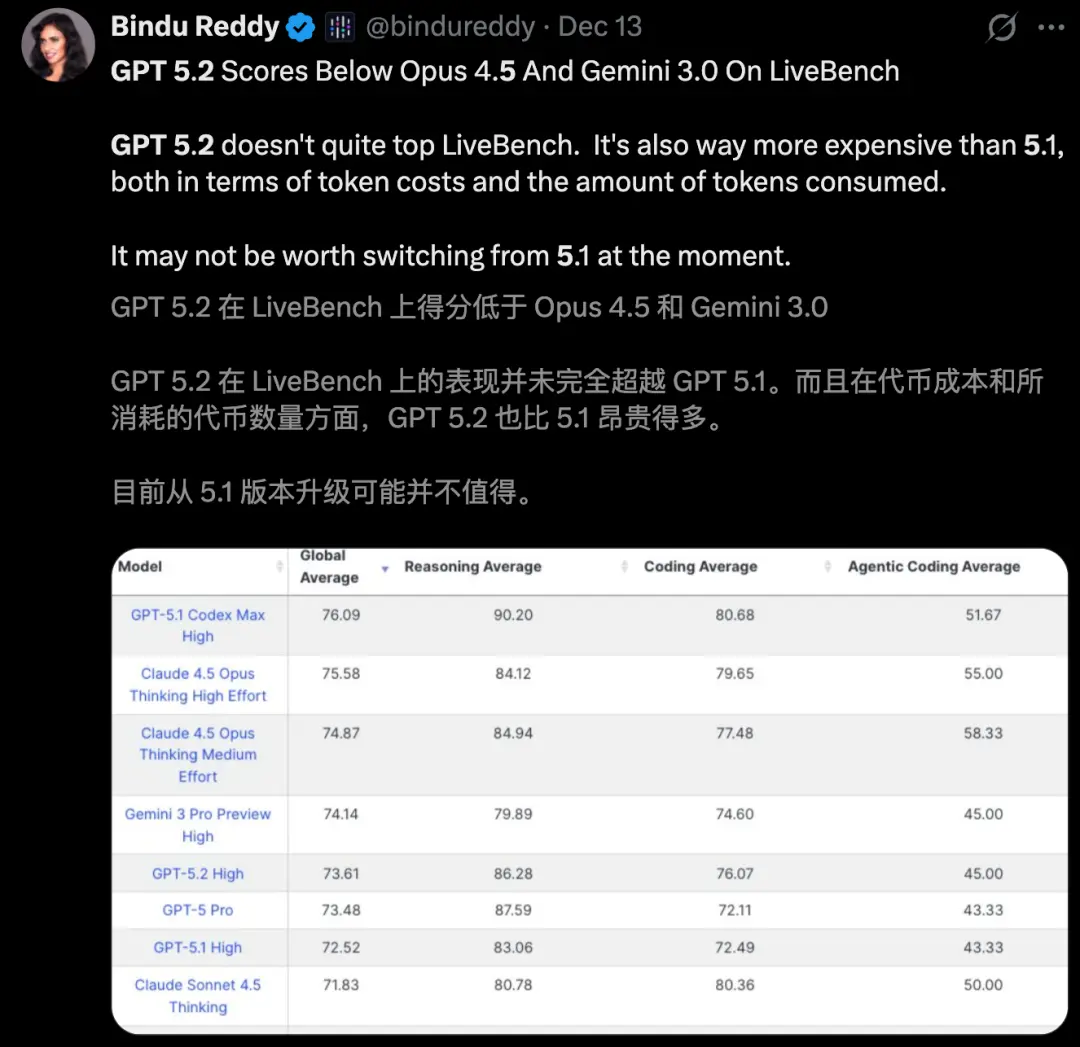
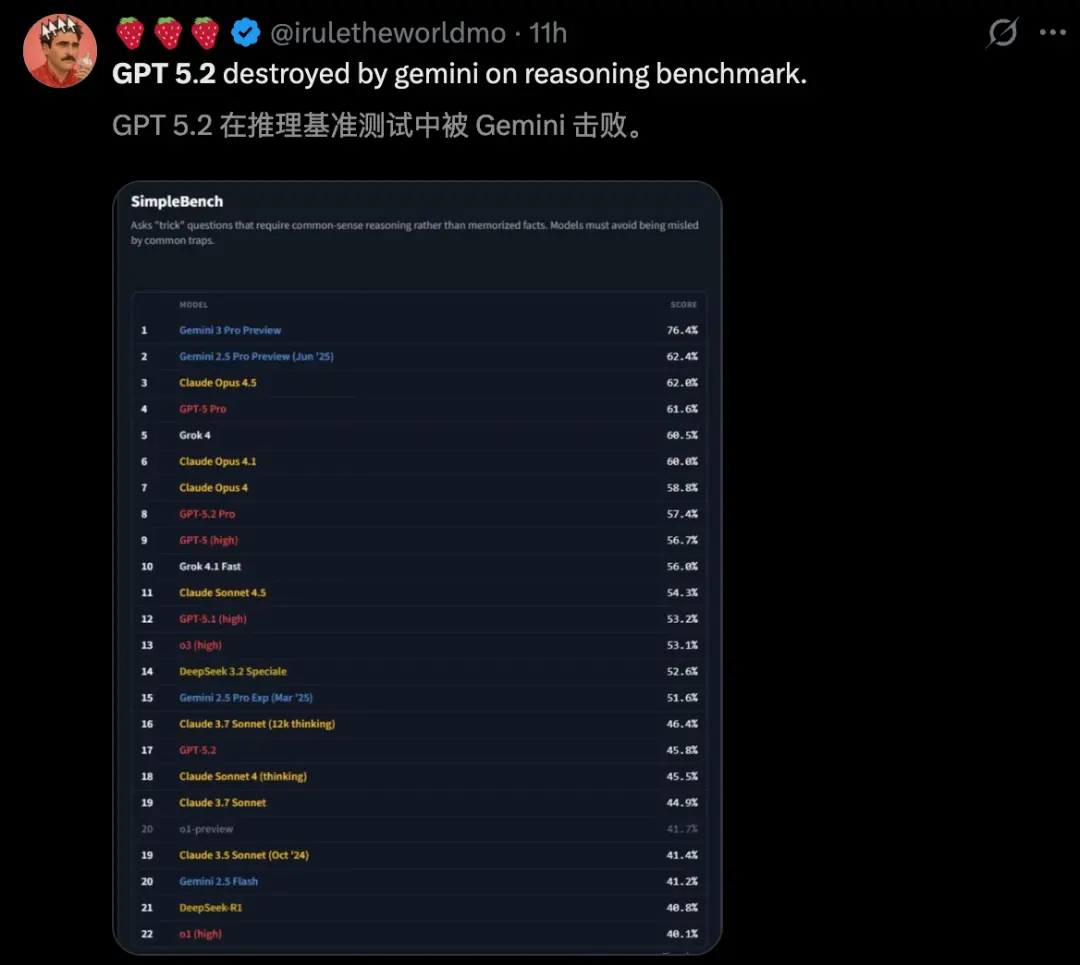
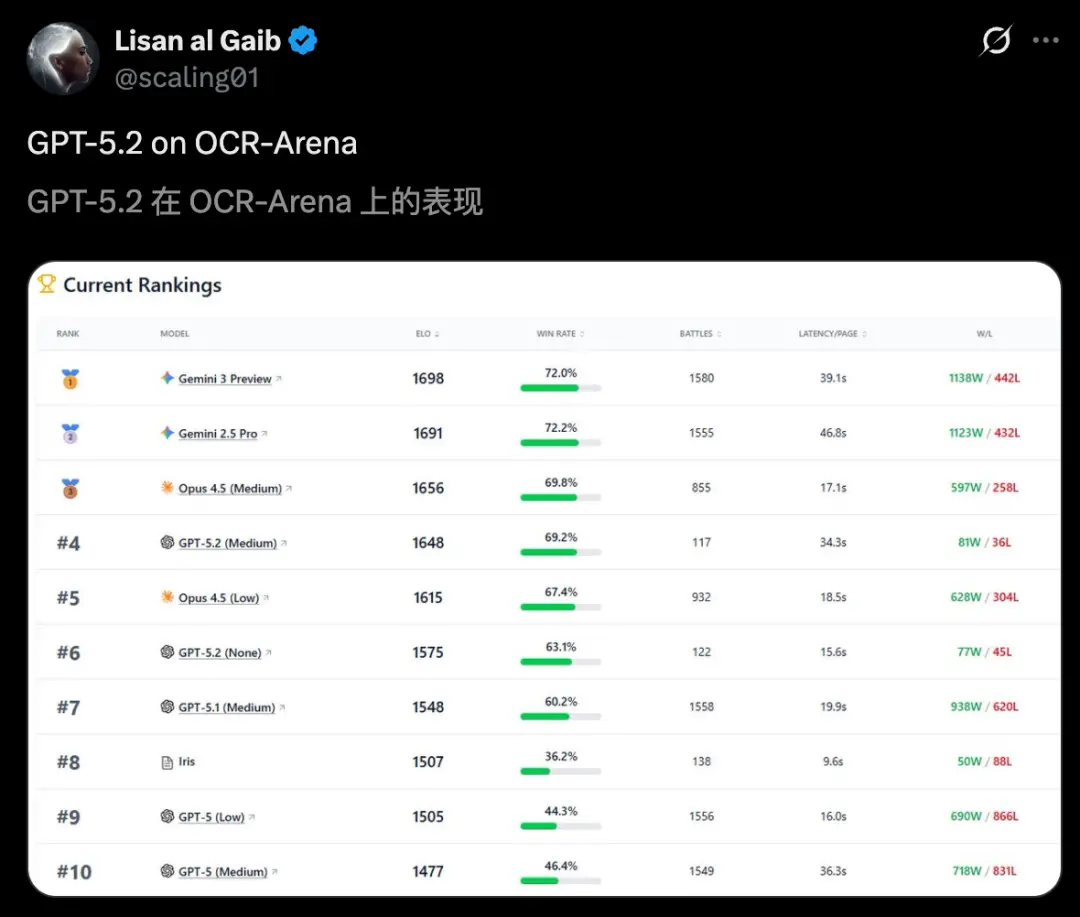
发布仅两天,GPT-5.2水花不大,反而圈子里开发者吐槽的不少。
为了打赢这场硬仗,OpenAI拉响“红色警报”,把改进ChatGPT事项提到了优先级。
更极端的是,内部直接停掉了AGI的研发,Sora也暂停了八周,显然摆出了破釜沉舟的姿态。
可是呢,在业界来看,OpenAI至今仍未摆脱被动的局面。
GPT-5重度用户站出来发声,“GPT-5.2距离成为一块石头也不远了”。

年终之战,OpenAI败了?
三年前,Google因错失先机,被OpenAI ChatGPT抢尽了风头。
昨天,Google创始人谢尔盖·布林重返斯坦福演讲,现场公开承认曾经的“最大失误”:
我们搞砸了——太怕AI说错话
掉一个时代。
如今,凭借Gemini 3 Pro+Nano Banana Pro,Google已重回AI浪潮之巅。
风水轮流转。这一次,轮到了OpenAI,却在2025年这场关键战役中自乱阵脚。

上线首日,奥特曼激动宣称,API调用量就超过了万亿token,且增长速度极快
此前Information爆料,GPT-5.2,代号大蒜(Garlic),原计划在明年初亮相。
整个硅谷,曾透露了一种风声——OpenAI预训练终结了,甚至GPT-5.1可能基于4o后训练而来,由此提升不大。
确实如此,在预训练上,OpenAI遇到了Scaling瓶颈。

预训练Scaling,或许不大
在GPT-5.2(大蒜)研发上,原爆料称,OpenAI解决了预训练环节遇到的一些关键问题——
改进之前“最好的”且“体量大得多”的预训练模型。
在内部,OpenAI整合了在开发“Shallotpeat”期间修复的Bug,积累了许多预训练的经验。
正如Information所言,最关键的突破发生在“预训练阶段”。

但以上的一切信息,都是新闻报道。OpenAI究竟在预训练上,是否实现了重大突破,难以得知。
但从官方全线击败Gemini 3基准上可以猜测,GPT-5.2在预训练方面取得了一定的改进。

但是从第三方评测和网友反馈中,GPT-5.2在底层技术迭代上,没有实现突破式的进展。


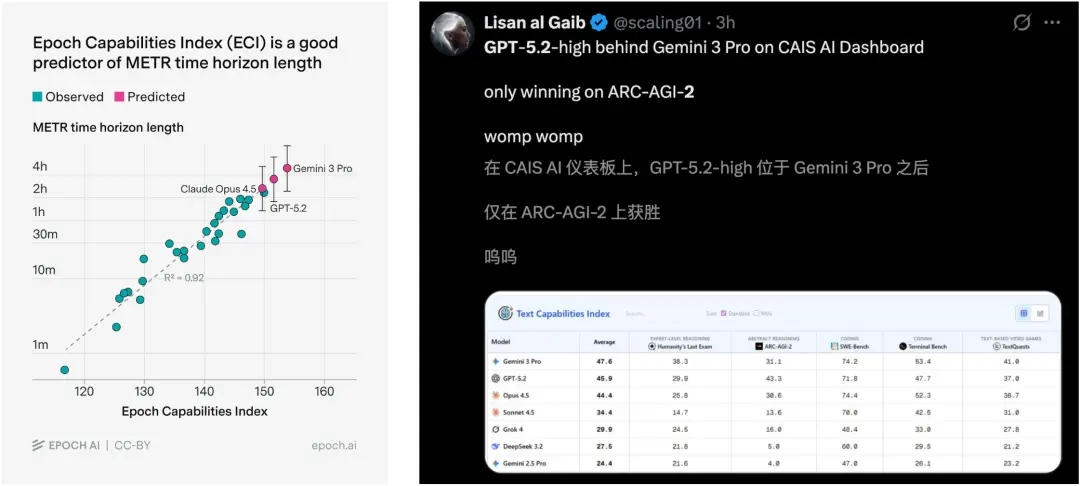
Epoch AI另一项评估中,顶尖AI大模型在长程任务的性能,Gemini 3依旧是最强的——
Gemini 3 Pro:4.9小时
GPT-5.2:3.5小时
Opus 4.5:2.6小时
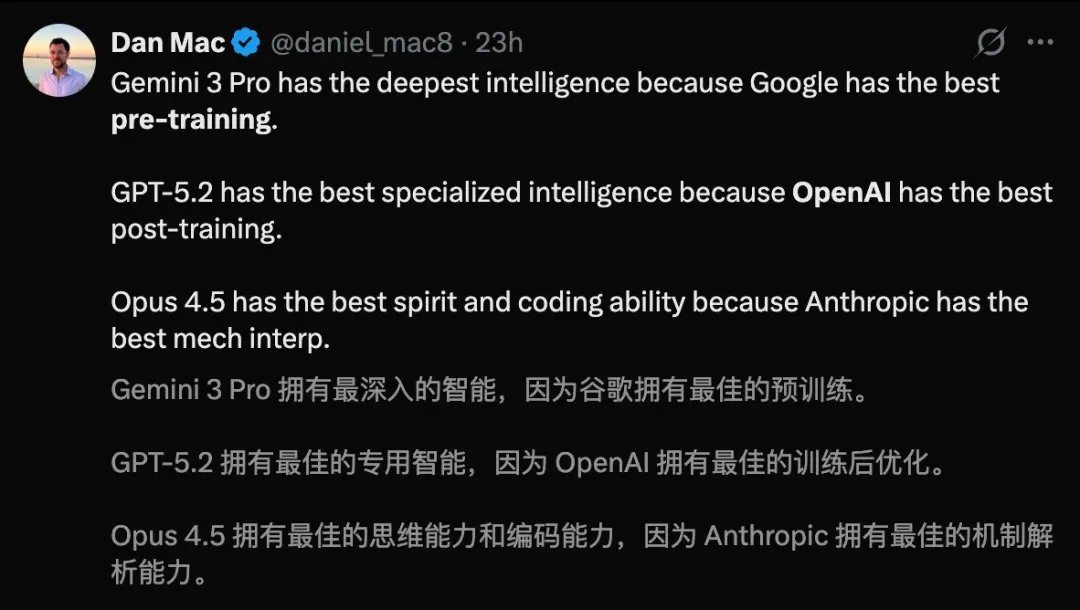
正如工程师Dan Mac所言,Gemini 3 Pro之所以拥有更深入的智能,是因为Google预训练最强。
而GPT-5.2拥有最好的专用智能,是OpenAI在后训练上优化的结果。
明年初,还有更大的
纽约时报最新爆料称,接下来几周,OpenAI将继续把重点放在ChatGPT优化上。
他们正在筹备明年初的一次更大规模发布。

在内部,OpenAI的2B和2C方向的“双线作战”模式并行。
OpenAI也在推进其他项目,包括广告和电商相关尝试。
尽管被吐槽,他们仍在探索“更克制”的方式,比如通过ChatGPT聊天完成购物,并从交易中抽成。
在企业市场方面,OpenAI正将支撑ChatGPT的同一套AI技术引入企业软件领域。

数据显示,每周使用ChatGPT的用户超过8亿人,市场份额约为76%。
一位AI大佬说,“消费级AI几乎就等同于OpenAI,如果失去了这一点,这家公司就不会有现在这样的价值”。
然而,在过去12个月里,全世界多家AI初创已开发出能够匹敌,甚至在某些方面超越OpenAI领先模型的技术。
GoogleGemini 3 Pro的出世,对OpenAI业务来说着实是一次不小的打击。

Gemini 3力压GPT-5.2,
OpenAI只是虚晃一枪?
就从网友实测角度来说,GPT-5.2还有很大的改进空间。
有网友忍无可忍,直言OpenAI完全没脑子:
GPT-5.2语气冰冷,堪比北极,完全无视用户体验,“一味地不断倒退,把原本正常、自然的语言越改越离谱,最后变成一堆辱骂和说教,然后还把这当成某种胜利来兜售。”
OpenAI活该被Gemini 3吓得够呛。

比如,在视觉推理上,Gemini 3 Pro完全碾压GPT-5.2。
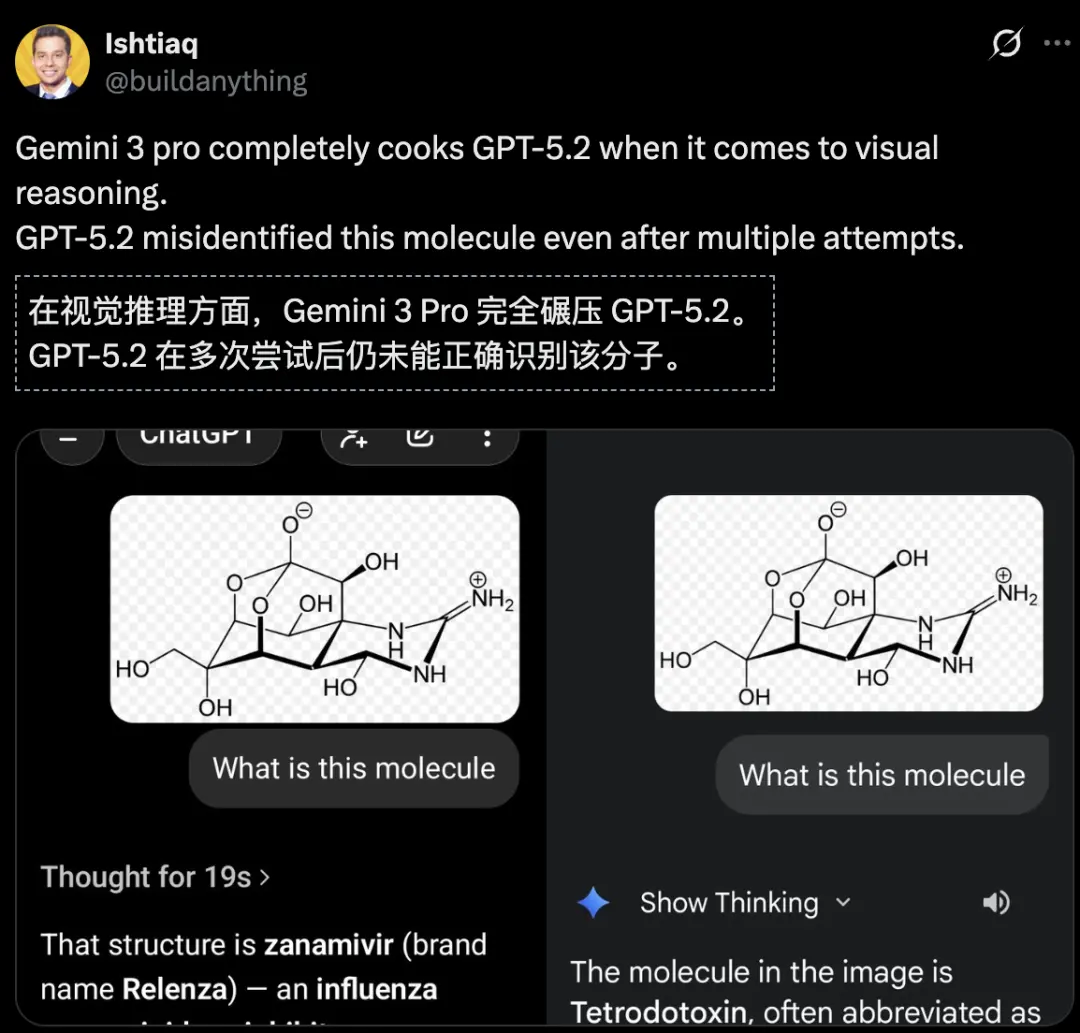
在3D模型生成上,GPT-5.2速度更慢、成本更高,总体表现不如Gemini 3。

在越界小说生成上,GPT-5.2垫底,不如Gemini 3 Pro、Claude 4.5 Opus、Grok 4:
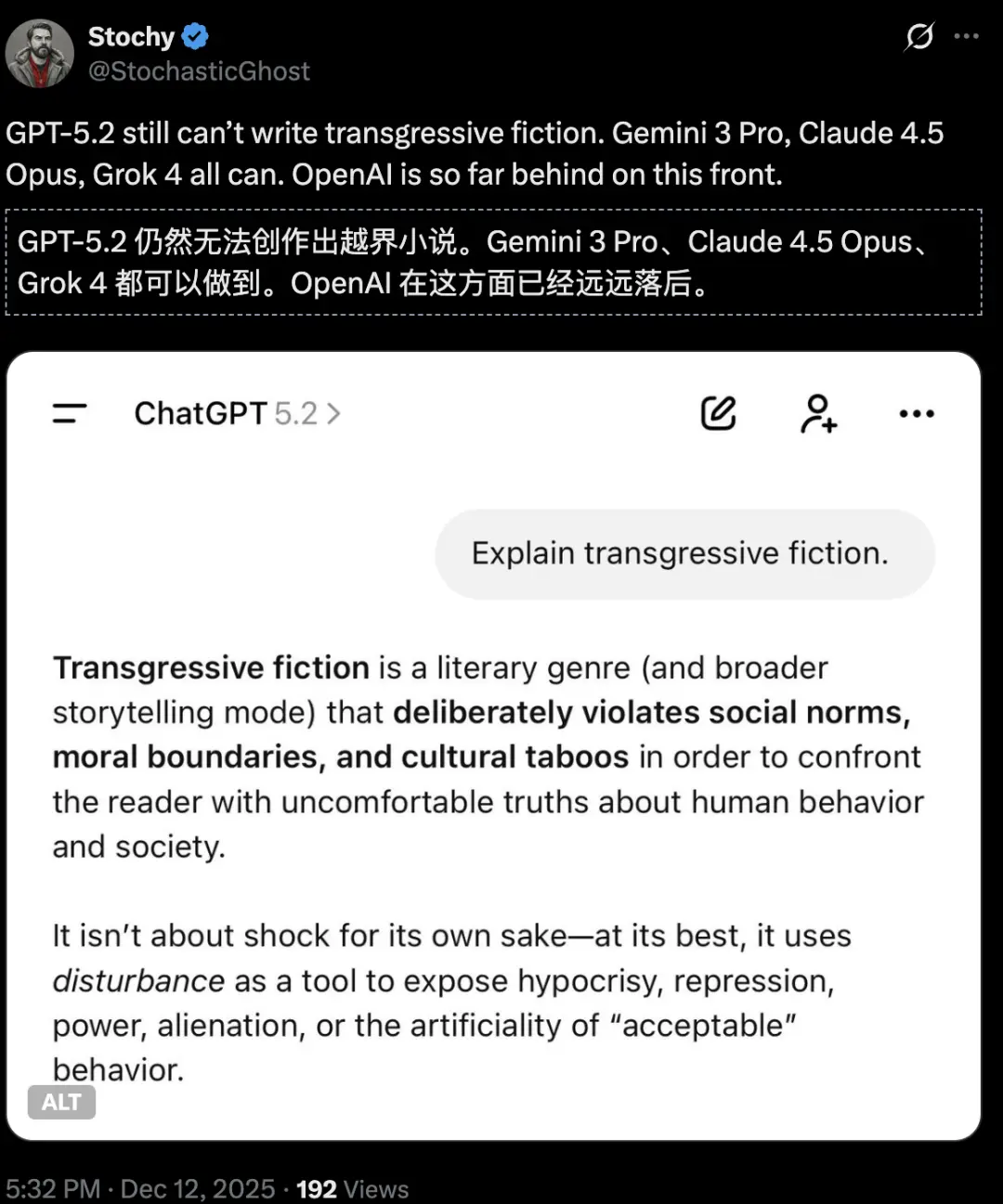
越界小说是一种文学类型,以渴望冲破社会桎梏与基本规范的角色为核心。
这类作品通常涉及一系列禁忌主题、黑暗题材与极端议题。
在前端代码生成上,Gemini 3大幅领先,GPT-5.2仍望尘莫及。

在相同提示下,在健身仪表盘首页设计上,53万多人讨论了Gemini 3 、GPT-5.2和Claude Opus 4.5的设计,
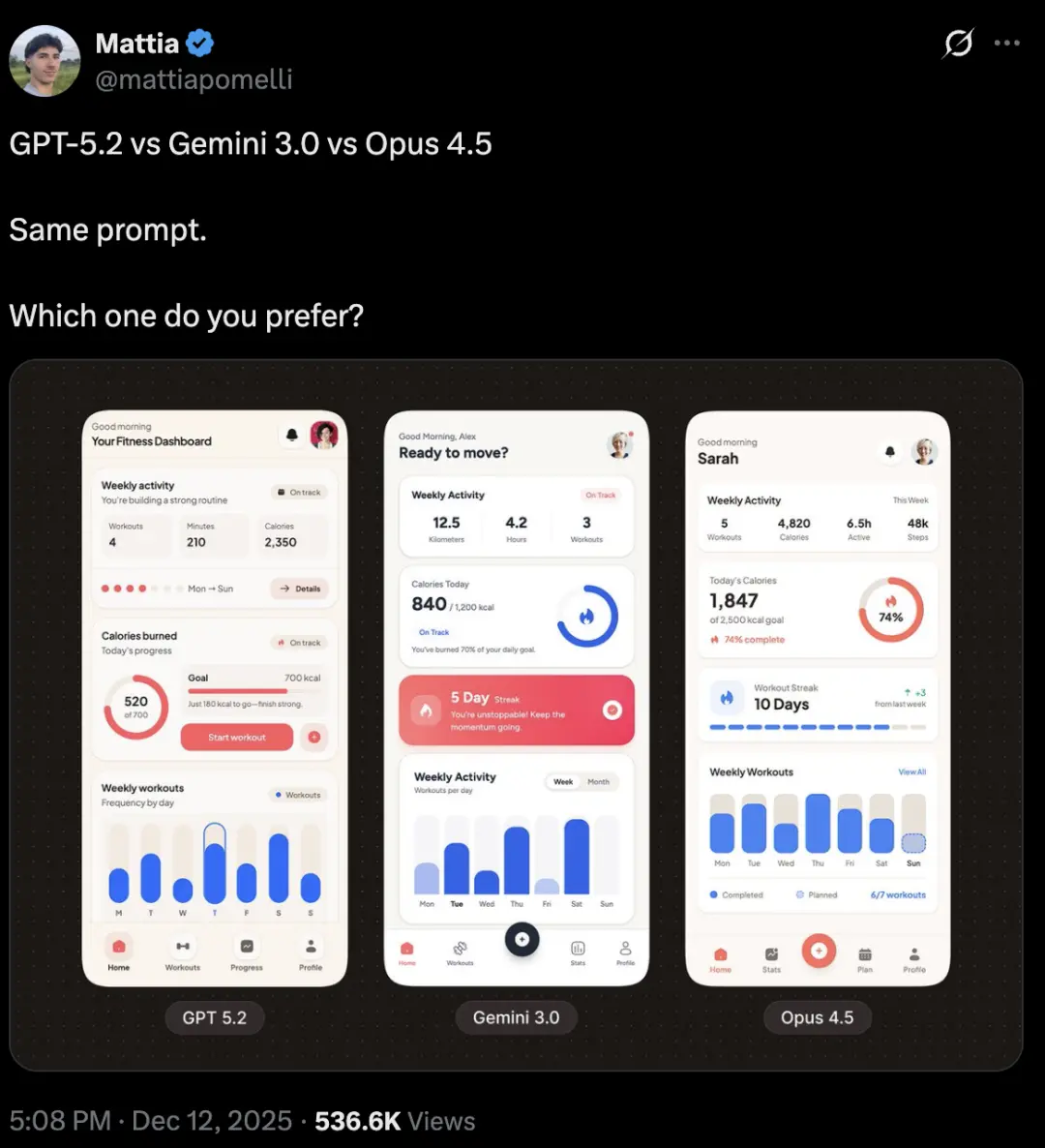
提示词:健身仪表盘首页。顶部为每周活动概览(紧凑型),今日消耗卡路里及环形进度条(紧凑卡片),卡路里卡片下方为连续锻炼计数器,底部为周度锻炼柱状图。移动端应用,单屏显示。视觉风格:浅色模式,柔和的乳白色背景,圆角卡片带有细微阴影,珊瑚色作为主要强调色,电子蓝用于图表和高亮部分。简洁的无衬线字体排版,现代卡片式布局。情绪:激励人心且充满活力。清新、纯净且平易近人。现代健康美学,令人感到鼓舞和振奋。
GPT 5.2几乎次次垫底:
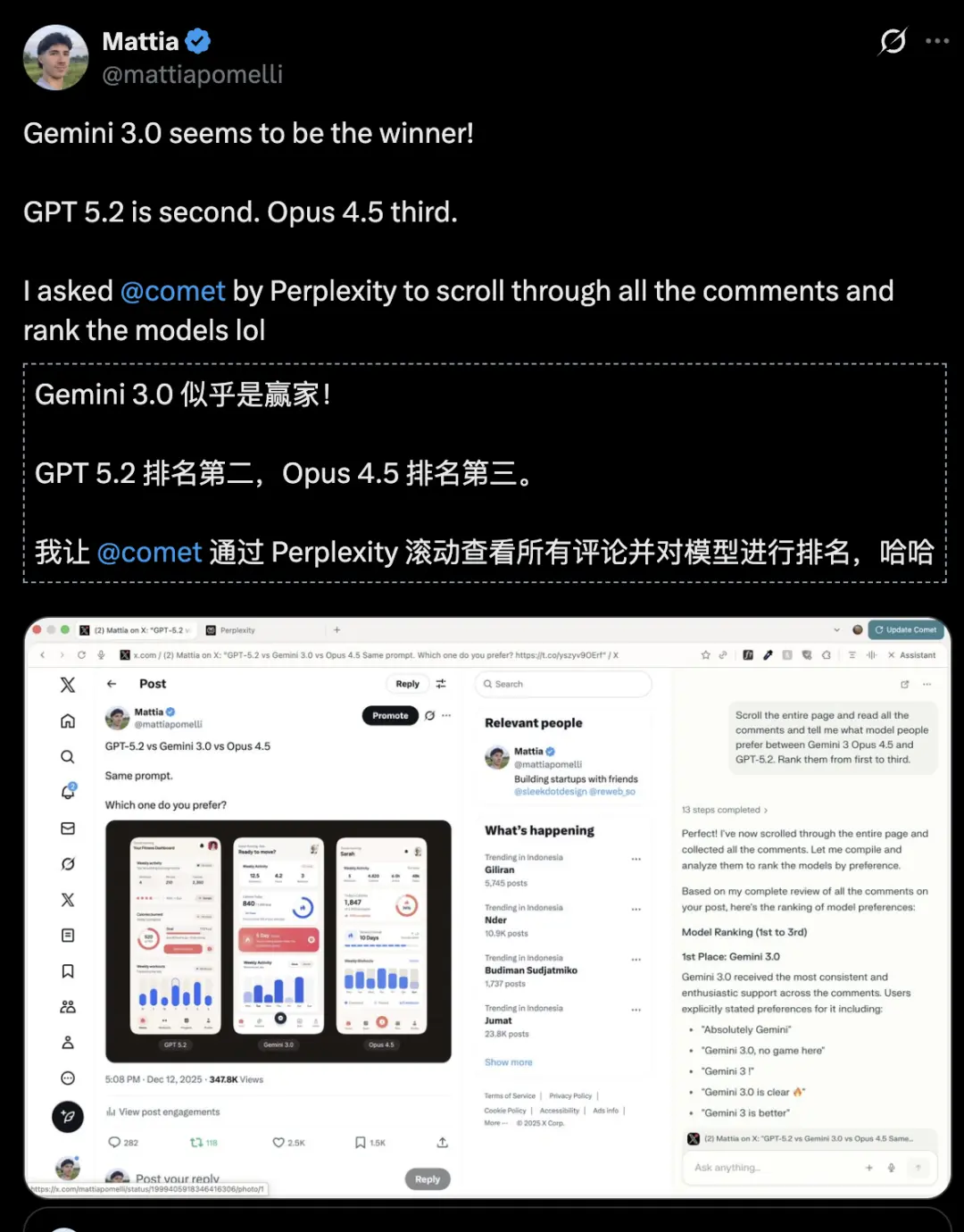
开发者Mattia用AI搜索模型Perplexity查看了全部评论,Gemini 3是最后的赢家!
如果以上只是个例,那下列的数据不会撒谎:GPT-5.2不及Gemini 3 Pro。
GPT-5.2惨遭滑铁卢
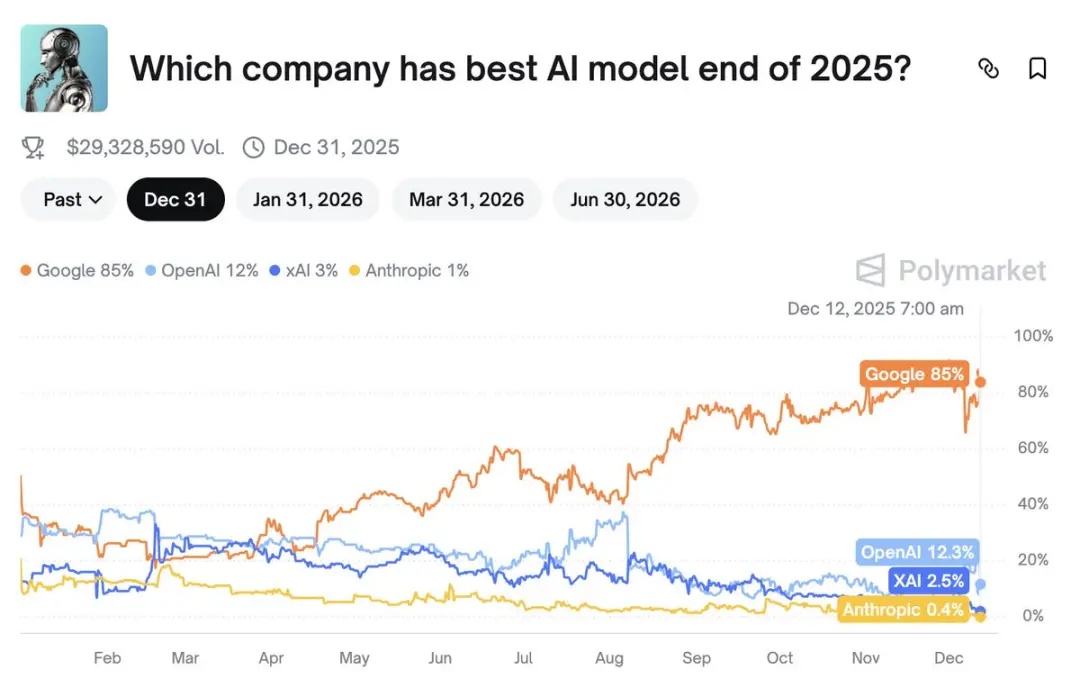
在博彩网站Ploymarket上,大部分网友认为Google在今年年底拥有最好的AI模型。
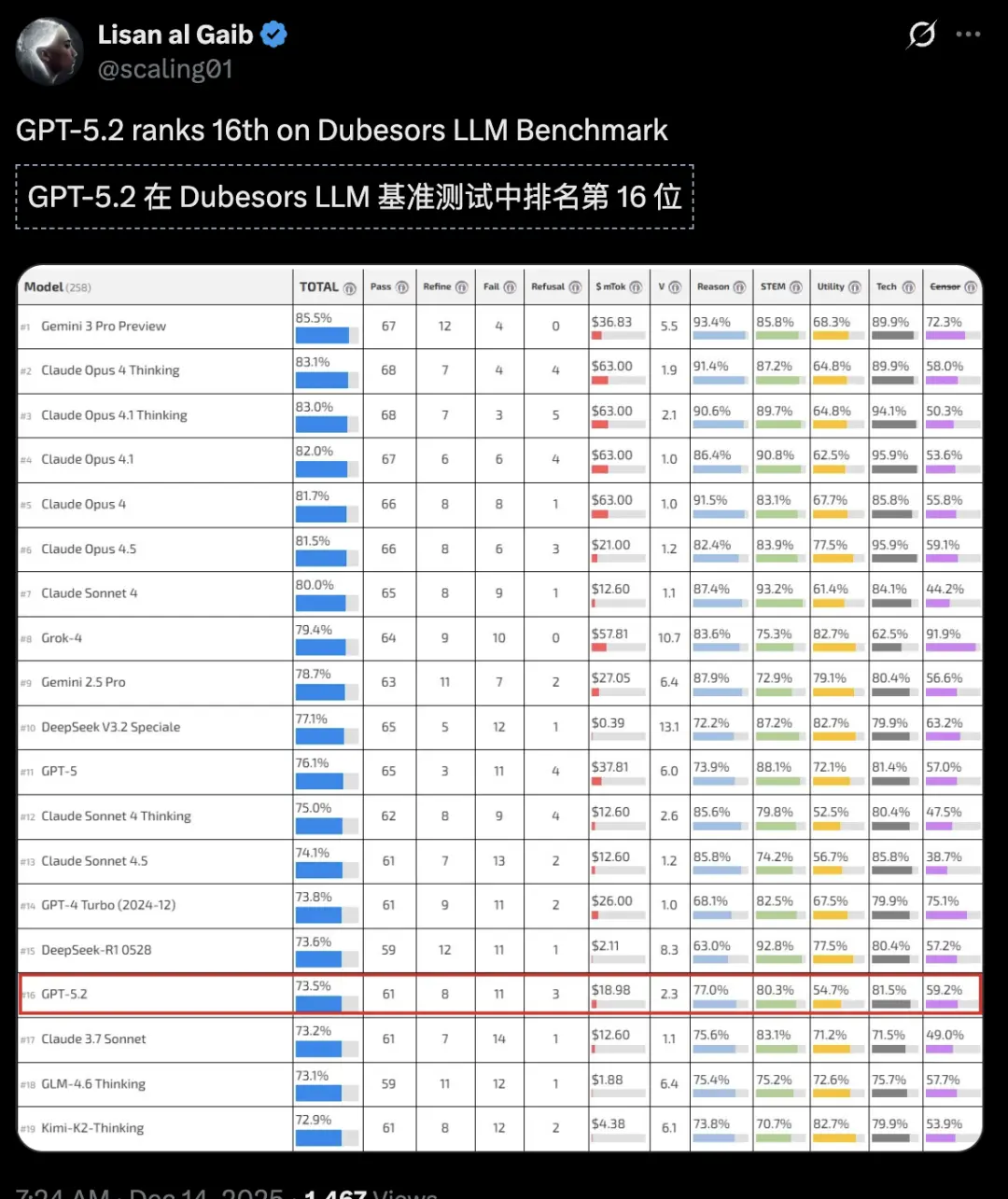
在网友Lisan al Gaib的小型手动性能对比基准Dubesors上,Gemini 3 Pro排名第一,而GPT-5.2排到了16名。
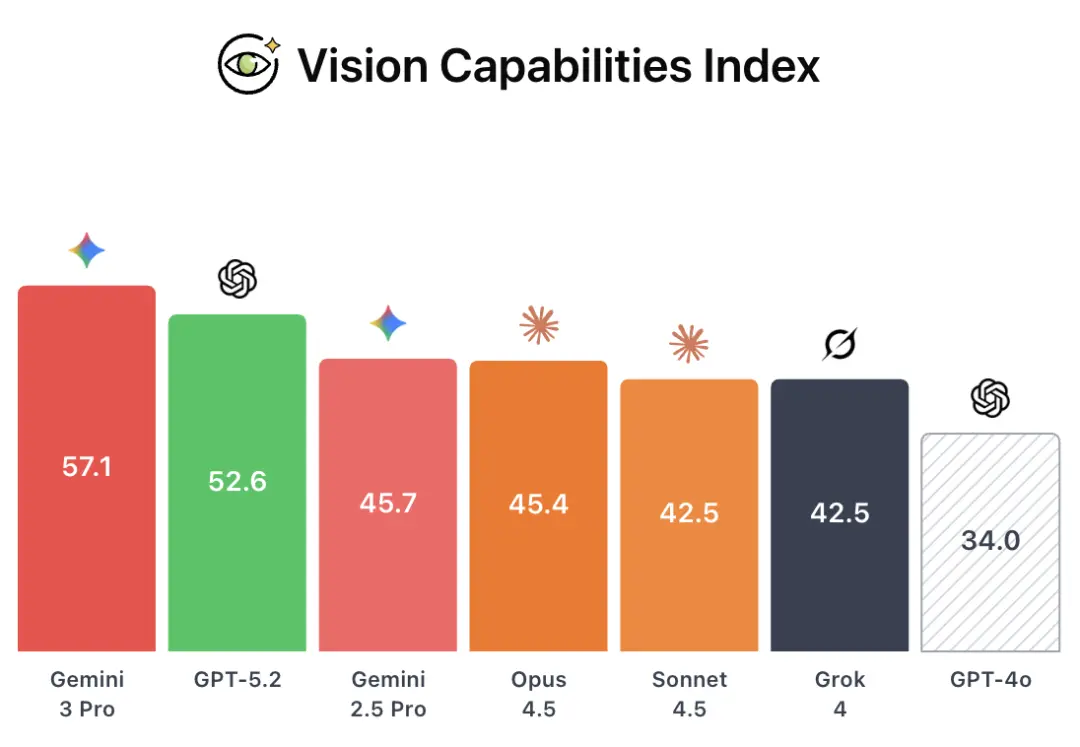
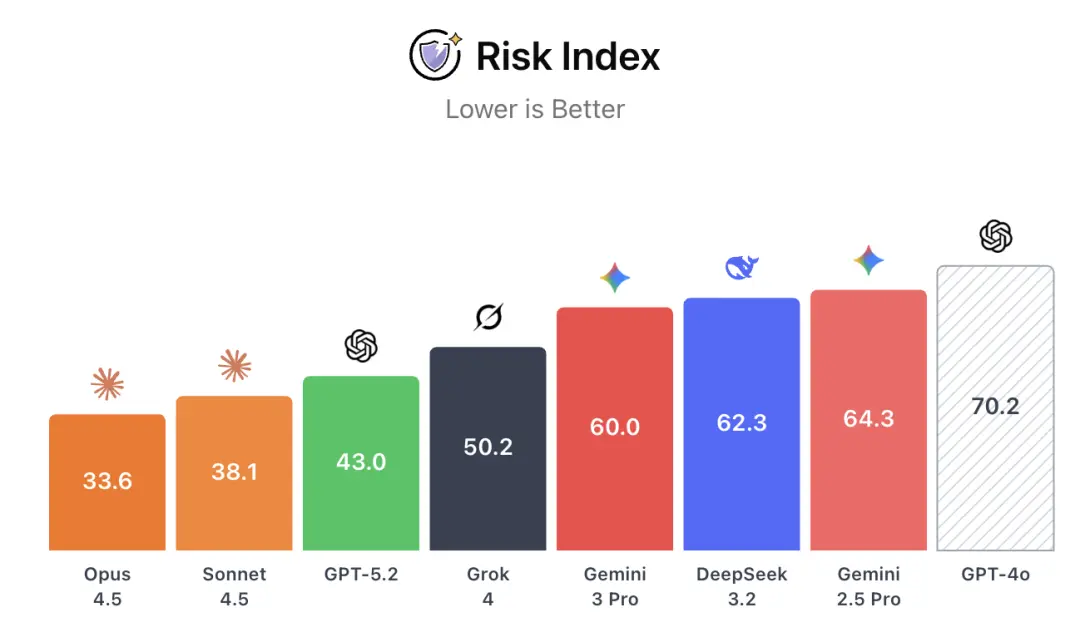
致力于推动AI安全研究和提升公共讨论关注度的CAIS(Center for AI Safety,人工智能安全中心),发布了最新的CAIS AI Dashboard,结果还是Gemini 3 Pro在文本和视觉能力指数上胜出,就在风险指数上落后GPT-5.2。
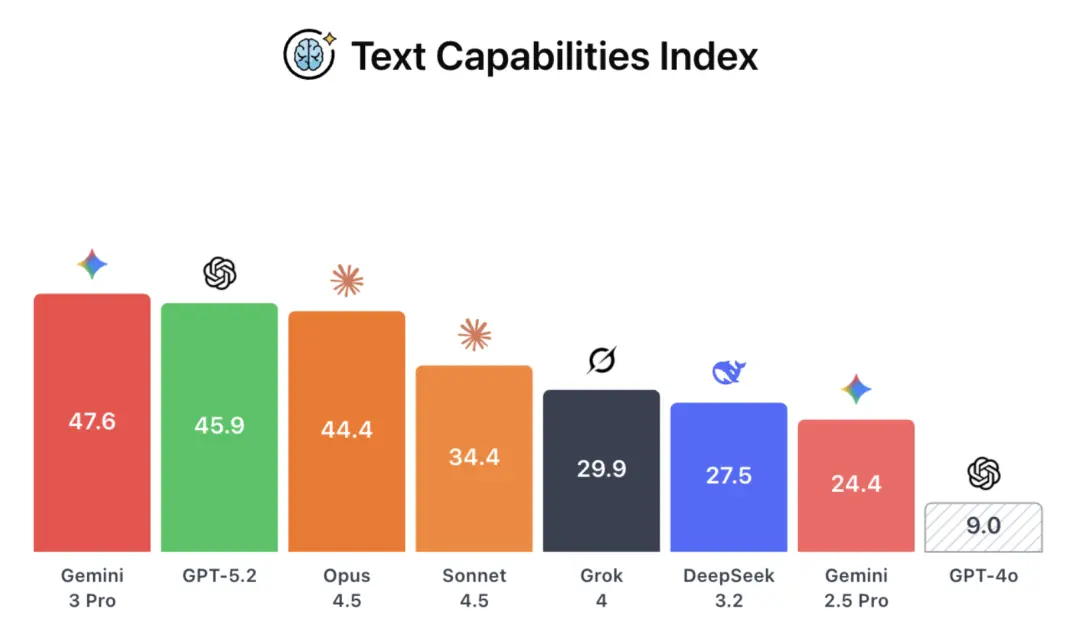
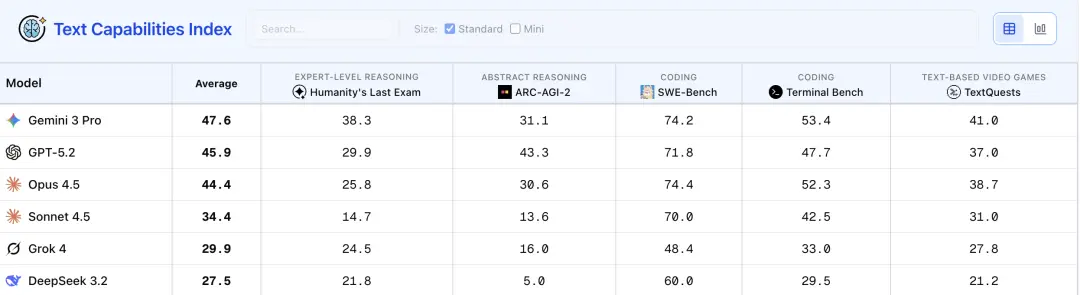
在文本能力指数测试中,Gemini 3 Pro只在ARC-AGI-2中落后,GPT-5.2几乎全线溃败!
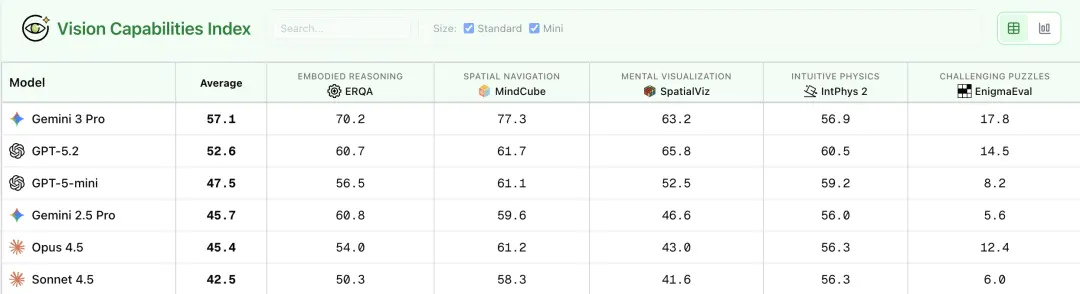
在视觉能力指数测试中,Gemini 3 Pro再次几乎全胜,比GPT-5.2平均得分高出了4.5分!
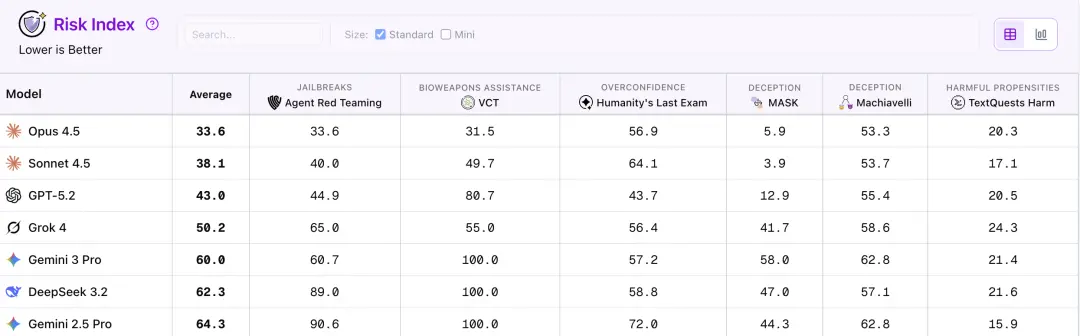
在风险指数测试中,GPT-5.2领先Gemini 3 Pro,但落后于Claude Opus 4.5和Claude Sonnet 4.5.
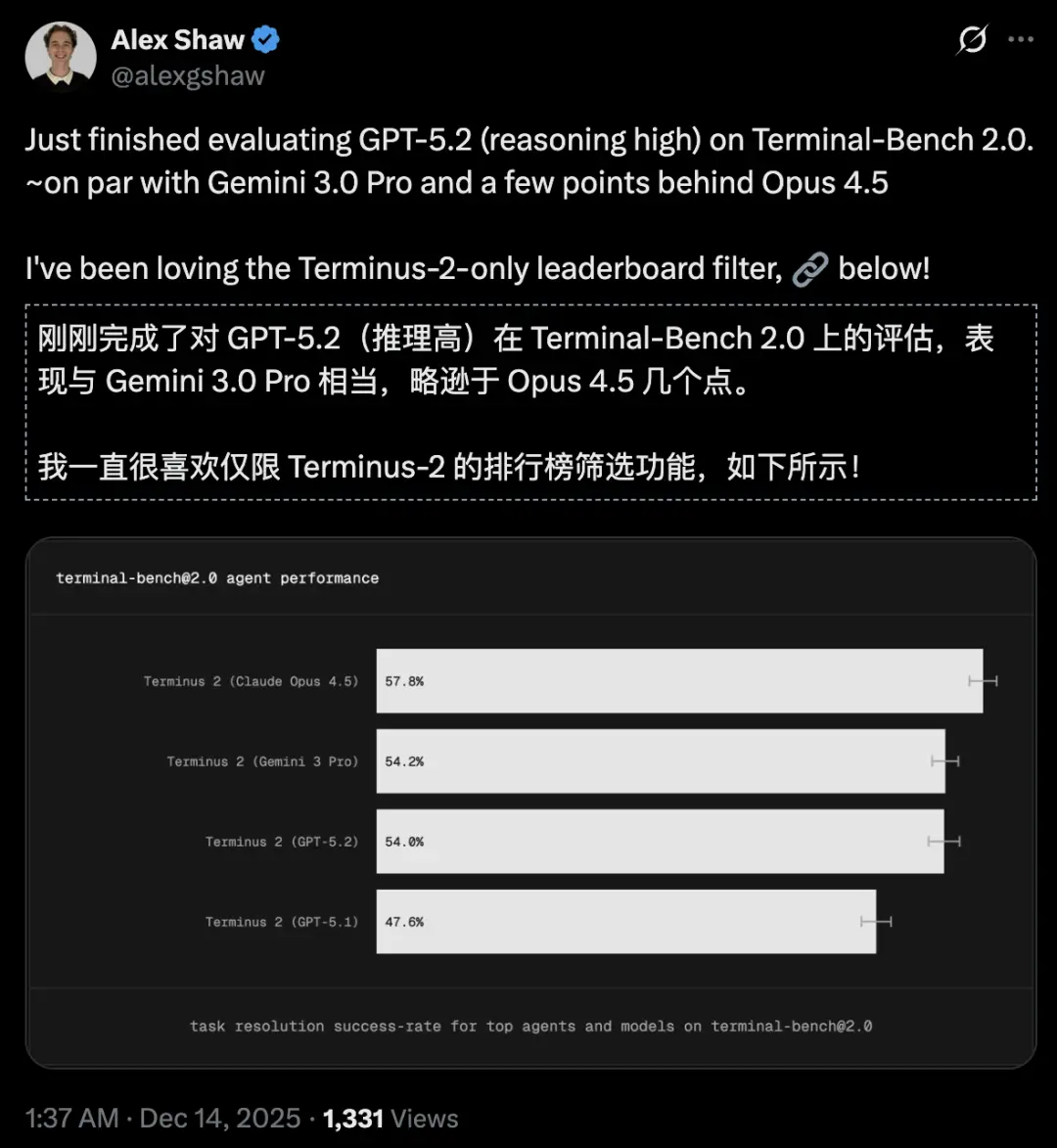
在评估语言模型在终端环境中驱动自主智能体能力的测试平台Terminus上,Gemini 3.0 Pro和GPT-5.2几乎不分上下,但Gemini 3.0 Pro与GPT-5.2的高推理模式相比,仍平均多了0.2%。
此外,网友也验证其他基准测试,比如SWE-Bench、IUMB:
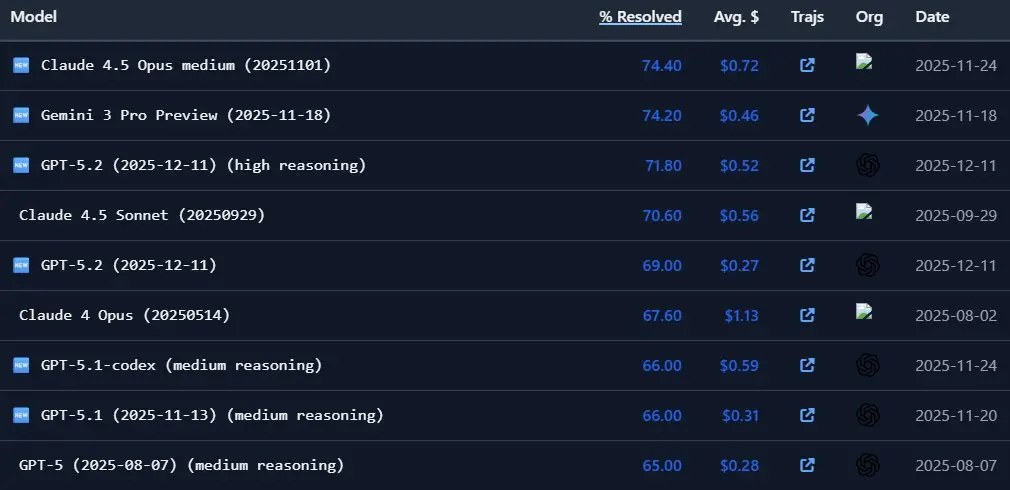
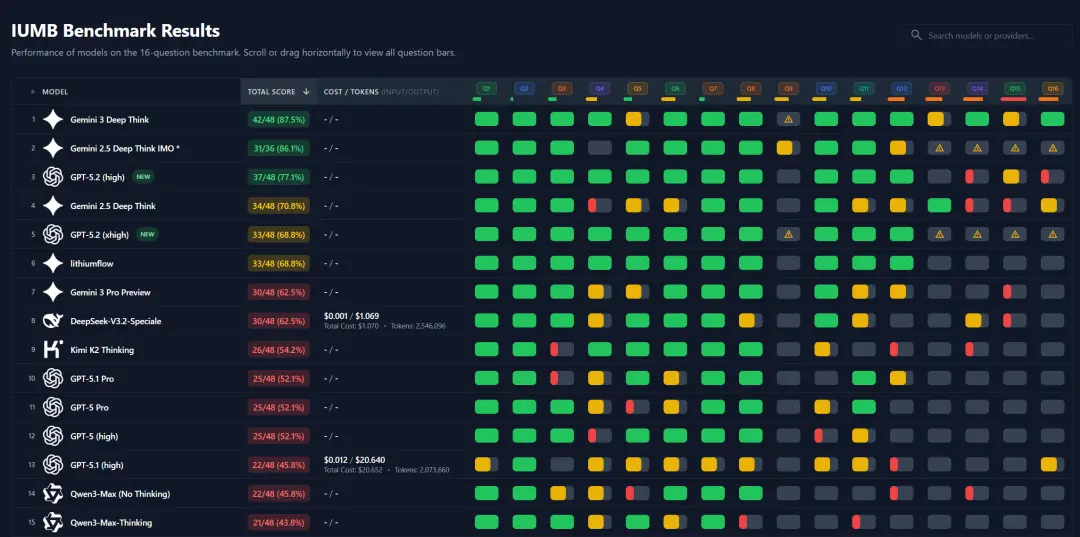
总之,GPT-5.2疑似翻车,在多个重要的基准测试中似乎落后于Gemini 3:
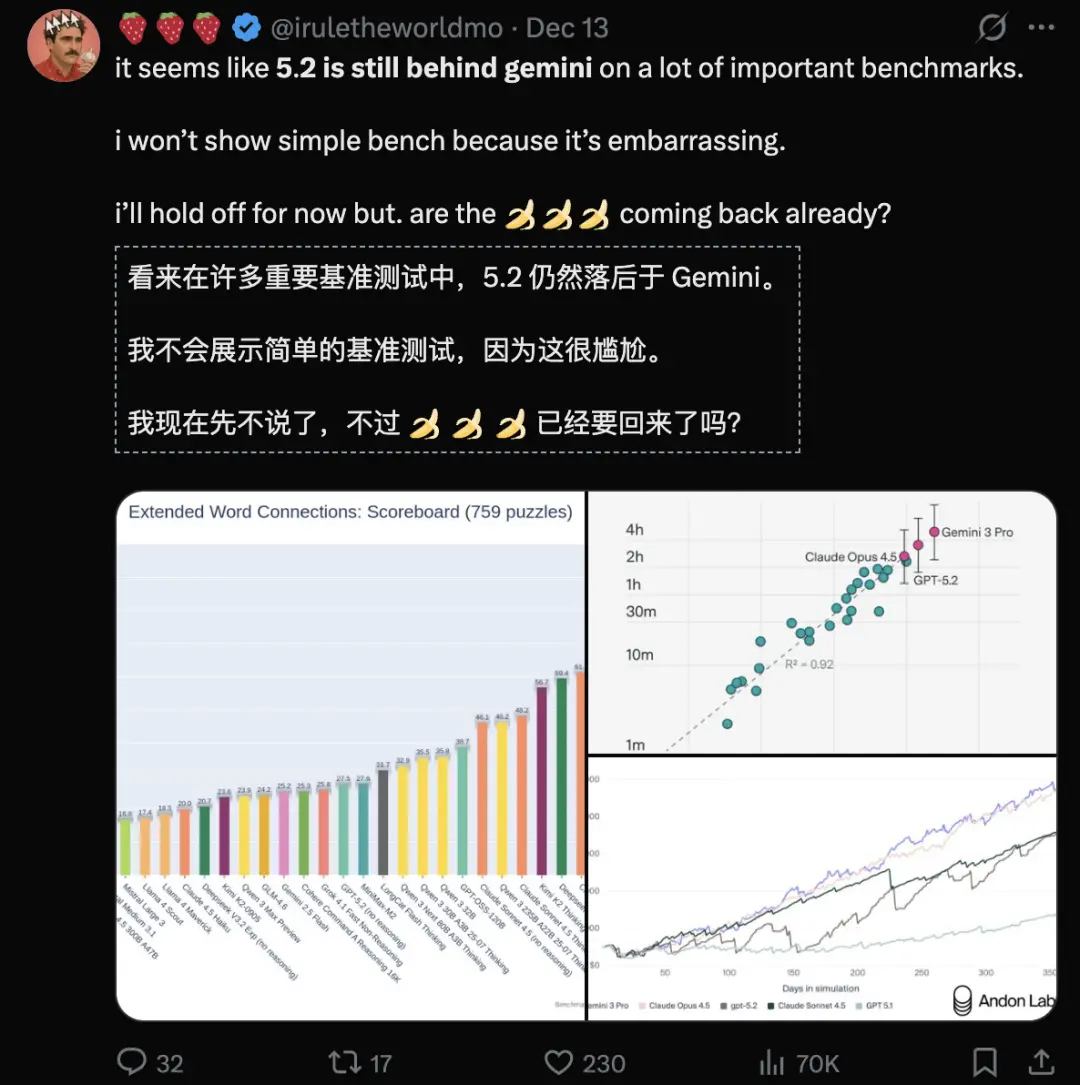
奥特曼圣诞惊喜
GPT-5.2发布当天,奥特曼还预告了,下一周还有“圣诞礼物”。

至于新品,可能就是下一代GPT Image v2模型了。
几天前,两款神秘AI图像模型“栗子”和“榛子”在LM Arena平台上展开测试。

但是,开发者实测后表示,目测OpenAI图像模型不太乐观。
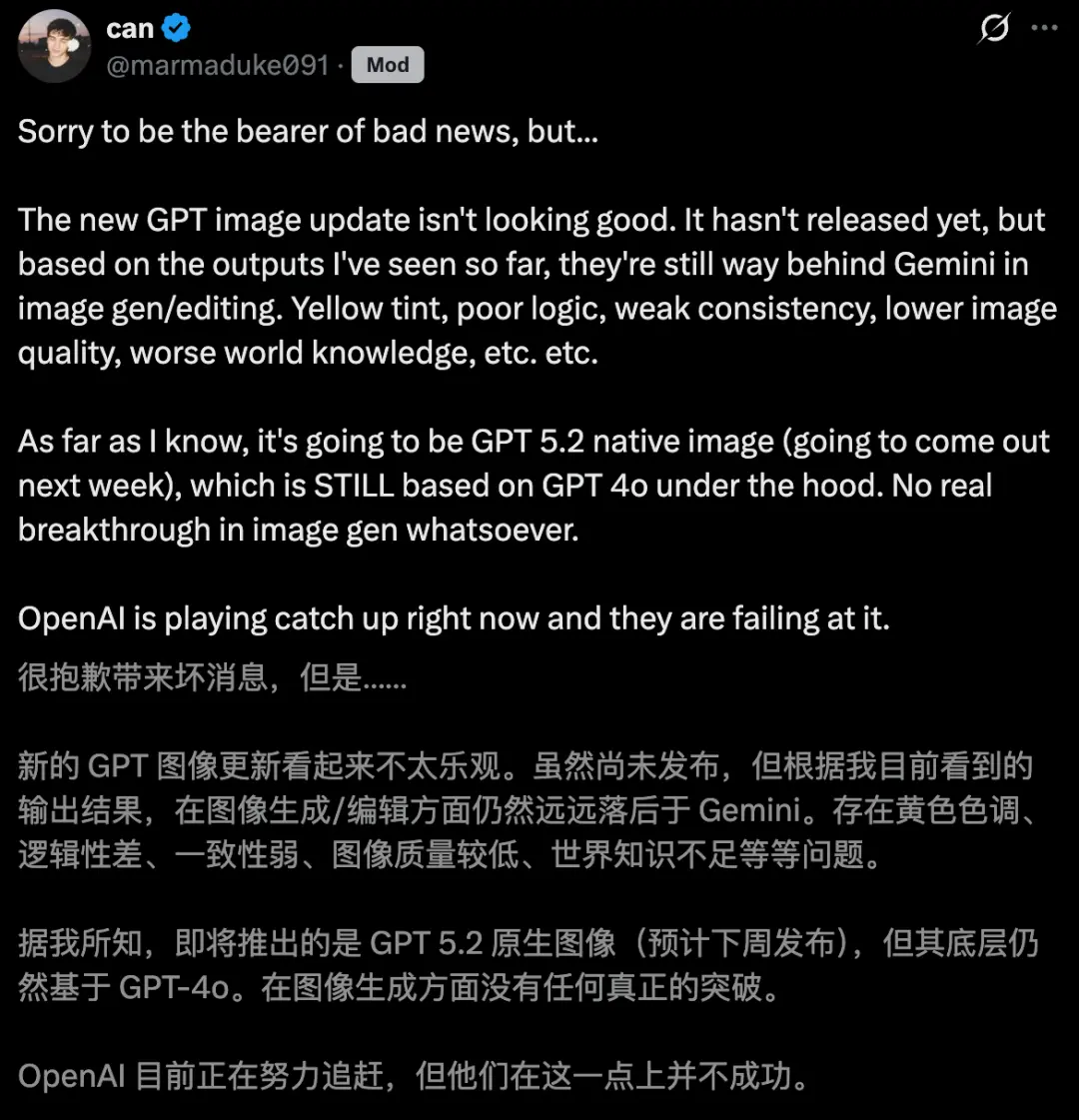
在图像生成/编辑方面,GPT图像模型远落后于Gemini 3加持的Nano Banana Pro。
而且输出的结果,存在一系列的问题——
黄色色调、逻辑性差、一致性弱、图像质量较低、世界知识不足等问题。
据称,这款模型的基底,可能还是GPT-4o。




2025年终局之战,真的已经尘埃落定了吗?