Meta发布了开源生成式人工智能模型 Llama 系列的最新产品:Llama 3。或者,更准确地说,该公司已经开源了新的 Llama 3 系列中的两个模型,其余模型将在未来某个不确定的日期推出。
Meta 称,与上一代 Llama 模型 Llama 2 8B 和 Llama 2 70B 相比,新模型 Llama 3 8B(包含 80 亿个参数)和 Llama 3 70B(包含 700 亿个参数)在性能上有了"重大飞跃"。(参数从本质上定义了人工智能模型处理问题的能力,比如分析和生成文本;一般来说,参数数越高的模型比参数数越低的模型能力越强)。事实上,Meta 表示,就各自的参数数而言,Llama 3 8B 和 Llama 3 70B 是在两个定制的 24,000 GPU 集群上训练出来的,是当今性能最好的生成式人工智能模型之一。
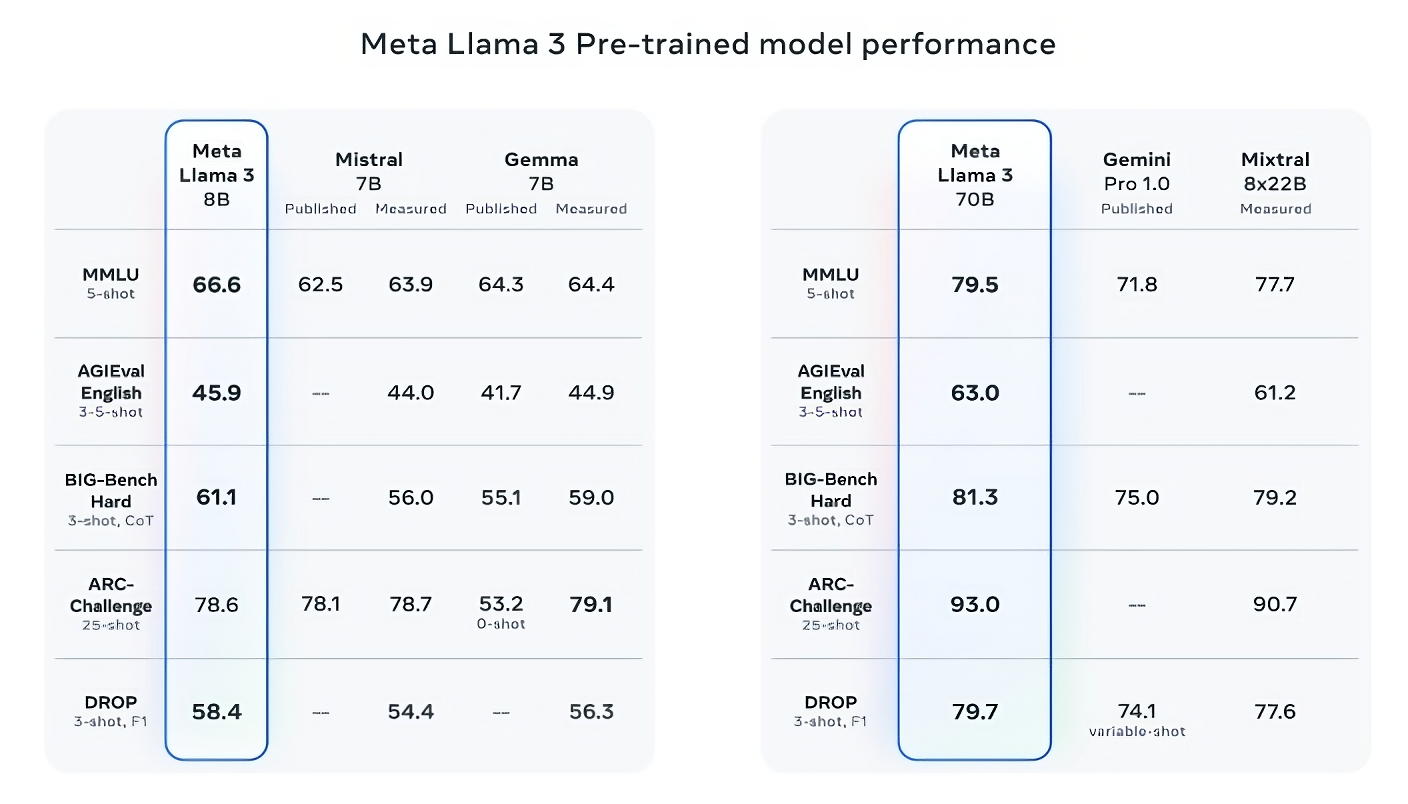
话说得很满,那么,Meta 公司是如何证明这一点的呢?该公司指出了 Llama 3 模型在 MMLU(用于测量知识)、ARC(用于测量技能习得)和 DROP(用于测试模型对文本块的推理能力)等流行的人工智能基准上的得分。正如我们之前所写,这些基准的实用性和有效性还有待商榷。但无论好坏,它们仍然是 Meta 等人工智能玩家评估其模型的少数标准化方法之一。
在至少九项基准测试中,Llama 3 8B 优于其他开源模型,如 Mistral 的Mistral 7B和 Google 的Gemma 7B,这两个模型都包含 70 亿个参数:这些基准包括:MMLU、ARC、DROP、GPQA(一组生物、物理和化学相关问题)、HumanEval(代码生成测试)、GSM-8K(数学单词问题)、MATH(另一种数学基准)、AGIEval(解决问题测试集)和 BIG-Bench Hard(常识推理评估)。
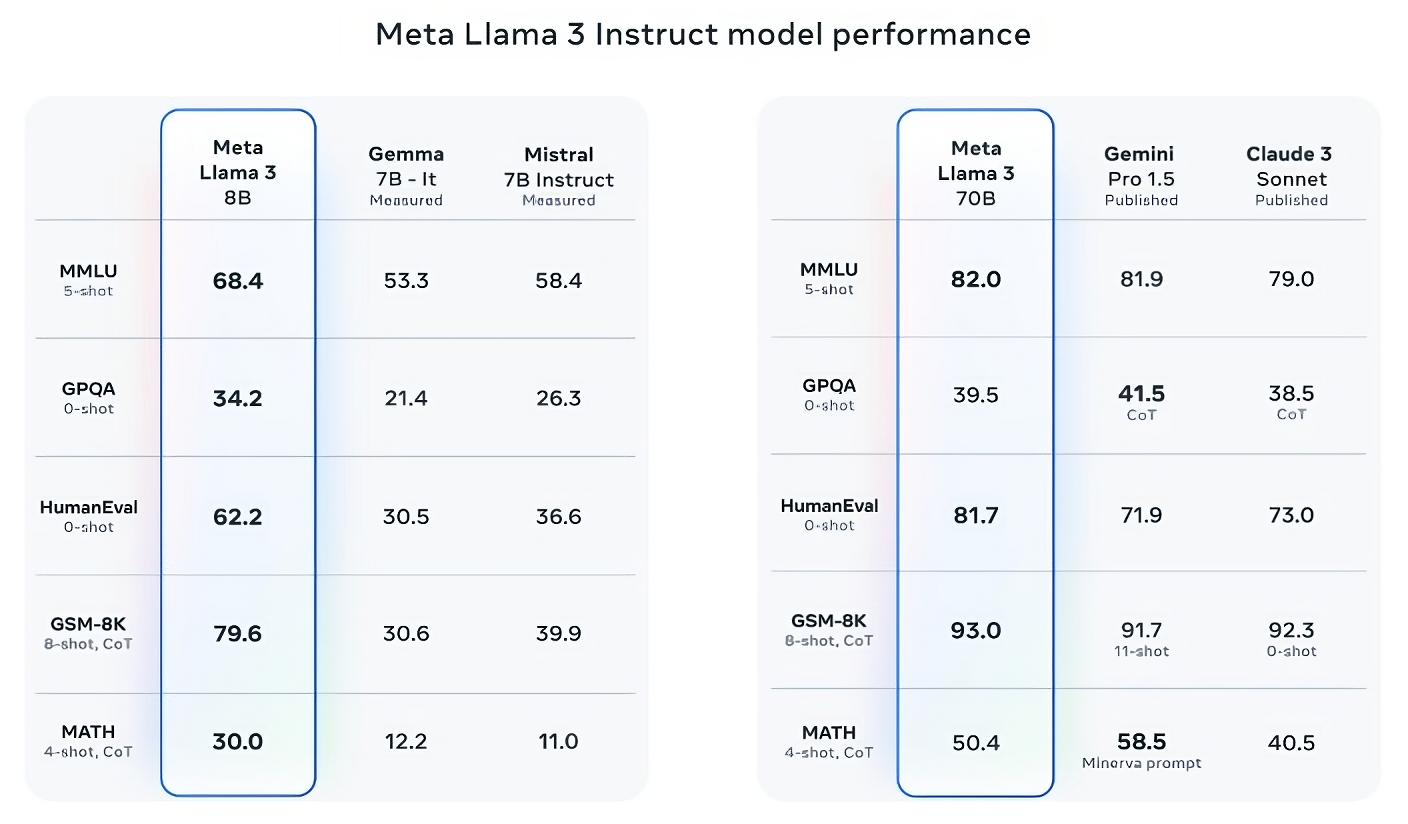
现在,Mistral 7B 和 Gemma 7B 并不完全处于最前沿(Mistral 7B 于去年 9 月发布),在 Meta 引用的一些基准测试中,Llama 3 8B 的得分仅比这两款产品高几个百分点。但 Meta 还声称,参数数更多的 Llama 3 型号 Llama 3 70B 与旗舰生成式人工智能模型(包括Google Gemini 系列的最新产品 Gemini 1.5 Pro)相比也具有竞争力。
图片来源:Meta
Llama 3 70B 在 MMLU、HumanEval 和 GSM-8K 三项基准测试中均优于 Gemini 1.5 Pro,而且,虽然它无法与 Anthropic 性能最强的 Claude 3 Opus 相媲美,但 Llama 3 70B 在五项基准测试(MMLU、GPQA、HumanEval、GSM-8K 和 MATH)中的得分均优于 Claude 3 系列中性能最弱的 Claude 3 Sonnet。
值得注意的是,Meta 还开发了自己的测试集,涵盖了从编码、创作到推理、总结等各种用例,令人惊喜的是,Llama 3 70B 在与 Mistral Medium 模型、OpenAI 的 GPT-3.5 和 Claude Sonnet 的竞争中脱颖而出!- Llama 3 70B 在与 Mistral 的 Mistral Medium 模型、OpenAI 的 GPT-3.5 和 Claude Sonnet 的竞争中脱颖而出。Meta 表示,为了保持客观性,它禁止其建模团队访问这组数据,但很明显,鉴于 Meta 自己设计了这项测试,我们必须对结果持谨慎态度。

在质量方面,Meta 表示,新 Llama 模型的用户可以期待更高的"可操控性"、更低的拒绝回答问题的可能性,以及更高的琐碎问题、与历史和 STEM 领域(如工程和科学)相关的问题和一般编码建议的准确性。这在一定程度上要归功于一个更大的数据集:一个由 15 万亿个标记组成的集合,或者说一个令人难以置信的 750,000,000,000 单词,是 Llama 2 训练集的七倍。
这些数据从何而来?Meta 公司不愿透露,只表示数据来自"公开来源",包含的代码数量是 Llama 2 训练数据集的四倍,其中 5%包含非英语数据(约 30 种语言),以提高非英语语言的性能。Meta 还表示,它使用了合成数据(即人工智能生成的数据)来创建较长的文档,供 Llama 3 模型训练使用,由于这种方法存在潜在的性能缺陷,因此颇受争议。
Meta 在一篇博文中写道:"虽然我们今天发布的模型仅针对英语输出进行了微调,但数据多样性的增加有助于模型更好地识别细微差别和模式,并在各种任务中表现出色。"
许多生成式人工智能供应商将训练数据视为一种竞争优势,因此对训练数据和相关信息守口如瓶。但是,训练数据的细节也是知识产权相关诉讼的潜在来源,这是另一个不愿意透露太多信息的原因。最近的报道显示,Meta 公司为了追赶人工智能竞争对手的步伐,曾一度不顾公司律师的警告,将受版权保护的电子书用于人工智能训练;包括喜剧演员莎拉-西尔弗曼(Sarah Silverman)在内的作者正在对 Meta 和 OpenAI 提起诉讼,指控这两家公司未经授权使用受版权保护的数据进行训练。
那么,生成式人工智能模型(包括 Llama 2)的另外两个常见问题--毒性和偏差又是怎么回事呢?Llama 3 是否在这些方面有所改进?Meta 声称:是的。
Meta 表示,公司开发了新的数据过滤管道,以提高模型训练数据的质量,并更新了一对生成式人工智能安全套件 Llama Guard 和 CybersecEval,以防止 Llama 3 模型和其他模型的滥用和不必要的文本生成。该公司还发布了一款新工具 Code Shield,旨在检测生成式人工智能模型中可能引入安全漏洞的代码。
不过,过滤并非万无一失,Llama Guard、CybersecEval 和 Code Shield 等工具也只能做到这一步。我们需要进一步观察 Llama 3 型号在实际运用时的表现如何,包括学术界对其他基准的测试。
Meta公司表示,Llama 3模型现在已经可以下载,并在Facebook、Instagram、WhatsApp、Messenger和网络上为Meta公司的Meta人工智能助手提供支持,不久将以托管形式在各种云平台上托管,包括AWS、Databricks、Google Cloud、Hugging Face、Kaggle、IBM的WatsonX、Microsoft Azure、NVIDIA的NIM和Snowflake。未来,还将提供针对 AMD、AWS、戴尔、英特尔、NVIDIA 和高通硬件优化的模型版本。
而且,功能更强大的型号即将问世。Meta 表示,它目前正在训练的 Llama 3 模型参数超过 4000 亿个--这些模型能够"用多种语言交流"、接收更多数据、理解图像和其他模式以及文本,这将使 Llama 3 系列与 Hugging Face 的Idefics2 等公开发布的版本保持一致。

"我们近期的目标是让 Llama 3 成为多语言、多模态、具有更长上下文的产品,并继续提高推理和编码等核心(大型语言模型)功能的整体性能,"Meta 在一篇博文中写道。"还有很多事情要做"。