北京时间3月19日凌晨,英伟达创始人黄仁勋在美国加州圣何塞SAP中心,发表了GTC 2024的主题演讲《见证AI的变革时刻》。发布会上,黄仁勋介绍了全新芯片Blackwell,他称Blackwell的推理能力是惊人的,相较于前代产品H100有着惊人的提升,是Hopper的30倍。
英伟达表示,Blackwell 架构的 GPU 预计将于今年晚些时候发货。
Blackwell以美国数学家和博弈论学家 David Blackwell命名,继承了 Hopper GPU 架构,拥有2080亿个晶体管,是英伟达首个采用多芯片封装设计的 GPU,在同一个芯片上集成了两个GPU。
黄仁勋介绍道,如果要训练一个1.8万亿参数GPT模型,大约需要三到五个月的时间:
如果用Hopper来做,可能需要8000个GPU,并且会消耗15兆瓦。8000个GPU和15兆瓦,它会需要90天,大约三个月的时间。
如果你用Blackwell来做,只需要2000个GPU。2000个GPU,同样的90天。但这是惊人的部分,只需要四兆瓦的电力。
黄仁勋透露,包括AWS、Google、微软、Oracle等,都在为Blackwell做准备。同时英伟达将持续基于AI强化生态,比如NVIDIA Omniverse Cloud将可以连接到苹果公司混合头显Vision Pro、加强模型与通用机器人生态等。
黄仁勋还介绍了人形机器人基础模型Project GR00T、新款人形机器人计算机Jetson Thor,还与一对来自迪士尼研究公司的小型英伟达机器人进行互动。
以下为黄仁勋演讲全文,由AI翻译:
欢迎来到GTC大会。希望你们意识到这里不是音乐会,而是一个开发者大会。会有大量的科学、算法、计算机架构、数学等内容。
我感受到了房间里沉甸甸的氛围。突然间,好像你们误入了什么地方似的。世界上没有哪个会议能汇聚来自如此多元科学领域的研究人员,从气候科技到无线电科学,大家都在探索如何使用AI来机器人化控制MIMOS,用于下一代6G无线电,自动驾驶汽车,甚至是各方面的人工智能。首先,我注意到现场突然一阵松懈。同时,这次会议还汇集了一些了不起的公司。
这份名单,并不是参会者名单,这些都是发言嘉宾。令人惊叹的是,如果你去掉我所有的朋友,亲密朋友,迈克尔·戴尔就坐在那里,在IT行业区。
我在行业中成长的所有朋友。如果去掉那份名单,这就是令人惊叹的地方。这些非IT行业的发言者正在使用加速计算解决普通计算机无法解决的问题。这体现在生命科学、医疗保健、基因组学、交通、零售、物流、制造业、工业等行业的全方位代表。
你们不仅仅是来参加会议的。你们是来展示、讨论你们的研究成果的。今天在这个房间里代表的是全球100万亿美元行业的缩影。这绝对令人震惊。
绝对有一些事情正在发生。正在发生一些事情。整个行业正在转型,不仅仅是我们的行业,因为计算机行业,计算机是当今社会最重要的工具。基本上的转型和计算影响到了每个行业。但我们是如何开始的?我们是如何达到这里的?我为你们准备了一个小漫画。确切地说,我画了这一页。这是NVIDIA的旅程,始于1993年。这可能就是剩下的演讲内容。1993年,这是我们的旅程。我们成立于1993年。沿途发生了几个重要事件。我只是简单地强调了一下。
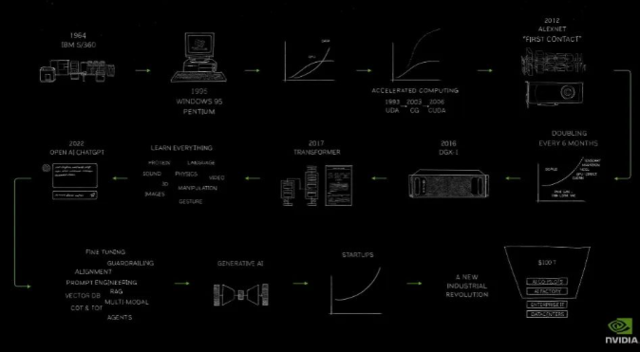
2006年,CUDA,它被证明是一个革命性的计算模型,我们当时认为它是革命性的,以为它将一夜之间获得成功。近20年后,它发生了,到了2012年。Alex Net AI和CUDA首次接触,到了2016年。认识到这一计算模型的重要性,我们发明了一种全新类型的计算机,我们称之为DGX1,170 teraflops。在这台超级计算机中,八个GPU首次连接在一起。我亲自交付了第一台DGX1给一家位于旧金山的初创公司,名为OpenAI。
DGX1是世界上第一台AI超级计算机。记住,170 teraflops。2017年, Transformer到来。2022年,ChatGPT捕获了世界的想象力。人们意识到人工智能的重要性和能力。
2023年,生成式AI浮现,新的行业开始形成。为什么是一个新行业?因为这样的软件以前从未存在过。我们现在正在使用计算机编写软件,创造以前从未存在过的软件。这是一个全新的类别。它从无到有占据了市场份额。这是一个全新的类别。而你生产软件的方式与我们以前在数据中心所做的完全不同。
生成token,以非常大的规模生成浮点数。仿佛在上一个工业革命的开始,当人们意识到你会建立工厂,向其提供能源,然后这种看不见但极其有价值的东西,电力,交流发电机就此产生。100年后,200年后,我们现在正在创造新类型的电子,token,通过我们称之为工厂的基础设施,生成这种新的、难以置信的有价值的东西,人工智能。一个新的行业已经出现了。
我们将讨论这个新行业的许多方面。我们将讨论我们接下来将如何进行计算。我们将讨论由于这个新行业而构建的新软件类型,你应该如何看待这些新软件,这个新行业中的应用程序会是什么?然后也许是接下来会发生什么,我们如何从今天开始为即将到来的下一步做准备?
但在我开始之前,我想向你们展示NVIDIA的灵魂。NVIDIA的灵魂位于计算机图形、物理学和人工智能的交汇处,所有这些交汇在Omniverse中,一个虚拟世界的仿真。我们今天将向你展示的一切都是仿真的,而不是动画。它之所以美丽,是因为它是物理的。世界之所以美丽,是因为它是物理的。它之所以令人惊叹,是因为它通过机器人进行了动画制作。它通过人工智能进行了动画制作。你即将看到的所有内容都是完全生成的,完全仿真的,而且都是在Omniverse中生成的。而你即将欣赏的所有内容,你即将欣赏的是世界上第一场一切都是自制的音乐会。你将要看一些家庭视频。所以请坐下来,好好享受吧。

好吧,天啊,我爱NVIDIA。加速计算已达到转折点。通用计算已经走到尽头。我们需要另一种计算方式,以便我们可以继续扩展,以便我们可以继续降低计算成本,以便我们可以继续消耗越来越多的计算,同时保持可持续性。
加速计算与通用计算相比大大加速。在我们参与的每个行业中,我将向你展示很多,影响都是巨大的,但在我们自己的行业中,即使用仿真工具创建产品的行业中,它更为重要。在这个行业中,这不仅仅是关于降低计算成本,而是关于提高计算规模。
我们希望能够完全模拟我们所做的整个产品,以完全的保真度,完全数字化地进行,本质上就是我们所说的数字孪生。我们希望设计它,构建它,模拟它,完全数字化地操作它。为了做到这一点,我们需要加速整个行业。
今天,我想宣布,我们有一些合作伙伴加入我们这一旅程,以加速他们的整个生态系统,以便我们可以将世界带入加速计算的时代。但这里有一个额外的好处。当你成为加速的一部分时,你的基础设施就是Cuda GPU。当发生这种情况时,它恰好是生成式AI的完全相同的基础设施。因此,我非常高兴地宣布几个非常重要的合作伙伴关系。
这些是世界上一些最重要的公司,ANSYS为世界制造工程仿真。我们与他们合作,以Cuda加速ANSYS生态系统,将ANSYS连接到Omniverse数字孪生。太棒了。
真正伟大的是,NVIDIA GPU加速系统的安装基础遍布全球,在每个云中,在每个系统中,遍及所有企业。因此,他们加速的应用程序将拥有一个巨大的安装基础以服务。最终用户将拥有令人惊叹的应用程序。当然,系统制造商和CSP将拥有巨大的客户需求。
Synopsys是NVIDIA字面上的第一个软件合作伙伴。他们在我们公司的第一天就在那里。Synopsys通过高级设计彻底改变了芯片行业。我们将CUDA加速Synopsys。我们正在加速计算光刻,这是最重要的应用程序之一,没有人知道。为了制造芯片,我们必须将光刻推向极限。NVIDIA创建了一个领域特定的库,极大地加速了计算光刻。一旦我们能够加速并定义台积电所有的软件,台积电今天宣布他们将与NVIDIA一起投入生产,cuLitho。一旦软件定义并加速,下一步就是将生成式AI应用到芯片制造的未来。Cadence构建了世界上基本的EDA和SDA工具。我们也使用Cadence,通过这三家公司,ANSYS、Synopsys和Cadence,我们基本上一起构建了NVIDIA。我们正在加速Cadence。他们还在用NVIDIA GPU构建超级计算机,以便他们的客户可以以100、1000倍的规模进行流体动力学仿真。基本上是实时的风洞。Cadence Millennium,一台内置NVIDIA GPU的超级计算机,一家软件公司正在构建超级计算机。我很高兴看到这一点。
与Cadence共同构建copilots,想象一下,当Cadence、Synopsys、ANSYS等工具提供商为您提供AI copilots的一天,这样我们就有成千上万的copilot助手帮助我们设计芯片,设计系统。我们还将Cadence Digital Twin平台连接到Omniverse。正如你所看到的趋势,我们正在加速世界上的CAE、EDA和SDA,以便我们可以在数字孪生中创建我们的未来。我们将把它们全部连接到Omniverse,未来数字孪生的基本操作系统之一,受益于规模的行业之一,你们都非常了解这一点,大型语言模型。基本上,在Transformer被发明之后,我们能够以惊人的速度扩展大型语言模型,实际上每六个月翻一番。现在,我们如何能够以每六个月翻一番的速度发展这个行业,发展这个计算需求呢?原因很简单。如果你将模型的大小加倍,你将大脑的大小加倍,你需要两倍的信息来填充它。因此,每次你将参数计数加倍时,你还必须相应地增加你的训练token计数。这两个数字的组合成为了计算规模。你必须支持最新的、最先进的OpenAI模型,大约有1.8万亿个参数。1.8万亿个参数需要几万亿个token进行训练。所以几万亿个参数,大约几万亿个token,大约当你将两者相乘在一起时,大约有三十、四十、五十万亿次浮点运算每秒。
现在我们只需要做一些数学,请跟我一起。所以你有三十亿万亿。一个万亿就像一个Peta。因此,如果你有一个Petaflop GPU,你需要300亿秒来计算,来训练那个模型。300亿秒大约是1000年。好吧,1000年,这是值得的。想要做得更快一些,但这是值得的。
是的,这通常是我的回答,当大多数人告诉我,嘿,做某事需要多长时间?所以我们得到了20年的价值,但我们下周能做到吗?因此,1000年,1000年。所以我们需要更大的GPU。我们需要更大的GPU。
我们很早就认识到了这一点,我们意识到答案是将一大堆GPU放在一起,当然,沿途创新了很多东西,比如发明张量核心,推进MV链接,这样我们就可以创建本质上是虚拟巨型GPU的东西,并将它们全部连接在一起,通过一个名为Mellanox的公司的惊人InfiniBand网络,这样我们就可以创建这些巨型系统。
因此,DGX1是我们的第一个版本,但它不是最后一个。我们一直在沿途构建超级计算机。在2021年,我们有Celine, 40500个GPU左右。然后在2023年,我们构建了世界上最大的AI超级计算机之一。它刚刚上线。而且,当我们构建这些东西时,我们正在努力帮助世界构建这些东西。为了帮助世界构建这些东西,我们必须首先构建它们。我们构建芯片,系统,网络,所有必要的软件来做到这一点。
你应该看到这些系统。想象一下编写一段软件,跨整个系统运行,将计算分布在成千上万的GPU上。但里面有成千上万的小GPU,数百万个GPU来分配工作,以便在所有这些中平衡工作负载,以便你可以获得最高的能源效率,最佳的计算时间,降低成本。因此,这些基本创新是我们到达这里的原因。
现在我们在这里,当我们看到ChatGPT在我们面前出现的奇迹时,我们也意识到我们还有很长的路要走。我们需要更大的模型。我们将用多模态数据来训练它,不仅仅是互联网上的文本,但我们将用文本和图像、图表和图表进行训练,就像我们通过看电视学习一样。因此,将会有很多观看视频,以便这些模型可以在物理学上得到基础,了解手臂不会穿过墙壁。因此,这些模型将通过观看大量的世界视频与大量的世界语言相结合,具有常识。
它将使用诸如合成数据生成之类的东西,就像你和我学习时一样,我们可能会使用我们的想象力来模拟它最终会如何,就像我在准备这个主题演讲时一样。我一直在模拟它。我希望它能像我在头脑中模拟的那样好。有人确实说,另一位表演者完全在跑步机上完成了她的表演,这样她就可以以充满活力的方式呈现它。我没有那样做。如果我在这个过程中有点喘不过气来,你知道发生了什么。因此,我们在这里使用合成数据生成,我们将使用强化学习,我们将在我们的头脑中练习,我们将让AI与AI一起工作,相互训练,就像学生、老师、辩论者一样,所有这些都将增加我们模型的大小。它将增加我们拥有的数据量,我们将不得不构建更大的GPU。
黄仁勋介绍最新GPU——Blackwell
Hopper很棒,但我们需要更大的GPU。因此,女士们先生们,我想向你们介绍一个非常大的GPU,以数学家、博弈论家、概率论家大卫·布莱克威尔(David Blackwell)的名字命名,我们认为这是一个完美的名字。Blackwell,女士们先生们,请享受。

Blackwell不是一个芯片。Blackwell是一个平台的名称。人们认为我们制造GPU,我们确实制造了,但GPU的外观已经不再像过去那样了。这是Blackwell系统的核心。而这在公司内部不称为Blackwell。它只是一个数字。这是Blackwell,这是当今世界上最先进的GPU。

(黄仁勋对比了 Blackwell(右)与 Hopper GH100 GPU(左)的大小)
2080亿个晶体管。因此,我可以看到两个芯片之间有一条细线。这是第一次以这种方式将两个芯片紧密连接在一起,以至于两个芯片认为它是一个芯片。它们之间有10TB的数据,每秒10TB,以至于Blackwell芯片的两侧不知道它们在哪一侧。没有内存局部性问题,没有缓存问题。它只是一个巨大的芯片。

当我们被告知Blackwell的野心超出了物理极限时,工程师说,那又怎样?因此,这就是发生的事情。因此,这是Blackwell芯片,它进入了两种类型的系统。第一个是与Hopper形状兼容的,因此,你可以滑出Hopper,然后推入Blackwell。这就是为什么其中一个挑战之一将是如此高效的原因之一。全世界都安装了Hopper,它们可以是相同的基础设施,相同的设计,电力,电力,热量,软件,都相同,直接推回去。因此,这是当前HGX配置的Hopper版本。这是另一个Hopper的样子。现在,这是一个原型板。
因此,这是,这是一个完全功能的板。我会在这里小心一点。这个,我不知道,100亿美元。第二个是5亿,之后就便宜了。所以,观众中的任何客户,没关系,好吗?但这个是相当昂贵的。这是第一个启动板,生产时将采用这种方式。好吧。因此,你会拿到这个。
它有两个Blackwell芯片和四个Blackwell芯片模具连接到Grace CPU。Grace CPU有一个超快的芯片到芯片链接。令人惊叹的是,这台计算机是第一台这样的计算机,这么多的计算适合这么小的空间。第二,它是内存一致的。他们觉得他们就像一家幸福的大家庭一样,在一个应用程序中一起工作。因此,它在其中的一切都是一致的。
但这是一个奇迹。让我们看看这里有一些东西。这里有MV链接,PCI Express在底部,一个是CPU芯片到芯片链接。希望它已经插好了。
所以这是Grace Blackwell系统,但还有更多。所有的规格都很棒,但我们需要大量的新功能,以便在物理极限之外推动极限,我们希望总是获得更多的X因素。因此,我们做了一件事,我们发明了另一个Transformer引擎,第二代。它具有动态和自动地重新缩放和重新铸造数值格式为较低精度的能力。记住,人工智能是关于概率的。因此,你大致有1.7乘以1.4大约等于其他东西。这有意义吗?因此,在研究的特定阶段保留必要的精度和范围非常重要。
因此,这不仅仅是我们设计了一个更小的ALU的事实。世界不是那么简单。你必须弄清楚你何时可以在成千上万个GPU上运行数周又数周的计算中使用它,并且你希望确保训练工作能够收敛。
因此,这个新的Transformer引擎,我们有第五代MV Link。它现在是Hopper的两倍快,但非常重要的是,它在网络中有计算。因为当你有这么多不同的GPU一起工作时,我们必须与彼此分享我们的信息。我们必须相互同步和更新。偶尔,我们必须减少部分产品,然后将部分产品重新广播回其他所有人。因此,有很多所谓的all reduce和all to all和all gather,这都是这个同步和集体的一部分,这样我们就可以让GPU相互协作,拥有极其快速的链接,并能够在网络中进行数学计算,使我们能够进一步放大。
因此,尽管它是1.8TB每秒,但实际上比这个高得多。因此,它是Hopper的许多倍,超级计算机连续运行数周的可能性几乎为零。原因是因为同时有这么多组件在工作。统计上,它们连续工作的概率非常低。因此,我们需要确保,只要我们能够,我们就会尽可能经常地检查点和重新启动。
但如果我们有能力提前检测到一个弱芯片或一个弱节点,我们可以退役它,也许换入另一个处理器。保持超级计算机利用率高的能力,特别是当你刚刚花费20亿美元建造它时,非常重要。
因此,我们加入了一个Ras引擎,一个可靠性引擎,它对Blackweld芯片上的每一个门,每一个内存位进行100%的自测试和系统测试以及所有连接到它的内存。这就好像我们用来测试我们芯片的高级测试仪随每个芯片一起发货一样。这是我们第一次这样做。超级兴奋。安全AI。
显然,只有这次会议才会为Ras鼓掌,安全AI。显然,你刚刚花费了数亿美元创建了一个非常重要的AI。而且,这个AI的智能是编码在参数中的。你希望一方面确保你不会丢失它,另一方面确保它不会被污染。因此,我们现在有能力加密数据,当然,在静止时,但也在传输中。当我们计算时,它都是加密的。因此,我们现在有能力在传输中加密,当我们计算时,它在一个受信任的,受信任的引擎环境中。最后一件事是解压缩。当计算如此之快时,将数据移入和移出这些节点变得非常重要。因此,我们加入了一个高线速压缩引擎,有效地将数据以20倍的速度移入和移出这些计算机。这些计算机是如此强大,投资如此巨大,我们最不想做的就是让它们空闲。因此,所有这些功能都旨在尽可能地保持Blackwell的供应并尽可能忙碌。总的来说,与Hopper相比,它的FPA性能提高了两倍半,每芯片用于训练。它还具有这种称为FP6的新格式,因此,即使计算速度相同,由于内存的带宽被放大,因为你可以在内存中存储的参数量现在被放大了。FP4实际上使吞吐量翻了一番。
这对于推理至关重要。越来越清楚的一件事是,当你在另一边使用计算机与AI交互时,当你与聊天机器人聊天时,当你要求它审查或生成图像时,记住,背后是一个GPU在生成token。有些人称之为推理,但更恰当的说法是生成,过去的计算是检索。你会拿起你的手机,你会触摸一些东西,一些信号就会发出去。基本上是一封电子邮件发送到某个地方的一些存储。有预先录制的内容。有人写了一个故事,有人制作了一个图像,有人录制了一个视频。那些预先录制的内容然后被流回到手机上,并基于推荐系统以某种方式重新组合,向你展示信息。你知道,在未来,大部分内容都不会被检索。原因是因为那是由不了解上下文的某人预先录制的,这就是为什么我们必须检索这么多内容的原因。如果你可以与了解上下文的AI一起工作,并为你生成信息,就像你喜欢的那样,我们节省的能源,我们节省的网络带宽,我们节省的浪费时间将是巨大的。未来是生成性的,这就是为什么我们称之为生成式AI,这就是为什么这是一个全新的行业。
我们计算的方式根本不同。我们为生成式AI时代创建了一个处理器,其中最重要的部分之一是内容token生成。我们称之为。这种格式是FP4。好吧,这是大量的计算。
5倍的生成token生成,5倍的Hopper推理能力似乎足够了。但为什么要在这里停下来?答案是不够的。我将向你展示为什么。
我将向你展示什么。因此,我们想要一个更大的GPU,甚至比这个更大的GPU。因此,我们决定扩展它并注意到,但首先,让我告诉你我们在过去八年中如何扩展,我们将计算增加了1000倍。八年1000倍。回想一下摩尔定律的美好时光,它是2倍,好吧,5倍每个什么?10倍每5年。这是最简单的地图。10倍每5年。10年100倍。在PC革命的黄金时代中间,每10年增长100倍。每10年100倍。在过去的八年中,我们增长了1000倍。我们还有两年要走。
因此,这将使其具有一定的视角。我们正在以疯狂的速度推进计算,而且仍然不够快。所以我们又造了一个芯片。这个芯片太不可思议了。我们称之为MV Link开关。它是500亿个晶体管。它几乎和Hopper一样大。这个开关上有四个MV链接,每个都是1.8TB每秒。正如我提到的,它在内部有计算。这个芯片是做什么用的?如果我们要构建这样的芯片,我们可以让每个GPU同时以全速与每个其他GPU通信。这太疯狂了。
这甚至没有意义。但如果你能做到这一点,如果你能找到一种方法来做到这一点,并构建一个成本效益的系统来做到这一点,那将是多么令人难以置信,我们可以通过一致的链接使所有这些GPU有效地成为一个巨大的GPU。
为了使其成本效益,这个芯片必须能够直接驱动铜。这个芯片的证书是一个了不起的发明,这样我们就可以构建一个看起来像这样的系统。
现在,这个系统有点疯狂。这是一个DGX。这就是DGX现在的样子。记住,就在六年前,它很重,但我还是能抬起来的。我把第一台DGX1交给了OpenAI和那里的研究人员。它在,你知道,图片在互联网上,我们都签名了。如果你来我的办公室,它是签名的。这真的很漂亮,但你可以抬起来。
这个DGX,顺便说一下,是170 teraflops,如果你不熟悉编号系统,那是0.17 pedoflops。所以这是720。我第一次交给OpenAI的是0.17。你可以四舍五入到0.2,没什么区别。但那时候就像,哇,你知道,再多30个teraflops。因此,这现在是720 pedoflops,几乎是一个用于训练的Xaflop,世界上第一个在一个机架上的Xaflop机器。
顺便说一下,目前全球只有2、3个exaflops机器。因此,这是一个Xaflop AI系统,只有一个机架。好吧,让我们看看背面。所以这是让它成为可能的东西。这就是背面。这就是,这就是背面。DGX MV Link脊椎,130TB每秒通过那个底座。那是超过互联网总带宽的聚合带宽。
因此,我们基本上可以在一秒钟内将所有东西发送给每个人。因此,我们总共有5000根MV link电缆,总共两英里。现在,这是惊人的事情。如果我们不得不使用光学,我们将不得不使用收发器和重定时器。而这些收发器和重定时器仅需耗费20,000瓦,2千瓦的电力,仅用于驱动enveloent脊椎。因此,我们通过MV Link开关完全免费完成了这项工作,因此我们能够为计算节省20千瓦。整个机架是120千瓦。因此,那20千瓦有很大的不同。它是液体冷却的。进水温度是25摄氏度,大约是室温。出水温度是45摄氏度,大约是你的按摩浴缸温度。所以室温进来,按摩浴缸温度出来,每秒两升。
我们可能卖出60万个外围设备部件。有人曾经说过,你们知道,你们制造GPU,我们确实制造GPU,但这就是GPU对我来说的样子。当有人说GPU时,我两年前看到的GPU是HGX,它是70,35,000个部件。我们现在的GPU有60万个部件,重3000磅。3000磅。3000磅。这有点像你知道的碳纤维法拉利的重量。我不知道这是否有用,但每个人都在说,我感觉到它,我感觉到它。我现在提到这个,我感觉到它了。我不知道3000磅是什么?好吧,所以3000磅,一吨半。所以它还不像大象那么重。这就是DGX的样子。
现在让我们看看它在运行中是什么样子。好的,让我们想象一下,我们如何让这个工作起来,这意味着什么?嗯,如果你要训练一个GPT模型,一个1.8万亿参数模型,显然大约需要三到五个月的时间,使用25,000个安培。如果我们用Hopper来做,可能需要8000个GPU,并且会消耗15兆瓦。8000个GPU和15兆瓦,它会需要90天,大约三个月的时间。这将允许你训练一个,你知道的,这种开创性的AI模型。这显然不像任何人想象的那么昂贵,但这是8000个GPU。这仍然是一大笔钱。所以8000个GPU,15兆瓦,如果你用Blackwell来做,只需要2000个GPU。2000个GPU,同样的90天。但这是惊人的部分,只需要四兆瓦的电力。

我们的目标是不断降低成本和与计算相关的能源消耗,它们是直接成正比的,这样我们就可以继续扩展和升级我们为了训练下一代模型而必须进行的计算。
训练推理或生成非常重要,非常重要。你知道,现在NVIDIA GPU在云中的使用时间大约有一半是用来生成Token的。你知道,它们要么在做副驾驶,要么在做聊天,你知道的,ChatGPT或者其他你与之互动的不同模型,或者生成图像或视频,生成蛋白质,生成化学物质。所有这些都是基于我们称之为推理的计算类别。
但对于大型语言模型来说,推理是非常困难的,因为这些大型语言模型有几个特性。首先,它们非常大,所以它不适合在一个GPU上。这就是想象Excel不适合在一个GPU上。你知道,想象你日常运行的某个应用程序不适合在一台计算机上,就像一个视频游戏不适合在一台计算机上。而且事实上,大多数应用程序在过去的超大规模计算中,许多人的应用程序都适合同一台计算机。
现在突然出现了一个推理应用程序,你正在与这个聊天机器人互动。这个聊天机器人需要一个超级计算机在后端运行它。这就是未来,这些聊天机器人是生成性的,这些聊天机器人有数万亿的Token,数万亿的参数,它们必须以交互速率生成Token。
现在,这意味着什么?好吧,3个Token大约是一个单词,我们正在尝试生成这些Token。当你与它互动时,你希望Token尽快回到你身边,尽可能快地阅读它。所以生成Token的能力非常重要。你必须在这个模型的多个GPU上分配工作,这样你就可以实现几件事情。
一方面,你希望有吞吐量,因为吞吐量降低了生成每个Token的成本。所以你的吞吐量决定了服务的成本。另一方面,你有一个交互速率,即每秒生成的Token数,这与每个用户的服务质量有关。所以这两件事相互竞争,我们必须找到一种方法,在所有这些不同的GPU上分配工作,并以一种使我们能够实现两者的方式瘫痪它。
事实证明,搜索空间是巨大的。你知道,我告诉你会涉及到数学,每个人都在说,哦,亲爱的,我刚才看到有人喘气,当我挂上那张幻灯片时。
你看看,这个右边的y轴是每秒数据中心吞吐量的Token。x轴是每秒交互性的Token。注意右上角是最好的。你希望交互性非常高。每个用户的每秒Token数。你希望每秒每个数据中心的Token数非常高。右上角是非常好的。
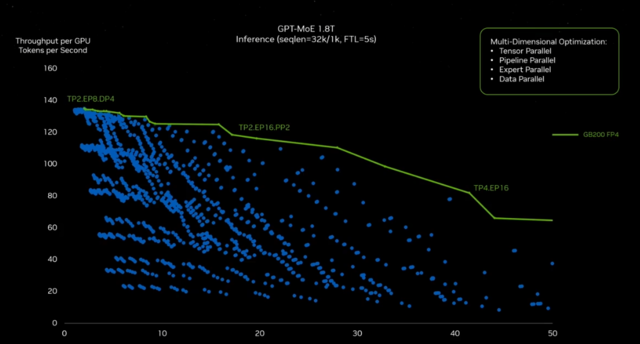
然而,这非常困难。为了让我们能够在每一个这些交叉点,x、y坐标上找到最佳答案,你必须查看每一个x、y坐标。所有这些蓝色的点都来自某种重新分区的软件。
一些优化解决方案必须去找出是否使用张量并行、专家并行、流水线并行或数据并行,并将这个巨大的模型分布在所有这些不同的GPU上,并保持你需要的性能。如果没有NVIDIA GPU的可编程性,这个探索空间将是不可能的。所以我们可以,因为有了CUDA,因为我们有如此丰富的生态系统,我们可以探索这个宇宙并找到那个绿色的屋顶线。你会发现你得到了TP2、EPA、DP4,这意味着在两个GPU上进行2个并行,8个专家并行,4个数据并行。注意在另一端,你有4个张量并行和16个专家并行。这个软件的配置、分布,它是一个不同的运行时,会产生这些不同的结果。你必须去发现那个屋顶线。好吧,这只是一个模型。这只是一个计算机配置。想象一下全世界正在创造的所有模型和所有不同的系统配置。
所以现在你理解了基础知识,让我们来看看Blackwell与Hopper的推理比较。这是一件了不起的事情,因为我们创造了一个为万亿参数生成性AI设计的系统,Blackwell的推理能力是惊人的。事实上,它是Hopper的30倍。对于像ChatGPT这样的大型语言模型,蓝线是Hopper。我给了你,想象我们没有改变Hopper的架构,我们只是让它变成了一个更大的芯片。我们只是使用了最新的、最棒的10TB每秒。我们将两个芯片连接在一起。我们得到了这个巨大的2080亿参数芯片。如果我们没有改变其他任何东西,我们的表现会怎样?结果非常出色。这就是紫色线,但不如它可能的那么好。这就是FP4张量核心、新的变换器引擎,以及非常重要的MV长度开关的原因。所有这些GPU都必须共享结果,部分产品,每当它们进行所有到所有聚集时,每当它们相互通信时。MV链接开关的通信速度几乎是我们过去使用最快网络的10倍。
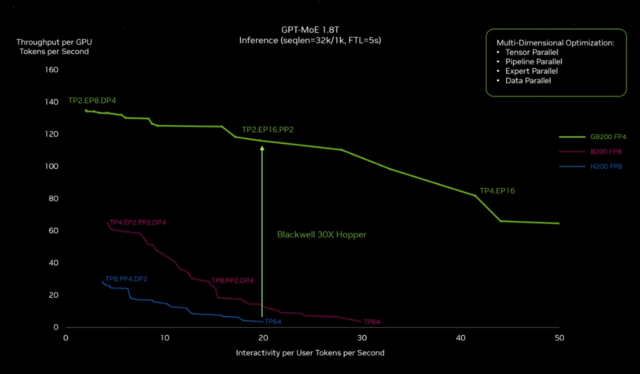
好的,所以Blackwell将是一个惊人的生成性AI系统。在未来,数据中心将被看作是AI工厂。AI工厂的生活目标是在这个设施中产生收入,产生智能,而不是像上一次工业革命中的交流发电机那样产生电力。这种能力非常重要。
Blackwell的兴奋程度真的非常高。你知道,当我们一年半前,两年前,我想,两年前当我们开始推出Hopper时,我们有幸有两家CSP加入我们的发布会,我们非常高兴。所以我们现在有更多的客户了。
对Blackwell的兴奋程度难以置信。难以置信。而且有各种各样的配置。当然,我向你展示了滑入Hopper外形尺寸的配置,所以升级很容易。
我向你展示了一些例子,它们是液体冷却的,是它的极端版本。整个机架通过MV Link 672连接。Blackwell将向全世界的AI公司推出,现在有这么多公司在不同的模态中做着惊人的工作。每个CSP都准备好了。所有OEM和ODM,区域性云,主权AI和全球电信公司都在签约推出Blackwell。
Blackwell将成为我们历史上最成功的产品发布,所以我迫不及待地想看到那一天。我想感谢一些合作伙伴加入我们。AWS正在为Blackwell做准备。他们将建立第一个GPU,即安全AI。他们正在构建一个222 x FLOPS的系统。
你知道,就在刚才,当我们激活数字孪生时,如果你看到了,所有这些集群都下来了。顺便说一下,那不仅仅是艺术,那是我们正在建造的数字孪生。它将有多大。除了基础设施,我们还在与AWS一起做很多事情。我们的Cuda正在加速Sagemaker AI。
Amazon Robotics正在使用NVIDIA Omniverse和Isaac Sim与我们合作。AWS Health已经将NVIDIA Health集成到其中。所以AWS真正深入到了加速计算。Google也在为Blackwell做准备。GCP已经拥有了数百个H1、T Force、L Force,一系列NVIDIA CUDA GPU。他们最近宣布了一个跨越所有这些的Gemma模型。我们正在努力优化和加速GCP的每一个方面。
我们正在加速数据处理引擎Data Procs,他们的数据处理引擎Jax,XLA,Vertex AI,以及用于机器人的Mujoko。所以我们正在与Google和GCP合作,跨越一系列倡议。Oracle正在为Blackwell做准备。Oracle是我们NVIDIA DGX Cloud的伟大合作伙伴,我们也在一起加速一些对许多公司来说非常重要的事情,Oracle数据库。
Microsoft正在加速,并且正在为Blackwell做准备。Microsoft,NVIDIA与Microsoft有着广泛的合作伙伴关系。我们正在加速,可以加速你在Microsoft Azure中聊天时使用的许多服务,显然是AI服务,很可能是NVIDIA在后台进行推理和生成Token。
我们建造了,他们建造了最大的NVIDIA Finiband超级计算机,基本上是我们的数字孪生或物理孪生。我们正在将NVIDIA生态系统带到Azure。NVIDIA做了你的云到Azure。NVIDIA Omniverse现在托管在Azure中,NVIDIA Healthcare在Azure中,所有这些都与Microsoft Fabric深度集成和连接。整个行业都在为Blackwell做准备。
这就是我要向你们展示的。你们迄今为止看到的大多数Blackwell场景都是Blackwell的全保真设计,我们公司中的每一件事都有一个数字孪生。事实上,这个数字孪生的概念真的在传播,它帮助公司第一次就完美地构建非常复杂的东西。还有什么比创建一个数字孪生更令人兴奋的呢?建造一个在数字孪生中建造的计算机。所以让我向你们展示Wistron正在做什么。
为了满足NVIDIA加速计算的需求。Wistron,我们的领先制造合作伙伴之一,正在使用Omniverse SDK和API开发的自定义软件,为他们的新工厂建立NVIDIA DGX和HGX工厂历史记录的数字孪生。Wistron从数字孪生开始,将他们的多CAD和工艺仿真数据虚拟整合到统一视图中。在这个物理精确的数字环境中测试和优化布局,提高了工人效率51%。在建设过程中,Omniverse数字孪生被用来验证物理构建是否符合数字计划。早期识别任何差异有助于避免昂贵的变更订单,结果令人印象深刻。使用数字孪生帮助Wistron的工厂在一半的时间内上线,只需两个月半而不是五个月投入运营。Omniverse数字孪生帮助快速回退,测试新布局以适应新工艺或改善现有空间中的操作,并使用来自生产线上每台机器的实时IoT数据监控实时操作,最终使Wistron将端到端周期时间缩短了50%,缺陷率降低了40%。有了NVIDIA AI和Omniverse,NVIDIA的全球合作伙伴生态系统正在建设一个新的加速AI启用的数字化时代。
这就是我们将要做的事情。将来我们会首先在数字上制造一切,然后才会在物理上制造。人们问我,是怎么开始的?是什么让你们如此兴奋?是什么让你们决定全力以赴投入到这个不可思议的想法中?就是这样。等一下,伙计们。那将是一个如此的时刻。那就是当你不排练时会发生的事情。
黄仁勋介绍英伟达的AI微服务NIM
这是你们知道的,这是2012年的第一次接触,Alex Net。你把一只猫放进这台电脑,它出来说猫。你把100万个数字通过三个通道,RGB。这些数字对任何人来说都毫无意义。你把它放进这个软件,它会压缩它,减少它。它把它从一百万维减少到三个字母,一个向量,一个数字,它是泛化的。你可以有不同种类的猫,你可以有猫的前面和后面。你看着这个东西,你说,难以置信。你的意思是任何猫?是的,任何猫。它能够识别所有这些猫。我们意识到它是如何做到的,系统地,结构性地,它是可扩展的。你可以做得有多大?嗯,你想做多大就做多大。所以我们想象这是一种全新的编写软件的方式。今天,如你所知,你可以输入单词C,A,T,出来的是一只猫。它走了另一条路。我对吗?难以置信。怎么可能?就是这样。怎么可能你拿了三个字母,却从中生成了一百万像素,而且它有意义。那正是奇迹。
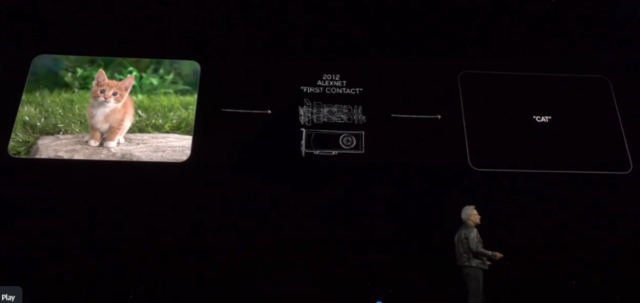
而在这里,就在十年后,我们识别文本,我们识别图像,我们识别视频和声音,我们不仅识别它们,我们理解它们的含义。这就是为什么我可以和你聊天的原因。它可以为你总结。它理解文本。它不仅识别英语,它理解英语。它不仅识别像素,它理解像素。你甚至可以在两种模态之间进行条件设置。你可以用语言来条件图像,并生成各种有趣的事情。如果你能理解这些东西,你还能理解你数字化的其他东西吗?我们之所以从文本和图像开始,是因为我们数字化了这些东西。但是我们还数字化了什么?事实证明,我们数字化了很多。蛋白质、基因和脑波。只要你能数字化的东西,只要它们的结构,我们可能就能从中学到一些模式。如果我们能从中学到模式,我们可能就能理解它的含义。如果我们能理解它的含义,我们可能就能生成它。所以,生成性AI革命就在这里。
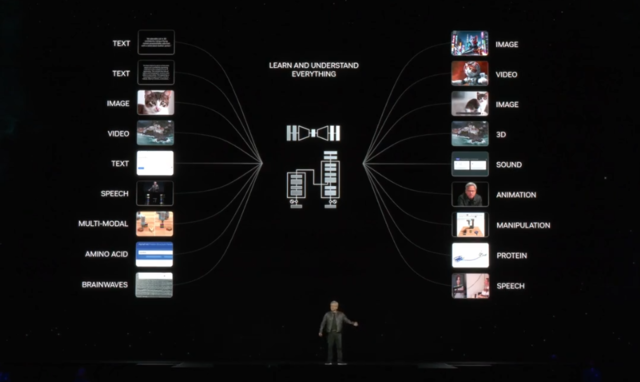
那么我们还能生成什么呢?我们还能学到什么?我们想学的其中一件事是气候。我们想学极端天气。我们想学如何预测未来天气,以足够高的分辨率在区域尺度上,这样我们才能在危险来临之前让人们远离危险。
极端天气给世界造成了1500亿美元的损失,当然不止这个数字。而且它不是均匀分布的。1500亿美元集中在世界上某些地区,当然,对世界上某些人来说。我们需要适应,我们需要知道即将发生什么。所以我们正在创建Earth 2,一个用于预测天气的地球数字孪生。我们发明了一个非凡的发明,叫做Core Diff,使用生成性AI以极高分辨率预测天气的能力。让我们来看看。
随着地球气候的变化,AI驱动的天气预测使我们能够更准确地预测和追踪像2021年在台湾及其周边地区造成广泛破坏的超级台风Chanthu这样的严重风暴。当前的AI预测模型可以准确预测风暴的路径,但它们的分辨率限制在25公里,可能会错过重要的细节。NVIDIA的Core Diff是一个革命性的新生成性AI模型,它在高分辨率雷达、同化WARF天气预测和ERA5再分析数据上进行了训练。使用Core Diff,像Chanthu这样的极端事件可以从25公里的分辨率超分辨率到2公里,速度是传统天气模型的1000倍,能源效率是传统天气模型的3000倍。通过结合NVIDIA的天气预测模型Forecast Net和像Core Diff这样的生成性AI模型的速度和准确性,我们可以探索数百甚至数千公里尺度的区域天气预测,以提供最准确、最糟糕和最可能的风暴影响的清晰画面。这些丰富的信息可以帮助减少生命和财产的损失。今天,Core Diff针对台湾进行了优化,但很快,生成性超采样将成为NVIDIA Earth 2推理服务的一部分,为全球许多地区提供服务。
天气公司必须信任全球天气预测的来源。我们正在共同努力加速他们的天气模拟。首先是原则基础的模拟。然而,他们也将要整合Earth 2和Core Diff,这样他们就可以帮助企业和国家进行区域高分辨率天气预测。所以如果你有一些天气预测,你想知道的话,可以联系天气公司。非常令人兴奋的工作。
视频医疗保健,这是我们15年前开始的。我们对此非常兴奋。无论是医学成像、基因测序还是计算化学。很可能NVIDIA是背后的计算。我们在这个领域做了这么多工作。今天,我们宣布我们将要做一些非常酷的事情。
想象所有这些用于生成图像和音频的AI模型,但不是图像和音频,因为它理解图像和音频,所有我们已经完成的基因和蛋白质的数字化,这些数字化能力现在通过机器学习传递,使我们理解生命语言,理解生命语言的能力。当然,我们第一次看到它的证据是在alpha fold中。这真的是一个非常非凡的事情,在几十年的痛苦工作后,世界只使用冷冻电子显微镜或晶体X射线晶体学等不同技术,费力地重建了蛋白质,200,000个,只用了不到一年的时间,Alpha Fold就重建了2亿个蛋白质,基本上是每个被测序的生物。这完全是革命性的。嗯,这些模型对于人们来说非常难以使用。所以我们要做的是,我们将为全世界的研究人员构建它们。而且不会只有一个。还会有我们创建的许多其他模型。所以让我向你们展示我们将要做什么。
新药物的虚拟筛选是一个计算上难以解决的问题。现有技术只能扫描数十亿种化合物,并且需要在数千个标准计算节点上花费数天时间来识别新的药物候选者。NVIDIA Bio Nemo和Nims通过使用Nims进行蛋白质结构预测,结合Alpha Fold分子生成和Mole MIM对接,以及Diff DOC,我们现在可以在几分钟内生成和筛选候选分子。Malmim可以连接到自定义应用程序,以引导生成过程,迭代优化所需属性。这些应用程序可以使用Bio Nemo微服务定义,也可以从头构建。在这里,一个基于物理的模拟优化了分子与目标蛋白质结合的能力,同时优化了其他有利的分子属性。同时,malmim生成高质量、药物样的分子,这些分子能够与目标结合并且可以合成,从而提高了开发成功药物的概率。更快。Bio Nemo正在启用药物发现的新范式,Nims提供按需微服务,可以组合构建强大的药物发现工作流程,如De Novo蛋白质设计或引导分子生成用于虚拟筛选。Bio nemo Nims正在帮助研究人员和开发人员重新发明计算药物设计。
NVIDIA,Momam,Corediff,还有许多其他的模型,计算机视觉模型,机器人模型,甚至一些非常棒的开源语言模型。这些模型是开创性的。然而,对于公司来说很难使用。你将如何使用它?你将如何将其引入你的公司并集成到你的工作流程中?你将如何打包它并运行它?还记得我之前说过的推理是一个非凡的计算问题吗?你将如何为每一个模型进行优化,并组装必要的计算堆栈,以便你可以在你的公司运行这些模型。所以我们有一个伟大的想法。我们将发明一种新的接收和操作软件的方式。这个软件基本上在一个数字盒子里,我们称之为容器,我们称之为NVIDIA Inference Micro Service,简称Nim。我想向你解释一下它是什么。一个Nim。它是一个预训练的模型。所以它非常聪明。它被打包并优化,可以在NVIDIA的安装基础上运行,这个基础非常庞大。里面的东西令人难以置信。你有所有这些预训练的稳定的VR开源模型。它们可能是开源的,可能是我们的合作伙伴之一,可能是我们自己创建的,就像视频时刻一样,它被打包,包括所有的依赖项。
所以CUDA,正确版本的cuDnn,tensor RTLM,分布在多个GPU上,尝试一个推理服务器,所有这些都完全打包在一起。它针对你是否拥有单个GPU、多个GPU或多个节点的GPU进行了优化,并且通过API连接,这些API非常简单易用。

现在想象一下AI API是什么,一个你只需要与之对话的接口。所以这个软件在未来将有一个非常简单的API,那个API叫做人类。这些软件包,令人难以置信的软件体,将被优化和打包。我们将把它放在网站上。你可以下载它,你可以带走它,你可以在任何云中运行它,你可以在自己的数据中心运行它,如果它适合的话,你可以在工作站上运行它。你所要做的就是来到AI NVIDIA.com。我们称之为NVIDIA Inference Microservice,但在公司内部,我们都称之为Nims。
想象一下,你知道,总有一天会有一个这样的聊天机器人,这些聊天机器人将只是在一个m中,你将组装一堆聊天机器人。这就是软件未来将被构建的方式。
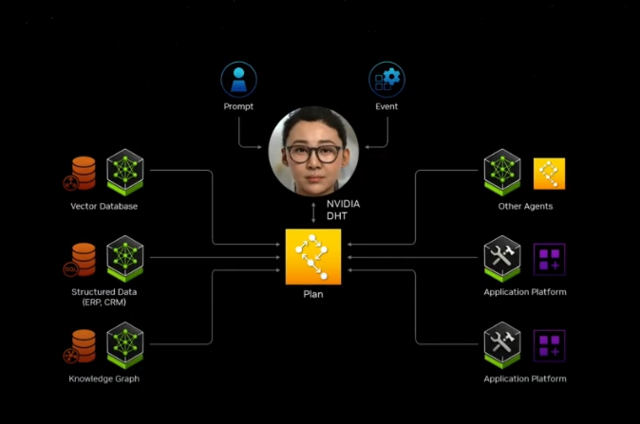
我们如何在未来构建软件?你不太可能从头开始编写它,或者编写一大堆Python代码或类似的东西。你很可能会组装一个AI团队。可能有一个超级AI,你使用它给你的任务,它会将其分解成一个执行计划。
这个执行计划的一部分可能会交给另一个Nim,那个Nim可能理解SAP。SAP的语言是ABAP。它可能理解Service Now并从他们的平台上检索一些信息。然后它将把那个结果交给另一个Nim,那个Nim去做一些计算。也许是一个优化软件,一个组合优化算法。也许是,你知道,一些,只是一些基本的计算器。也许是pandas做一些数值分析。然后它带着答案回来,并且它得到了每个人的答案的组合,因为它被呈现了正确的答案应该是什么样子。它知道正确的答案是什么,并且它会向你呈现。
我们可以每天在,你知道,每小时的顶部得到一个报告,它与构建计划或一些预测或一些客户警报或一些错误数据库或无论它是什么有关。我们可以使用所有这些名字来组装它。因为这些NIMs已经被打包并准备好在你的系统上工作,只要你的数据中心或云中有NVIDIA GPU,这些NIMs,它们将作为一个团队一起工作,做一些惊人的事情。所以我们决定这是一个如此伟大的想法,我们要去做。所以NVIDIA在公司各处都在运行MEMS。我们在各处创建聊天机器人。最重要的聊天机器人之一当然是芯片设计师聊天机器人。你可能不会感到惊讶。我们非常关心制造芯片。所以我们想要构建聊天机器人,AI副驾驶与我们的工程师共同设计。所以我们是这样做的。所以我们得到了一个Lama 2。这是一个70B。你知道,它被打包在一个Nam中。我们问它,你知道,CTL是什么。结果发现CTL是一个内部程序,有一个内部专有语言,但它认为CTL是组合时序逻辑。所以它描述了CTL的常规知识,但这对我们来说并不是很有用。所以我们给了它一堆新的例子。你知道,这和员工入职没有什么不同。我们说,谢谢你的答案。这完全是错误的。然后我们向他们展示了,这就是NVIDIA的CTL。好的。所以这就是NVIDIA的CTL。正如你所看到的,CTL代表计算跟踪库,这是有意义的。你知道,我们一直在跟踪计算周期。我写了这个程序。这很了不起吗?
所以我们的芯片设计师的生产力可以提高。这是你可以用Nim做的第一件事。你可以定制它。我们有一个叫做Nemo Microservice的服务,可以帮助你策划数据,准备数据,这样你就可以教这个AI。你可以微调它们,然后你可以设置边界。你甚至可以评估答案,评估其性能与其他例子相比。所以这叫做Nemo Microservice。
现在,这里出现的是三个元素,三个支柱,我们正在做的事情。第一个支柱当然是发明AI模型的技术,运行AI模型,并为你打包。首先是拥有AI技术。第二是帮助你修改。第三是为你微调的基础设施。如果你喜欢部署它,你可以在我们的基础设施上部署它,叫做DGX Cloud,或者你可以在本地部署。一旦你开发了它,它就是你的,你可以把它带到任何地方。所以实际上我们是一个AI铸造厂。我们将为你和行业做AI,就像TSMC为我们制造芯片一样。所以我们带着我们的大想法去找TSMC,他们制造了它,我们带着它走了。所以这里完全一样,AI铸造厂。这三个支柱是Nims,Nemo微服务和DGX Cloud。
你还可以教Nim理解你的专有信息。记住,在我们公司内部,我们的数据大部分不在云中。它在我们的公司内部。它一直在那里被使用。而且天哪,它基本上是模糊的智能。我们想拿走这些数据,学习它的含义,就像我们学习几乎任何我们刚才谈到的其他东西的含义一样,学习它的含义,然后将这些知识重新索引到一种叫做向量数据库的新类型的数据库中。所以你本质上是拿走结构化数据或非结构化数据,你学习它的含义,你编码这个含义。
所以现在这变成了一个AI数据库。在未来,一旦你创建了它,你可以和它对话。所以让我给你一个例子。假设你创建了一个,你有一堆多模态数据,一个很好的例子是PDF。所以你拿走PDF,你拿走你所有的pdf,所有的,哦,你最喜欢的,你知道,对你公司来说至关重要的东西,你可以编码它,就像我们编码猫的像素一样。它变成了向量,现在存储在你的向量数据库中。它变成了你公司的专有信息。一旦你有了这些专有信息,你可以和它聊天。它是一个智能数据库,所以你只是和数据聊天。和你聊天有多愉快?你知道,对于我们的软件团队来说,他们只是和错误数据库聊天,你知道,昨晚有多少错误?我们有没有任何进展?然后和你完成和这个错误数据库的对话后,你需要治疗。所以,我们还有另一个聊天机器人给你。你可以做。
好的,所以我们称之为Nemo检索器。之所以这样称呼,是因为最终它的工作是尽快检索信息。你只是和它聊天,嘿,检索这个信息给我。它去了,它把它带回来给你。你是说这个意思吗?你去了,是的,完美。好的。所以这就是所谓的Nemo检索器。Nemo服务帮助你创建所有这些东西。我们有所有这些不同的NIMs。我们甚至有数字人类的名称。我是Rachel。
你的AI护理经理。
好的,所以这是一个非常短的视频,但有很多视频要向你展示。我想是因为有很多其他的演示要向你展示,所以我不得不缩短这个视频。但这是Diana。她是一个数字人类Nim。你只是和她交谈,她在这个案例中连接到了Hippocratic AI的医疗保健大型语言模型。这真的很神奇。她对医疗保健的事情非常了解,你知道的。所以经过我的Dwight,我的软件工程副总裁与错误数据库聊天之后,你过来和Diane聊聊。Diane完全由AI动画制作,她是一个数字人类。
有很多公司想要建造。他们坐拥金矿。企业IT行业坐拥金矿。这是一座金矿,因为他们对工作方式有着深刻的理解。他们拥有多年来创造的所有这些惊人的工具,他们坐拥大量数据。如果他们能将这些金矿转化为副驾驶,这些副驾驶可以帮助我们做一些事情。所以几乎每个IT专营权,几乎每个拥有人们使用的有价值工具的IT平台,都坐拥着副驾驶和聊天机器人的金矿。
现在运行着世界上85%的财富500强公司的人力和客户服务运营的Service Now。他们正在使用NVIDIA AI Foundry构建Service Now Assist虚拟助手。
Cohecity支持着世界上的数据。他们坐拥着金矿,数百艾字节的数据,超过10,000家公司,Video AI Foundry正在与他们合作,帮助他们构建Gaia生成性AI代理。
Snowflake是一家在云中存储世界数字仓库的公司,每天为10,000家企业客户处理超过30亿次查询。Snowflake正在与NVIDIA AI Foundry合作,使用NVIDIA Nemo和Nims构建副驾驶。
世界上近一半的文件存储在本地,使用NETA和Video AI。AI Foundry正在帮助他们构建聊天机器人和副驾驶,就像那些向量数据库和检索器一样,使用NVIDIA、Nemo和Nims。我们与Dell有着极佳的合作关系。每个正在构建这些聊天机器人和生成性AI的人,当你准备运行它时,你将需要一个AI工厂。没有人比Dell更擅长为企业构建大规模的端到端系统。所以任何人,任何公司,每家公司在建造AI工厂时都需要考虑这一点。
黄仁勋介绍AI机器人技术
好的,让我们来谈谈机器人技术的下一个浪潮,AI机器人技术的下一个浪潮。到目前为止,我们谈论的所有AI都是一台计算机。数据以数字文本的形式进入一台计算机。AI通过阅读大量语言来模仿我们,预测下一个单词。它通过研究所有模式和所有其他先前的例子来模仿你。当然,它必须理解上下文等等。但一旦它理解了上下文,它本质上是在模仿你。我们将所有数据放入一个系统,如DGX,我们将其压缩成一个大型语言模型。数万亿的参数变成了数十亿。数万亿的Token变成了数十亿的参数。这些数十亿的参数变成了你的AI。
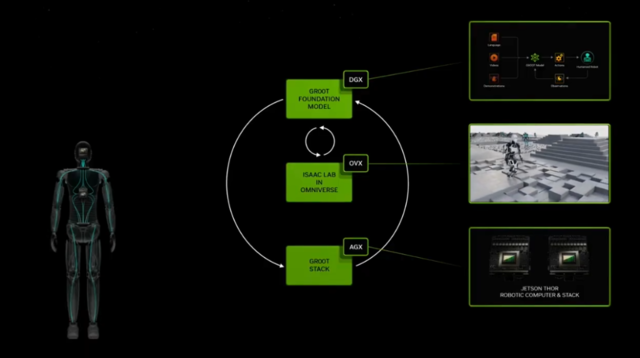
好吧,为了进入AI的下一个浪潮,即AI理解物理世界的浪潮,我们需要三台计算机。第一台计算机仍然是相同的计算机。它是那台AI计算机,现在将观看视频,也许它正在进行合成数据生成。也许会有很多人类的例子,就像我们有人类文本形式的例子一样,我们将有人类在动作形式上的例子。AI将观察我们,理解发生了什么,并尝试将其适应为自己在上下文中的行动。因为它可以用这些基础模型进行泛化,所以也许这些机器人也可以在物理世界中相当泛化地执行任务。所以我刚刚用非常简单的术语描述了大型语言模型本质上发生的事情,除了ChatGPT时刻,机器人技术的时刻可能就在拐角处。所以我们已经为机器人技术构建了端到端系统一段时间了。
我为这项工作感到非常自豪。我们有AI系统,DGX。我们有低级系统,称为AGX,用于自主系统,这是世界上第一个机器人处理器。当我们第一次构建这个东西时,人们问,你们在建造什么?它是一个SoC。它是一个芯片。它旨在非常低功耗,但它旨在高速传感器处理和AI。所以如果你想在汽车中运行变换器,或者你想在任何移动的东西中运行变换器,我们有完美的计算机给你。它叫做Jetson。所以顶部的DGX用于训练AI,Jetson是自主处理器。在中间,我们需要另一台计算机。而大型语言模型必须从你提供的例子中受益,然后进行人类反馈的强化学习。那么机器人的强化学习人类反馈是什么呢?好吧,它是强化学习物理反馈。这就是你如何让机器人对齐。这就是你让机器人知道,当它学习这些动作能力和操纵能力时,它将适当地适应物理定律。所以我们需要一个代表世界数字的模拟引擎,让机器人有一个健身房去学习如何成为机器人。我们称之为虚拟世界Omniverse。运行Omniverse的计算机叫做OVX。而OVX计算机本身,托管在Azure云中。
好的,所以基本上我们建造了这三样东西,这三套系统。在它们之上,我们为每一个都有算法。现在我要给你们展示一个超级例子,展示AI和Omniverse如何一起工作。我要给你们看的例子是疯狂的,但它将非常接近明天。这是一个机器人建筑。这个机器人建筑叫做仓库。在机器人建筑里面有一些自主系统。一些自主系统将被称为人类,一些自主系统将被称为叉车。这些自主系统将互相交互,当然,是自动的。它将由这个仓库监督,以确保每个人都安全。
这个仓库本质上是一个空中交通管制员。每当它看到某件事发生时,它会重新定向交通并给出新的路径点,给机器人和人们。他们将确切地知道该做什么。
这个仓库,这个建筑,你也可以和它交谈,当然,你可以问它。嘿,你知道,SAP中心,你今天感觉怎么样?所以你可以问仓库同样的问题。基本上,我刚刚描述的系统将拥有Omniverse Cloud,它托管着虚拟模拟和在DGX Cloud上运行的AI,所有这些都在实时运行。让我们来看看。
重工业的未来始于数字孪生。AI代理帮助机器人、工人和基础设施在复杂的工业空间中导航不可预测的事件,将在精密的数字孪生中首次构建和评估。这个100,000平方英尺仓库的Omniverse数字孪生作为一个模拟环境运行,集成了数字工人、AMRS运行NVIDIA Isaac接收器堆栈,来自100个模拟天花板摄像头的整个仓库的集中活动地图,使用NVIDIA Metropolis和Amr路线规划与NVIDIA QOP软件,在这个物理精确的模拟环境中进行的AI代理的循环测试使我们能够评估和完善系统如何适应现实世界的不可预测性。在这里,沿着这个AMR计划的路径发生了一起事件,阻挡了它的去路。NVIDIA Metropolis更新并发送了一个实时占用图到QOP,在那里计算了一个新的最佳路径。Amr能够看到角落周围,并利用生成性AI驱动的Metropolis Vision基础模型提高其任务效率。运营商甚至可以使用自然语言提问。视觉模型理解微妙的活动,并可以提供立即的洞察力以改进操作。所有的传感器数据都是在模拟中创建的,并传递给实时运行的AI,作为NVIDIA推理微服务或MEMS。当AI准备在物理孪生,即真实的仓库中部署时,我们将Metropolis和Isaac Nimms连接到真实传感器,并具有持续改进数字孪生和AI模型的能力。
让我们来看看这将如何工作。我们与西门子有一个伟大的合作伙伴关系。西门子是世界上最大的工业工程和运营平台。你已经看到了这么多不同的公司在工业领域。重工业是它最伟大的最后边疆之一,我们终于拥有了必要的技术来真正产生影响。西门子正在构建工业元宇宙。今天,我们宣布西门子正在将他们的明珠加速器连接到NVIDIA Omniverse。让我们来看看。
CMS技术每天都在为每个人改变。我们的领先产品生命周期管理软件Tim Sendax,来自西门子加速器平台,每天被我们的客户用来大规模开发和交付产品。
现在我们正在通过将NBDII和Omniverse技术整合到Team Center X中,将真实和附加世界带得更近。Omniverse API使数据互操作性和基于物理的渲染能够应用于工业规模的设计和制造项目。我们的客户,HD Hyundai,是可持续船舶制造的市场领导者,经常建造包含超过700万个离散部件的氨和氢动力船。通过Omniverse API,Tim Center X让像HD Hyundai这样的公司能够交互式地统一和可视化这些庞大的工程数据集,并集成生成性AI来生成3D对象或HRI背景,以在上下文中查看他们的项目。结果是一个超直观的、基于物理的数字孪生,消除了浪费和错误,节省了大量的成本和时间。我们正在为协作而建设这个,无论是跨过更多的西门子加速器工具,如西门子Annix或Star CCM+,还是跨过团队在他们最喜欢的设备上一起工作。这只是一个开始。与NVIDIA合作,我们将在西门子加速器产品组合中带来加速计算、生成性AI和Omniverse整合。
专业的配音演员恰好是我的好朋友,Roland Bush,他恰好是西门子的CEO。
一旦你将Omniverse连接到你的工作流程中,从设计到工程,再到制造计划,一直到数字孪生运营,一旦你将一切连接在一起,你会惊讶地发现你可以获得多少生产力。突然之间,每个人都在同一个基本事实的基础上运作。你不需要交换数据和转换数据,犯错误。每个人都在同一个基本事实的基础上工作,从设计部门到艺术部门,建筑部门,一直到工程部门,甚至是市场部门。让我们来看看日产如何将Omniverse整合到他们的工作流程中,这一切都是因为所有这些美妙的工具和我们正在合作的开发者。来看看。
那不是动画。那是Omniverse。今天,我们宣布Omniverse Cloud流式传输到Vision Pro,而且非常奇怪,你可以走进虚拟的门。当我从那辆车里出来时,每个人都这样做。这真的非常了不起。Vision Pro连接到Omniverse门户,让你进入Omniverse。因为所有这些CAD工具和所有这些不同的设计工具现在都与Omniverse集成和连接,你可以有这样的工作流程。真的不可思议。
让我们来谈谈机器人技术。所有会动的东西都将是机器人。这一点毫无疑问。这更安全,更方便。最大的行业之一将是汽车行业。我们从计算机系统开始构建了一个机器人堆栈,就像我提到的,包括自动驾驶汽车,包括今年年底或明年年初将在奔驰和随后不久的捷豹路虎上出货的自动驾驶云应用程序。所以这些自主机器人系统是软件定义的。它们需要大量的工作,具有计算机视觉,显然有人工智能控制和规划,所有种类非常复杂的技术,需要多年时间来完善。我们正在构建整个堆栈。然而,我们为整个汽车行业开放了我们的整个堆栈。这就是我们在每一个行业中的工作方式。我们尽力构建尽可能多的东西,以便
我们理解它。但然后我们将其开放,以便每个人都可以访问它,无论你是否想要购买我们的计算机,这是世界上唯一功能齐全、安全的自动驾驶汽车质量计算机,或者上面的操作系统,或者当然,我们的数据中心,它基本上在世界上每家自动驾驶汽车公司中。无论如何,我们都很高兴。
今天,我们宣布世界上最大的电动汽车公司比亚迪(BYD)正在采用我们的下一代产品。它被称为Thor。Thor是为变换器引擎设计的。我们的下一代自动驾驶汽车计算机Thor将被比亚迪使用。
你可能不知道这个事实,我们有超过一百万的机器人开发者。我们创造了Jetson,这个机器人计算机。我们为此感到非常自豪。在它上面运行的软件量是惊人的,但我们之所以能够做到这一点,是因为它是100%代码兼容的。我们公司所做的一切都是为了我们的开发者服务。通过我们能够维护这个丰富的生态系统,并使其与你们从我们这里访问的一切都兼容,我们可以将所有这些令人难以置信的能力带到这个我们称之为Jetson的小计算机上,一个机器人计算机。我们今天还宣布了一个非常先进的新SDK。我们称之为Isaac Perceptor。
今天的大多数机器人都是预编程的。它们要么跟随地面上的轨道,要么是数字轨道,或者它们会跟随April标签。但在将来,它们将具有感知能力。你希望这样是因为这样你可以轻松地编程它。你说,我想让你从A点到B点,它会找出到达那里的路线。所以通过只编程航点,整个路线可以是自适应的,整个环境可以被重新编程,就像我在一开始展示的仓库一样。如果你使用预编程的AGV,如果那些箱子掉下来,它们就会全部堵塞在那里,等待某人清理。
现在有了Isaac Perceptor,我们有了令人难以置信的最先进视觉里程计、3D重建,除了3D重建,还有深度感知。之所以需要这样做,是为了让你可以用两种模式来监控世界上正在发生的事情。Isaac Perceptor,今天使用最多的机器人是制造臂。它们也是预编程的,计算机视觉算法、AI算法、控制和路径规划算法都是几何感知的,计算上非常密集。我们已经使这些CUDA加速。所以我们有世界上第一个CUDA加速的运动规划器,它是几何感知的。你把东西放在它前面,它会提出一个新的计划,并绕过它。它具有出色的3D物体姿态估计的感知能力。不仅仅是2D中的姿态,而是3D中的姿态。所以它必须想象周围是什么,以及如何最好地抓住它。所以基础姿态、握持基础和关节算法现在都可以使用。我们称之为Isaac Manipulator。它们也只在VDS计算机上运行。
我们开始做一些真正伟大的工作,在下一代机器人技术中,很可能是类人机器人。我们现在拥有了必要的技术,正如我之前所描述的,下一代机器人技术很可能是一种通用的人类机器人。我们知道这一点,因为我们有更多的模仿训练数据可以提供给机器人,因为我们是以非常相似的方式构建的。很可能类人机器人在我们的世界中会更加有用,因为我们创造了一个我们可以互操作并良好工作的世界。我们设置的工作站、制造和物流,都是为人类设计的。所以这些类人机器人在部署时可能会更加高效,而我们正在创建的,就像我们对其他机器人一样,从基础模型开始,学习观看视频、人类图像、人类例子。它可以是视频形式的,也可以是虚拟现实形式的。然后我们创建了一个名为Isaac Reinforcement Learning Gym的健身房,这个健身房允许类人机器人学习如何适应物理世界。然后是一个令人难以置信的计算机,这个计算机将进入一个机器人或类人机器人,称为Thor。它被设计为变换器引擎。我们将其中的几个组合成一个视频。这是你真的会喜欢的东西。来看看。
NVIDIA的灵魂。计算机图形、物理、人工智能的交汇点,都在这一刻显现出来。那个项目的名称,通用机器人。0,0,3。我知道。非常好。好吧,我认为我们有一些特别的嘉宾。我们有吗?

嘿,伙计们。所以我了解到你们是由Jetson驱动的。它们是由Jetsons驱动的,小Jetson机器人计算机。在里面,它们在Isaacson中学会走路。女士们,先生们,这是橙色和著名的绿色。它们是迪士尼的BDX机器人。令人惊叹的迪士尼研究。过来吧,伙计们。让我们结束。让我们走。你们要去哪里?我坐在这里。别害怕。过来。绿色。快点。你在说什么?不,现在不是吃饭的时间。


(Jetson机器人)
我会的。我会给你们一个小吃的。让我快速结束。
首先,一场新的工业革命。每个数据中心都应该是加速的。未来几年,价值1万亿美元的安装数据中心将现代化。第二,因为我们带来的计算能力,一种新的软件开发方式出现了,生成性AI,它将创造新的基础设施,专门用于做一件事,而不是为多用户数据中心,而是为AI生成器。这些AI生成器将创造非常有价值的软件,这是一场新的工业革命。
第二,这场革命的计算机,这一代的计算机,生成性AI,数万亿参数,Blackwell,令人疯狂的计算机和计算能力。第三,我正在尝试集中注意力。做得好。第三,新的计算机创造了新的软件类型。新的软件类型应该以新的方式分发,这样它可以一方面成为云中的一个端点,易于使用,但仍然允许你带走它,因为你的智能应该被打包成一种方式,允许你带走它。我们称它们为NIMs。
第三,这些NIMs将帮助你创建未来的新类型应用程序,不是完全从头开始编写的应用程序,而是你将整合它们。就像团队创建这些应用程序一样。我们有一个极好的能力,介于Nims(AI技术)、Nemo(工具)和DGX Cloud(基础设施)之间,我们的AI Foundry将帮助你创建专有应用程序,专有聊天机器人。
最后,未来所有会动的东西都将是机器人。你不会是唯一的一个。这些机器人系统,无论是类人AMRS、自动驾驶汽车、叉车、操纵臂,它们都需要一件事,巨大的体育场、仓库、工厂。可以有机器人工厂,协调工厂的工厂,制造汽车的机器人生产线。这些系统都需要一件事。它们需要一个平台,一个数字平台,一个数字孪生平台。我们称之为Omniverse,机器人世界的操作系统。
这些是我们今天谈论的五件事。当我们谈论GPU时,NVIDIA是什么样子?当我想到GPU时,我有一幅非常不同的图像。首先,我看到的是一堆软件堆栈和类似的东西。其次,我看到的是我们今天向你宣布的。这是Blackwell,这是平台。
令人惊叹的处理器,MV Link交换机,网络系统。系统设计是一个奇迹。这就是Blackwell,这就是在我脑海中GPU的样子。
谢谢你。祝大家有一个愉快的GTC。谢谢大家的到来。