大模型“套壳”的回旋镖,这次扎到了美国科研团队身上。最近几天,斯坦福大学AI团队陷入抄袭风波,被质疑“套壳”清华系大模型开源成果,引起舆论哗然。起因是这个团队在5月29日发布了一个多模态大模型Llama3-V,声称只花500美元训练,就能实现在多个基准测试中比肩GPT-4的性能。但很快有人发现,该模型跟清华系大模型创企面壁智能5月发布的MiniCPM-Llama3-V 2.5模型有不少相似处,而且没有任何相关致谢或引用。

一开始团队面对抄袭质疑还嘴硬否认,只承认使用了MiniCPM-Llama3-V的分词器,后来证据越来越多——不仅架构和代码高度相似,而且被发现作者曾在Hugging Face导入MiniCPM-V的代码,然后改名成Llama3-V。
最绝的是Llama3-V连国产AI模型的“胎记”都抄走了,跟MiniCPM-V一样能识别清华战国竹简“清华简”,而且连出错的样例、在高斯扰动验证后的正确和错误表现方面都高度相似。
而基于非公开训练数据的清华简识别能力,是面壁MiniCPM团队耗时数月、从卷帙浩繁的清华简中逐字扫描并逐一数据标注,融入模型中的。
面对铁一般的证据,Llama3-V团队终于立正挨打,一套道歉流程行云流水,火速删库、发文致歉外加撇清关系。其中来自斯坦福计算机科学专业的两位作者澄清说他们并未参与代码工作,所有代码都是毕业于南加州大学的Mustafa Aljadery负责的,他一直没交出训练代码。

▲Llama3-V作者:Siddharth Sharma(左)、Aksh Garg(中)、Mustafa Aljadery(右)
这样看来,Llama3-V团队并不能算严格意义上的斯坦福团队,不过因为此事声誉受损的斯坦福大学至今没有采取任何公开措施。
面壁智能团队的回应很有涵养。今日,面壁智能联合创始人兼CEO李大海在朋友圈回应说“深表遗憾”,这也是一种“受到国际团队认可的方式”,并呼吁大家共建开放、合作、有信任的社区环境。

一、网友细数五大证据,作者删库跑路、不打自招
Llama3-V的模型代码与MiniCPM-Llama3-V 2.5高度相似,同时其项目页面没有出现任何与MiniCPM-Llama3-V 2.5相关的声明。
公开的基准测试结果显示,Llama3-V在所有基准测试中优于GPT-3.5,在多个基准测试中优于GPT-4,且模型尺寸是GPT-4V的1/100,预训练成本为500美元。这也使得该模型一经就冲上Hugging Face首页。
但当细心网友发现Llama3-V疑似“套壳”面壁智能此前发布的开源多模态模型MiniCPM-Llama3-V 2.5,在评论区发表评论后,Llama3-V项目作者最初否认抄袭,并称他们的项目开始时间先于MiniCPM-Llama3-V 2.5发布,只是使用了MiniCPM-Llama3-V 2.5的分词器。
当网友抛出三大事实质疑后,Llama3-V的做法是——不回应直接删除网友评论。
昨日下午,网友在MiniCPM-V页面下将事情经过全部公开,并公开@面壁智能让其项目团队投诉。

当日晚间,面壁智能研发人员发布推文,其验证结果也印证了网友的说法,Llama3-V与MiniCPM-Llama3-V 2.5高度相似。同时公开喊话Llama3-V研发团队:“鉴于这些结果,我们担心很难用巧合来解释这种不寻常的相似性。我们希望作者能够对这个问题给出官方解释,相信这对开源社区的共同利益很重要。”

以下就是Llama3-V被质疑抄袭MiniCPM-Llama3-V 2.5的五大证据:
1、Llama3-V的代码是对MiniCPM-Llama3-V 2.5的重新格式化,其模型行为检查点的噪声版本高度相似。
其中,Llama3-V只是对代码进行了重新格式化和变量重命名,包括但不限于图像切片、标记器、重采样器和数据加载。面壁智能研发人员也证实,Llama3-V有点类似于MiniCPM-Llama3-V 2.5的噪声版本。

2、起初网友在Llama3-V的Hugging Face页面质疑抄袭时,其作者回应称只是使用了其分词器,并且项目开始时间比MiniCPM-Llama3-V 2.5更早。
当网友进一步询问如何在MiniCPM-Llama3-V 2.5发布前使用其分词器,作者给出的答案是使用了MiniCPM-V-2的分词器,但很明显,两个版本的分词器完全不同。

3、Llama3-V提供的代码无法与Hugging Face的检查点兼容。

但网友将Llama3-V模型权重中的变量名称更改为MiniCPM-Llama3-V 2.5的名称后,该模型可以与MiniCPM-V代码一起运行。
面壁智能的研发人员的调查结果也显示:更改参数名称后,可以使用MiniCPM-Llama3-V 2.5的代码和config.json运行Llama3-V。

4、Llama3-V项目的作者害怕面对质疑,删除了质疑者在Llama3-V上提交的质疑他们偷窃的问题。并且目前Llama3-V项目已经从开源网站中下架删除。

5、在一些未公开的实验性特征上,比如在内部私有数据上训练的古汉字清华竹简,Llama3-V表现出与MiniCPM-Llama3-V 2.5高度相似的推理结果。这些训练图像是最近从出土文物中扫描并由面壁智能的团队注释的,尚未公开发布。
例如下图中的几个古汉字识别:

MiniCPM-Llama3-V 2.5中未公开的WebAgent功能上,在框选内容大小时,Llama3-V与之犯了相同的错误:

二、仨作者内讧,Aljadery全权负责写代码,但拿不出训练代码
昨天,Aksh Garg、Siddharth Sharma在外媒Medium上公开回应:“非常感谢在评论中指出(Llama3-V)与之前研究相似之处的人。我们意识到我们的架构与OpenBMB的‘MiniCPM-Llama3-V2.5:手机上的GPT-4V级多模态大模型’非常相似,他们在实现方面领先于我们。为了尊重作者,我们删除了原始模型。”Aljadery没有出现在声明中。

▲Aksh Garg、Siddharth Sharma的回应声明
Mustafa曾在南加州大学从事深度学习研究,并在麻省理工学院从事并行计算研究,拥有南加州大学计算机科学学士学位和计算神经科学理学士学位,目前其没有在公司任职。
Garg在社交平台X中发布的致歉声明中提到,Mustafa全权负责编写Llama3-V的代码,他与Sharma因忙于全职工作并未参与代码编写。
在听取了Mustafa描述的Idefics、SigLip等架构扩展创新、查看了最新论文后,他们二人就在未被告知该项目与开源代码关系的情况下,帮助Mustafa在外媒Medium和社交平台X对Llama3-V进行了宣传推广。
在昨天看到关于Llama3-V的抄袭指控后,Garg和Sharma就与Mustafa进行了原创性讨论,并要求他提供训练代码,但目前未收到任何相关证据。

目前,Aljadery的Twitter账号显示“只有获得批准的关注者才能看到”。

三、首个基于Llama-3构建的多模态大模型
此前,Garg在介绍Llama3-V的文章中提到,Llama3-V是首个基于Llama-3构建的多模态大模型,训练费用不到500美元。并且与多模态大模型Llava相比,Llama3-V性能提升了10-20%。
除了MMMU之外,Llama3-V在所有指标上的表现都与大小为其100倍的闭源模型非常相近。

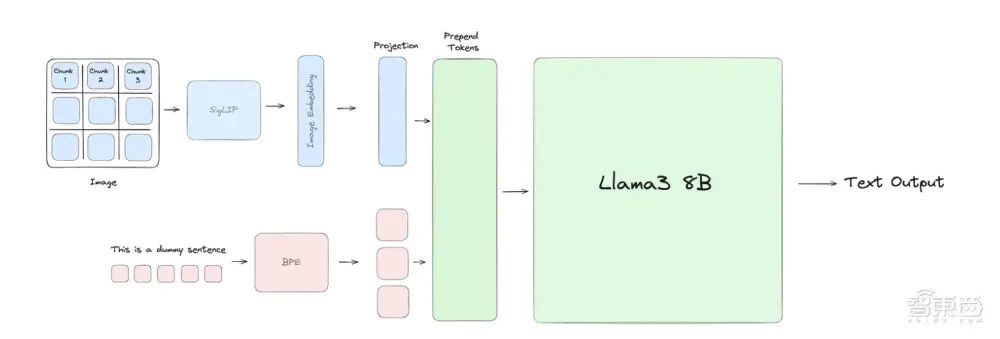
他们所做的就是让Llama 3能理解视觉信息。Llama3-V采用SigLIP模型获取输入图像并将其嵌入到一系列块嵌入中。然后,这些嵌入通过投影块与文本标记对齐,投影块应用两个自注意力块将文本和视觉嵌入放在同一平面上。最后,投影块中的视觉标记就被添加到文本标记前面,并将联合表示传递给Llama 3。
结语:Llama3-V套壳实锤,或损害开源社区健康发展
不论从网友的质疑还是Llama3-V作者的回应来看,该模型套壳MiniCPM-Llama3-V2.5已经基本实锤,高度相似的代码以及部分基于面壁智能内部未公开训练数据训练的功能,都证明这两大模型的相似性。
目前来看,对于大模型“套壳”没有明确的界定,但开源大模型以及开源社区的构建本意是促进技术的共享和交流,加速AI的发展,但如果以这种直接“套壳”、更改变量的形式使用,或许会与这一发展愿景背道而驰,损害开源社区的健康发展。