随着GenAI产品开发和研究变得越来越广泛,训练数据的抓取许可也越来越成为受关注的话题。最近,吴恩达在网站The Batch上提及了一篇有关数据许可的研究,其结果似乎让本就迫近的“AI数据荒”雪上加霜。
研究人员发现,C4、RefineWeb、Dolma等开源数据集所爬取的各种网站正在快速在收紧他们的许可协议,曾经触手可及的开放数据越来越难以获取。
这不仅会影响商用AI模型的训练,也会对学术界和非营利机构的研究造成阻碍。
该项目的4位团队主管分别来自MIT Media Lab、Wellesley学院、AI初创公司Raive等机构。

论文地址:https://www.dataprovenance.org/consent-in-crisis-paper
主持该研究的是非营利组织The Data Provenance Initiative,由来自世界各地的AI研究人员志愿加入组成。论文所涉及的数据标注以及分析全过程已经全部公开在GitHub上,方便未来研究参考使用。

仓库地址:https://github.com/Data-Provenance-Initiative/Data-Provenance-Collection
具体来说,论文主要有以下几个方面的结论:
对AI数据共享空间的限制正在激增
2023.4~2024.4仅一年的时间,C4、RefineWeb、Dolma数据集中就有5%+的token总量、25%+的关键网页在robots.txt做出了限制。
从服务条款的结果来看,C4数据集的45%已被限制。通过这种趋势可以预测,不受限制的开放网络数据将会逐年减少。
许可的不对称性与不一致性
相比其他的开发者,OpenAI的爬虫更加不受欢迎。不一致性体现在,robots.txt和服务条款(Terms of Service, ToS)中经常存在矛盾之处。这表明用于传达数据使用意图的工具存在效率低下的问题。
从网络爬取的公开训练语料中,头尾内容的特征存在差异
这些语料中有相当高比例的用户生成内容、多模态内容和商业变现内容(俗称带货广告),敏感或露骨内容的比例仅仅略少一些。
排名靠前的网站域名包括新闻、百科和社交媒体网站,其余的组织机构官网、博客和电子商务网站构成了长尾部分。
网络数据与对话式AI的常见用例的不匹配
网络上爬取的相当一部分数据与AI模型的训练用途并不一致,这对模型对齐、未来的数据收集实践以及版权都会造成影响。
研究方法
通常来说,限制网页爬虫的措施有以下两种:
- 机器人排除协议(Robots Exclusion Protocol, REP)
- 网站的服务条款(Terms of Service, ToS)
REP的诞生还要追溯到AI时代之前的1995年,这个协议要求在网站源文件中包含robots.txt以管理网络爬虫等机器人的活动,比如用户代理(user agent)或具体文件的访问权限。

Google开发者网站上的robots.txt文件示例
你可以将robots.txt的效力视为张贴在健身房、酒吧或社区中心墙上的“行为准则”标志。它本身没有任何强制效力,好的机器人会遵循准则,但坏的机器人可以直接无视。
论文共调查了3个数据集的网站来源,具体如表1所示。这些都是有广泛影响力的开源数据集,下载量在100k~1M+不等。

每个数据来源,token总量排名前2k的网站域名,取并集,共整理出3.95k个网站域名,记为HEADAll,其中仅来源于C4数据集的记为HEADC4,可以看作是体量最大、维护最频繁、最关键领域的AI训练数据来源。
随机采样10k个域名(RANDOM10k),其中再随机选取2k个进行人工标注(RANDOM2k)。RANDOM10k仅从三个数据集的域名交集中采样,这意味着他们更可能是质量较高的网页。
如表2所示,对RANDOM2k进行人工标注时涵盖了许多方面,包括内容的各种属性以及访问权限。为了进行时间上的纵向比对,作者参考了Wayback Machine收录的网页历史数据。
研究所用的人工标注内容都已公开,方便未来研究进行复现。

结果概述
数据限制增加
除了收集历史数据,论文还使用SARIMA方法(Seasonal Autoregressive Integrated Moving Average)对未来趋势进行了预测。
从robots.txt的限制来看,从GPTBot出现(2023年中期)后,进行完全限制的网站数量激增,但服务条款的限制数量增长较为稳定且均衡,更多关注商业用途。


根据SARIMA模型的预测,无论是robots.txt还是ToS,这种限制数增长的趋势都会持续下去。
下面这种图计算了网站限制的特定组织或公司的agent比例,可以看到OpenAI的机器人遥遥领先,其次是Anthropic、Google以及开源数据集Common Crawl的爬虫。

从token数量的角度,也能看到类似的趋势。

不一致且无效的AI许可
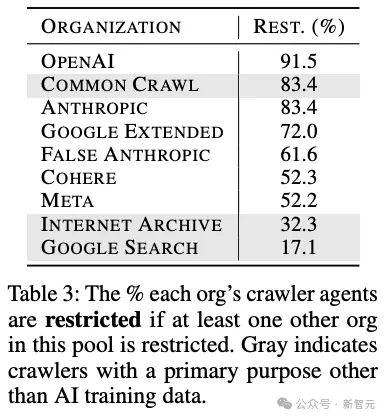
不同组织的AI agent的在各网站上的许可程度存在相当大的差异。
OpenAI、Anthropic和Common Crawl的受限占比位列前三,都达到了80%以上,而网站所有者对Internet Archive或Google搜索这类非AI领域的爬虫通常都比较宽容开放。
robots.txt主要用于规范网页爬虫的行为,而网站的服务条款是和使用者之间的法律协议,前者较为机械化、结构化但可执行度高,后者能表达更丰富、细微的策略。
二者本应相互补足,但在实际中,robots.txt常常无法捕捉到服务条款的意图,甚至常常有互相矛盾的含义(图3)。

现实用例与网页数据的不匹配
论文将网页内容与WildChat数据集中的问题分布进行对比,这是最近收集的ChatGPT的用户数据,包含约1M份对话。

从图4中可以发现,二者的差别十分显著。网页数据中占比最大的新闻和百科在用户数据中几乎微不足道,用户经常使用的虚构写作功能在网页中也很难找到。
讨论与结论
近来,很多AI公司都被指责绕过robots.txt来抓取网页数据。尽管很难确认,但似乎AI系统很难将用于训练的数据和推理阶段用于回答用户提问的数据分开。
REP协议的复杂性给网页创建者带来了很大的压力,因为他们很难对所有可能的agent及其下游用例做出细致规定,这导致robots.txt的实际内容很难反映真实意图。
我们需要将用例相关的术语进一步分类并标准化,比如,用于搜索引擎,或非商用AI,或只在AI标明数据出处时才可使用。
总之,这种新的协议需要更灵活地反映网站所有者的意愿,能将有许可和不被允许的用例分开,更好地与服务条款同步。
最为重要的是,从网站数据使用限制的激增中,我们不难看出数据创建者和AI科技公司之间的紧张关系,但背后无辜躺枪的是非营利组织和学术研究人员。
The Batch在转述这篇文章时表达了这样的愿望:
“我们希望AI开发人员能够使用开放网络上提供的数据进行训练。我们希望未来的法院判决和立法能够确认这一点。”