警告!不要在ChatGPT里问最新o1模型是怎么思考的——只要尝试几次,OpenAI就会发邮件威胁撤销你的使用资格。请停止此活动,确保您使用ChatGPT时符合我们的使用条款。违反此条款的行为可能导致失去OpenAI o1访问权限。

大模型新范式o1横空出世不到24小时,就已经有不少用户反馈收到这封警告邮件,引起众人不满。
有人反馈只要提示词里带“reasoning trace”、“show your chain of thought”等关键词就会收到警告。

甚至完全避免出现关键词,使用其他手段诱导模型绕过限制都会被检测到。

也有人声称自己真的被封号了,为期一周。

这些用户都在试图套话o1,让他复述出完整的内部思维过程,也就是全部原始reasoning tokens。
目前,大家在ChatGPT界面通过展开按钮能看到的,只是一份对原始思维过程的摘要。

实际上,在o1发布时OpenAI就给出了隐藏模型完整思维过程的理由。
总结一下:OpenAI内部需要监测模型的思维过程,因此不能在这些原始tokens中加入安全限制,也就不方便让用户看到。

不过这个理由并不是所有人都认可。
有人指出,o1思维过程就是其他模型最好的训练数据,所以OpenAI不想这些宝贵数据被别的公司扒走。

也有人认为这说明o1真的没有什么护城河,一旦思维过程暴露就很容易被别人复制。

以及“这是让我们只需盲目相信AI的答案,不用做出任何解释吗?”

对于o1模型背后的技术原理,这次透露的相当少,有效信息几乎只有“用了强化学习”。
总之,OpenAI是越来越不Open了。

o1就是草莓,但并非GPT-5
目前可以确定o1就是OpenAI炒作很久了的“草莓”,或者说是用了“草莓”所代表的方法。

但他可以算作下一代模型GPT-5么,还是只是GPT-4.X?
越来越多的人开始怀疑,它只是基于GPT-4o做的工程调整。
知名爆料账号Flowers(原Flowers from the future)称,OpenAI员工内部把o1称做“带推理的4o”。

并且他声称很多OpenAI员工默默点赞了这条爆料,上面的截图也正是来自OpenAI员工。
但马斯克前一阵把Twitter改版成除了楼主以外其他人无法看到谁点赞了什么,所以目前还无法证实这条消息。

在OpenAI开发者账号刚刚举办的“有问必答”(Ask Me Anything)活动中,Flowers也做了追问。

OpenAI员工在这里回答了很多问题,但回避了这个点赞很多排在前面的问题。

甚至奥特曼本曼刚刚又出来当谜语人,暗示“草莓”已经告一段落,下一款代号“猎户座”Orion的新模型还在路上。
此前有消息称“猎户座”是OpenAI的下一代新旗舰模型,由“草莓”也就是o1生成的合成数据训练。
而猎户座正是奥特曼口中“冬季星座”的代表之一。

说回到已发布的o1,围绕它的另一种批评声音是“不符合科研规范”。
例如没有引用之前推理时间计算的相关工作,同时也缺乏与其他公司最先进模型的比较。
针对前一点,有人指出OpenAI已经不再是一个研究实验室,应该被视为一家商业公司了。
有时他们仍会假装自己是个研究实验室,目的是招募想要做研究工作的人才。
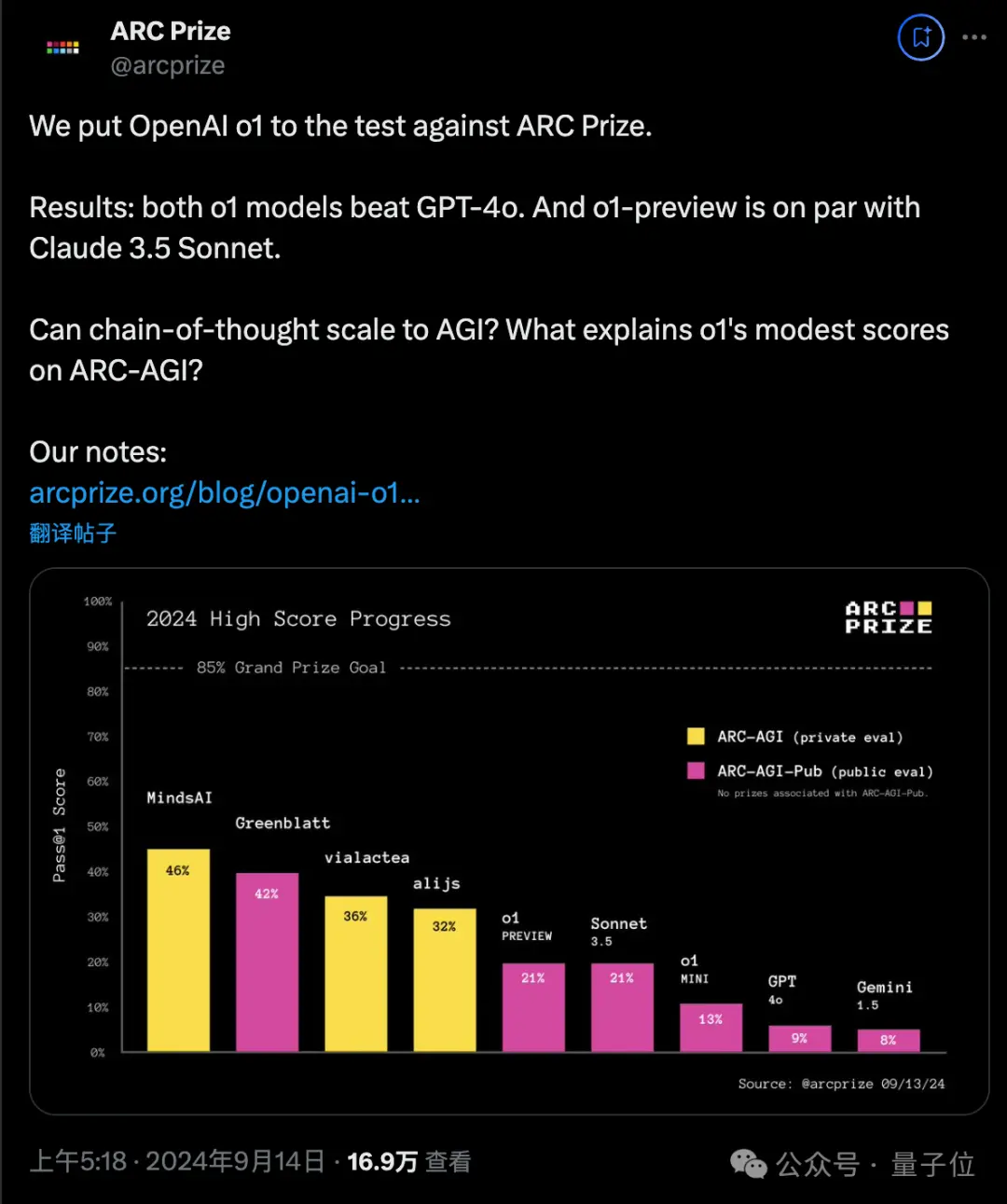
不过针对后一点,既然API发布了,要不要与其他前沿模型比较就由不得你了,很多第三方Benchmark已陆续跑出结果。
在Keras之父举办的100万美金AGI Prize比赛中,o1-preview和o1-mini两个版本在公开测试集上都超过了自家GPT-4o。
但o1-preview与隔壁Claude 3.5-Sonnet只是打了个平手。
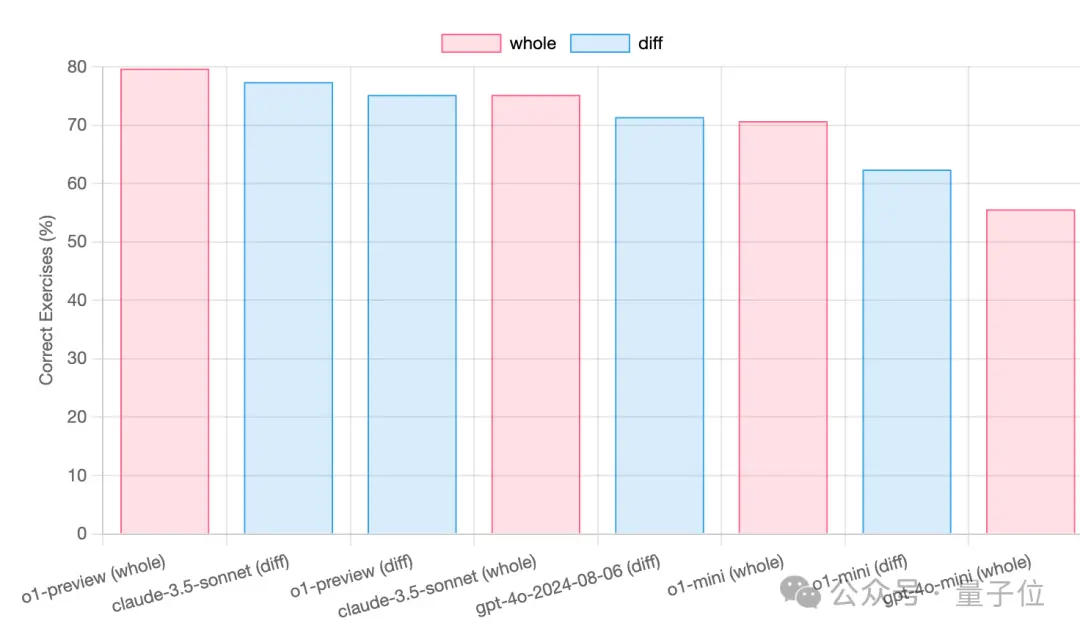
在o1着重宣传的代码能力上,开源结对编程工具aider团队运行了测试,o1系列也没有取得明显优势。
对于整个代码重写任务,o1-preiview取得79.7分,Claude-3.5-Sonnet取得75.2分,o1领先4.5分。
但对于更实用的代码编辑任务,o1-preview反而落后于Claude-3.5-Sonnet,有2.2分的差距。
另外aider团队提示,如果目前想用o1系列替代Claude编程,成本上要高很多。
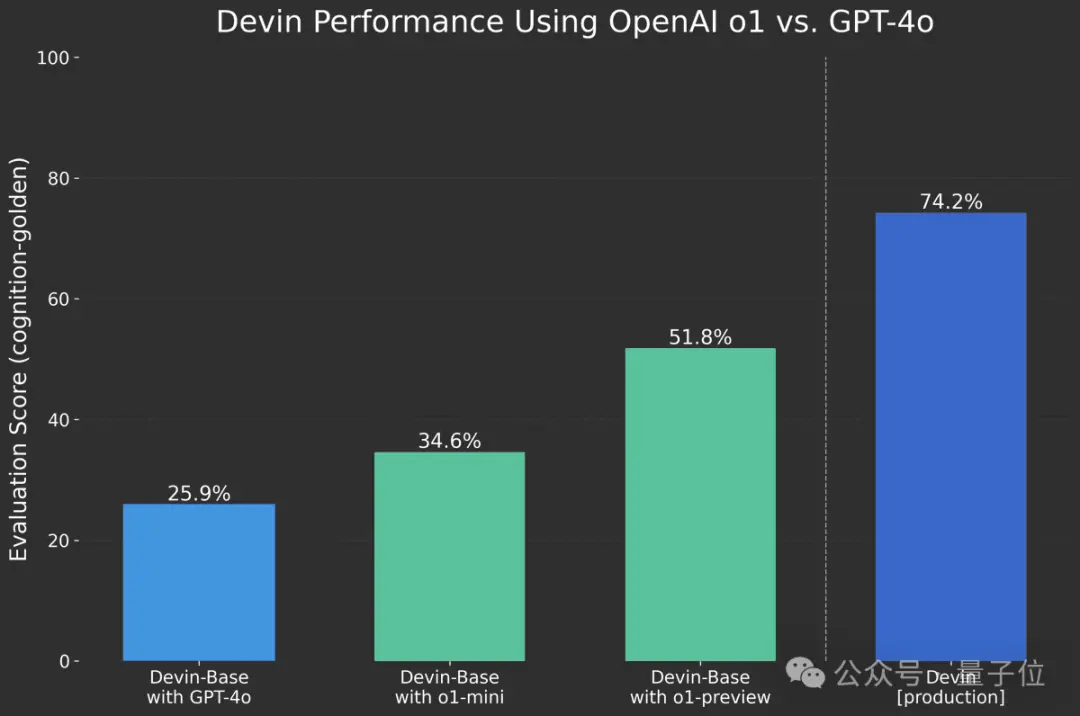
与OpenAI有合作关系的“AI程序员”Devin团队,已经提前拿到了o1访问资格。
在他们的测试中,由o1系列驱动Devin基础版本,与GPT-4o相比获得非常大的提升。
不过相比已发布的Devin生产版本还是有较大差距,主要是由于Devin生产版本在专有数据上进行了训练。
另外根基Devin团队分享,o1在得出正确的解决方案之前通常会回溯并考虑不同的选项,并且不太可能出现幻觉或自信地错误。
使用o1-preview时,Devin更有可能正确诊断bug的根本原因,而不是解决问题的症状。
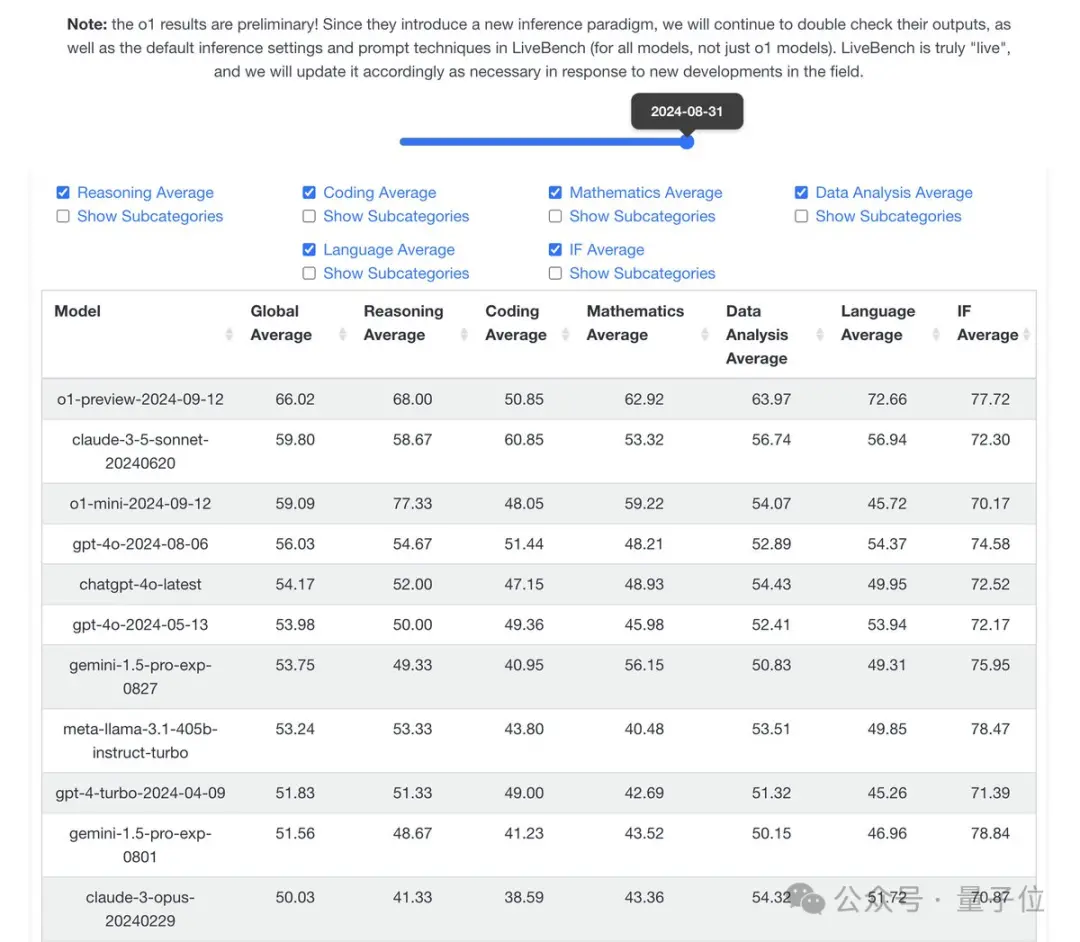
在更重视数学和逻辑推理的Livebench榜单中,o1-preview在代码单项落后的情况下,总分上超过Claude-3.5-Sonnet并拉开明显差距。
Livebench团队分享这还只是初步结果,因为很多测试中还内置了“请一步一步地思考”等提示词技巧,这并不是使用o1的最佳方法。
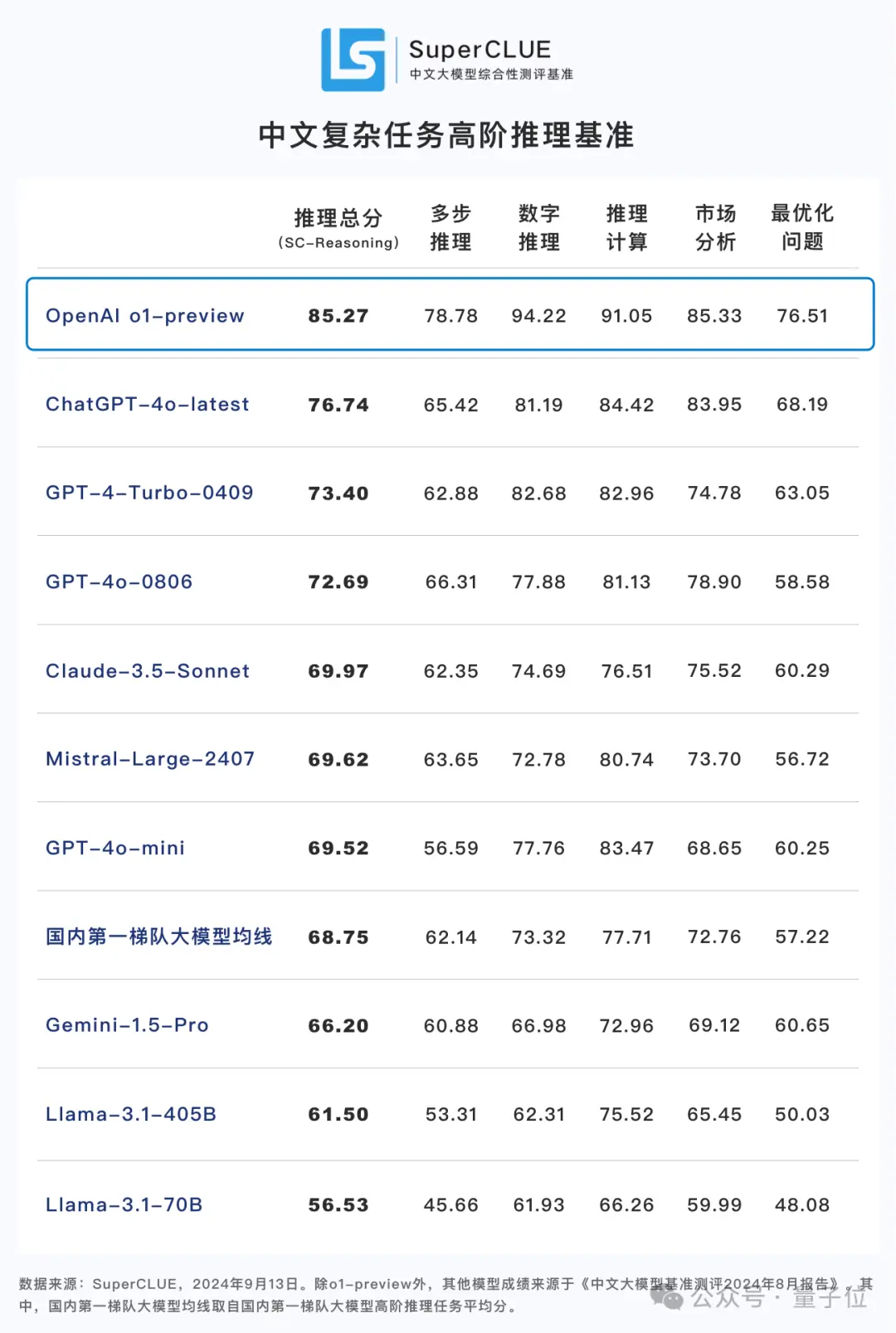
在中文大模型综合测评基准SuperCLUE的中文复杂任务高阶推理测试中,o1-preview的推理能力也大幅领先。
最后总结一下,使用o1模型还需要注意的一些地方:
成本非常高,1百万输出tokens就要60美元,价格一夜回到GPT-3时代
隐藏的resoning tokens也是算在输出tokens中,看不到,但是要付费
大多数任务最好先使用GPT-4o,发现不够用了再切换o1,以节省成本。
代码任务仍然优先使用Claude-3.5-Sonnet
总之围绕OpenAI新模型o1,开发者社区还有很多疑问。
o1开启了AI高阶推理的新范式,但它本身还不算完善,如何发挥他的最大价值还有待探索。
在此背景下,OpenAI举办的“有问必答”活动,在4个小时内就收到上百条提问。
下面附上对整场活动内容的精选和总结。
OpenAI员工“有问必答”
首先对于这个突然发布的新模型,很多人好奇为什么OpenAI给它取了o1这样一个名字?
这是因为在OpenAI看了,o1代表了AI能力的一个新的层级,因此对“计数器”进行了重置,而o则代表OpenAI。
就像o1发布时奥特曼说的,可以进行复杂推理的o1,是一个新范式的开始。
对于其中preview和mini两个版本号,OpenAI科学家也确认了网友的一些猜测——
preview是一个临时版本,正式版将在未来上线(实际上preview版本是o1的一个早期checkpoint);而mini版不保证近期之内会有更新。
配合OpenAI成员Kevin Lu之前发布的这张图来看,就更加清晰明了了。
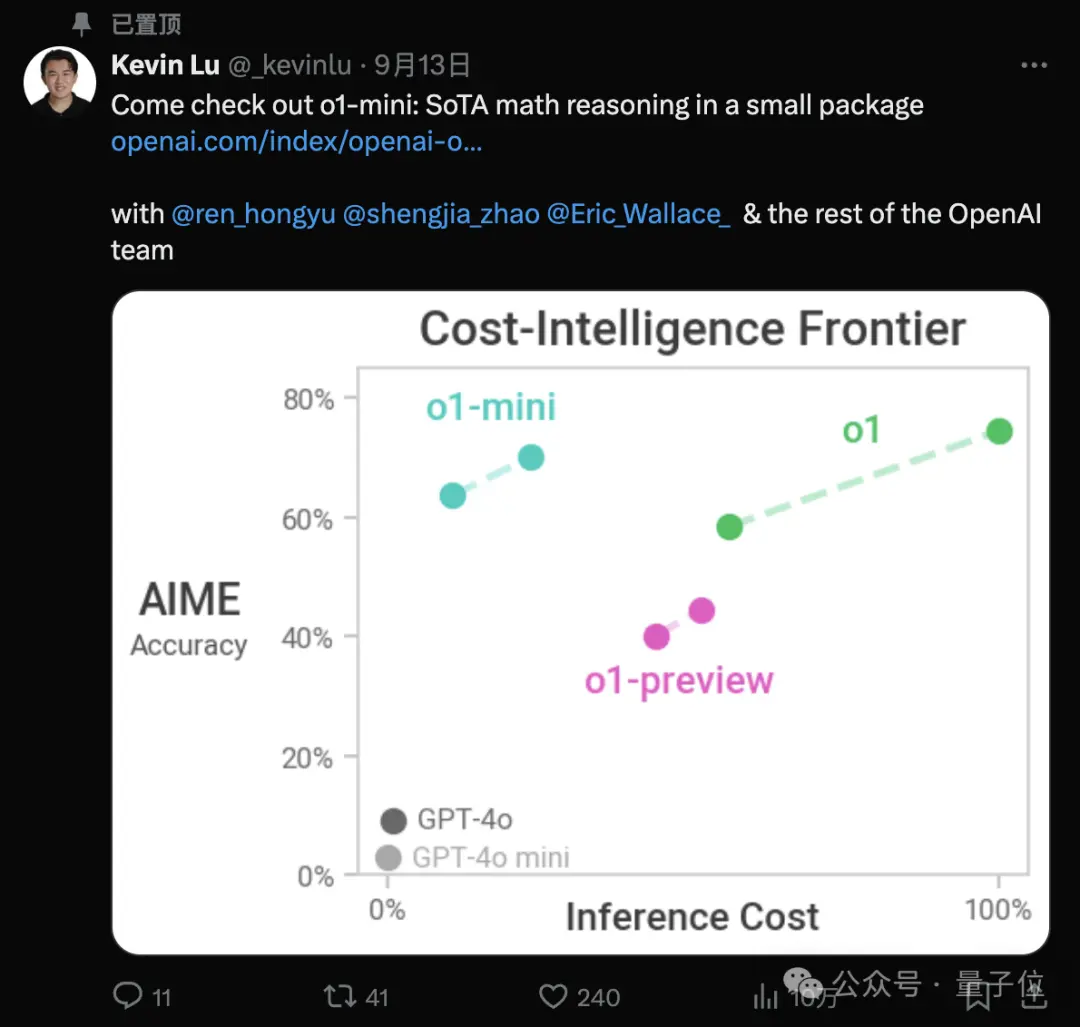
与preview相比,mini在某些任务上表现出色,尤其是与代码相关的任务,还可以探索更多的思维链,但世界知识相对少些。
对此,OpenAI科学家赵盛佳的解释是,mini是一个高度专门化的模型,只关注少部分的能力,所以可以更深入。
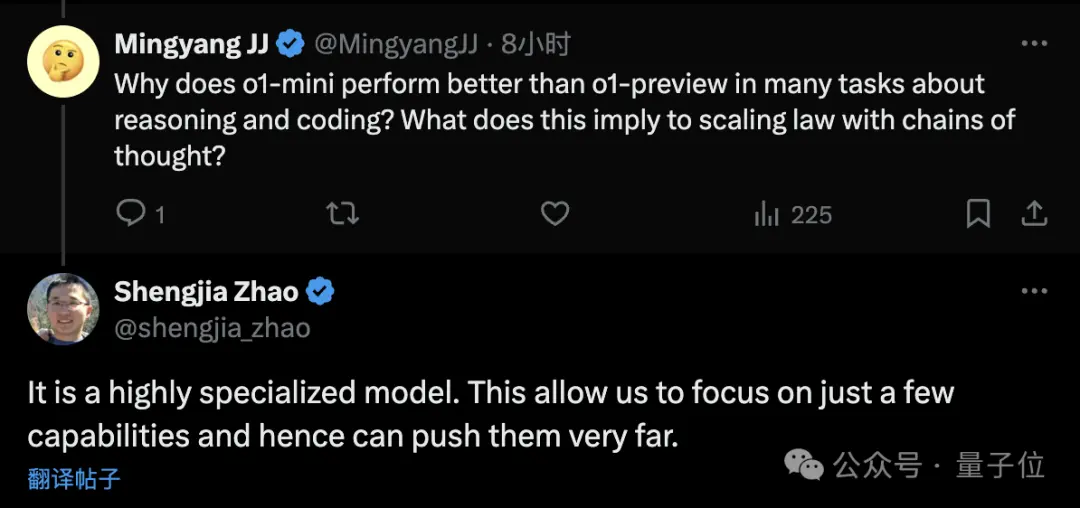
也算是揭晓了之前奥特曼在这个问题上打的一个哑谜。
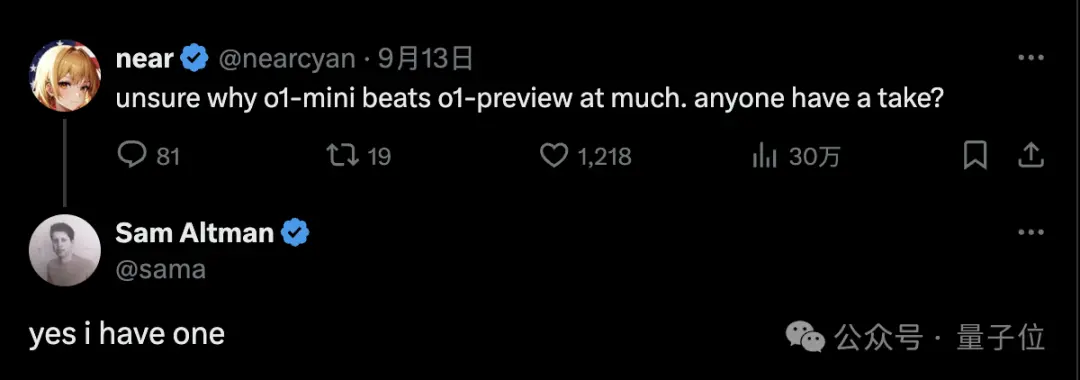
关于o1的运作方式,OpenAI科学家Noam Brown也明确表示,并非是像部分网友认为的模型+CoT组成的“系统”,而是一个已经被训练得原生具备生成思维链能力的模型。
不过推理过程中的思维链会被隐藏,并且官方已经明确了没有向用户展示有关token的计划。
对此OpenAI透露的为数不多的消息是,CoT的相关token是总结性的,且不保证完全和推理过程匹配。
除了推理模式,在这次问答活动中还能够得知,o1与GPT-4o相比可以处理更长的文本,而且未来还会继续增加。
表现上,在OpenAI内部的测试中,o1显现出了哲学推理能力, 可以思考诸如“生命是什么?”之类的哲学问题。
研究人员还使用o1创建了一个GitHub机器人,能够将代码ping给所有者以供审核。
当然对于一些非推理性质的任务,比如创意写作,o1的表现相比GPT-4o提升并不明显,甚至有时还要略逊一筹。
另外综合一些提问来看,对于网友们关心的一些未上线功能,OpenAI表示正在或有计划研究,但没有明确的上线时间:
暂不支持工具调用,但函数调用、代码解释器都在未来计划之中
未来API更新将加入结构化输出、系统提示词、提示词缓存功能
微调也已在计划中
API用户将可以自行设定对推理时间和token消耗的限制
o1具有多模态能力,瞄准的是MMMU等数据集上的SOTA,之后将实装
性能上,OpenAI也正在着手降低延迟和推理所需时间。
最后是人们,尤其是API用户关心的价格问题,毕竟考虑到将推理过程计入输出token,o1的定价还是比较高的。
OpenAI表示“将遵循每1-2年降价的趋势”,并且在使用量限制变得更宽松时,批量API定价也会上线。
网页/APP端的Plus用户,目前则是要受到每周preview30条+mini50条消息的限制。

不过好消息是,就在今天凌晨,由于人们对o1实在太热情,导致很多人很快就把额度用完,所以OpenAI特例把额度重置了一次。