美东时间10月1日周二,OpenAI举行了年度开发者大会DevDay,今年的大会并没有任何重大的产品发布,相比去年大会显得更低调,但OpenAI也为开发者派发了几个大“礼包”,对现有的人工智能(AI)工具和API套件做了改进。
本次OpenAI DevDay推出一系列新工具,主要包括四大创新:提示词缓存(Prompt Caching)、视觉微调(Vision Fine-Tuning)、实时API(Realtime API)、模型蒸馏(Model Distillation),在降低模型成本、提高模型视觉理解水平、提升语音AI功能和小模型性能方面,给开发者带来福音。
有评论称,今年DevDay的重点是提高开发者的能力和展示开发者圈子的故事,这表明随着AI领域的竞争日益激烈,OpenAI的战略发生了转变。上述新工具突出表明,OpenAI的战略重点是:增强其开发者的生态系统,而不是直接在终端用户应用领域竞争。
有媒体提到,在DevDay活动前的记者会上,OpenAI的首席产品官Kevin Weil谈及最近OpenAI首席技术官Mira Murati和首席研究官Bob McGrew离职,称他们离开不会影响公司发展,“我们不会放慢脚步”。
提示词缓存(Prompt Caching)可减少输入token成本多达50%

提示词缓存被视为本次DevDay发布的最重要更新。该功能旨在降低开发者的成本、减少延迟。
OpenAI引入的提示词缓存系统自动对模型最近处理的输入token提供50%的折扣,这可能会让经常重复使用上下文的应用程序App得到大量节省。如此大幅降低成本给企业和初创公司提供了探索新应用的重大机遇,因为这些应用以前由于费用高昂无法实现。
OpenAI 平台产品负责人 Olivier Godement称,两年前GPT-3大获成功,现在OpenAI已经将相关成本降低了将近1000倍。他举不出来其他任何一个两年内能将成本降低同样幅度的例子。
以下OpenAI的图表展示了,提示词缓存可以大幅降低应用AI模型的成本,相比各种GDP模型的非缓存token,缓存输入token的成本可以减少多达50%。
视觉微调(Vision Fine-Tuning):视觉AI新前沿
OpenAI DevDay公布,OpenAI最新的大语言模型(LLM) GPT-4o 引入了视觉微调。此功能让开发者能用图像和文本自定义模型的视觉理解功能。
这是被称为视觉AI新前沿的重大更新。它可能会对自动驾驶汽车、医学成像和视觉搜索功能等领域产生深远影响。
OpenAI 称,东南亚版“美团+滴滴” Grab 已经利用这项技术改进其地图服务。仅使用 100 个示例,Grab 就让车道计数的准确率提高了20%,限速标志定位率提高13%。
这种现实世界的App展示了视觉微调的可能性,即使用小批量的视觉训练数据,显著增强各行各业的AI服务。
实时 API(Realtime API)弥补对话式 AI 的差距

OpenAI DevDay发布了实时 API,目前处于公开测试beta阶段。实时API 本质上简化了构建语音助手和其他对话式 AI 工具的过程,无需将多个模型拼接在一起进行转录、推理和文本到语音的转换。
这项新产品让开发人员能创建低延迟的多模态体验,尤其是在语音转语音App中。这意味着开发人员可以开始将 ChatGPT 的语音控件添加到App中。
为了说明该 API 的潜力,OpenAI 展示了 Wanderlust 的更新版本,它是一款在去年大会上展示过的旅行规划App。
借助实时 API,用户可以直接与新版App对话,进行自然对话来规划行程。该系统甚至允许用户在语句中间打断,模仿人类之间的对话。
旅行规划只是一个例子,实时 API 为各个行业的语音App开辟了广泛的可能性。无论是专攻客服、教育领域还是残障人士使用的无障碍工具,开发者现在都可以利用新的资源创造更直观、响应更快的AI驱动体验。
包括营养和健身指导App Healthify 和语言学习平台 Speak在内,一些App已经将先行一步,将实时API融合到自身产品中。
有评论称,实时API 的定价并不便宜,每分钟音频输入收费0.06 美元,每分钟音频输出收费0.24 美元,但对于希望创建基于语音App的开发人员来说,它仍然可以代表一个重要的价值主张。
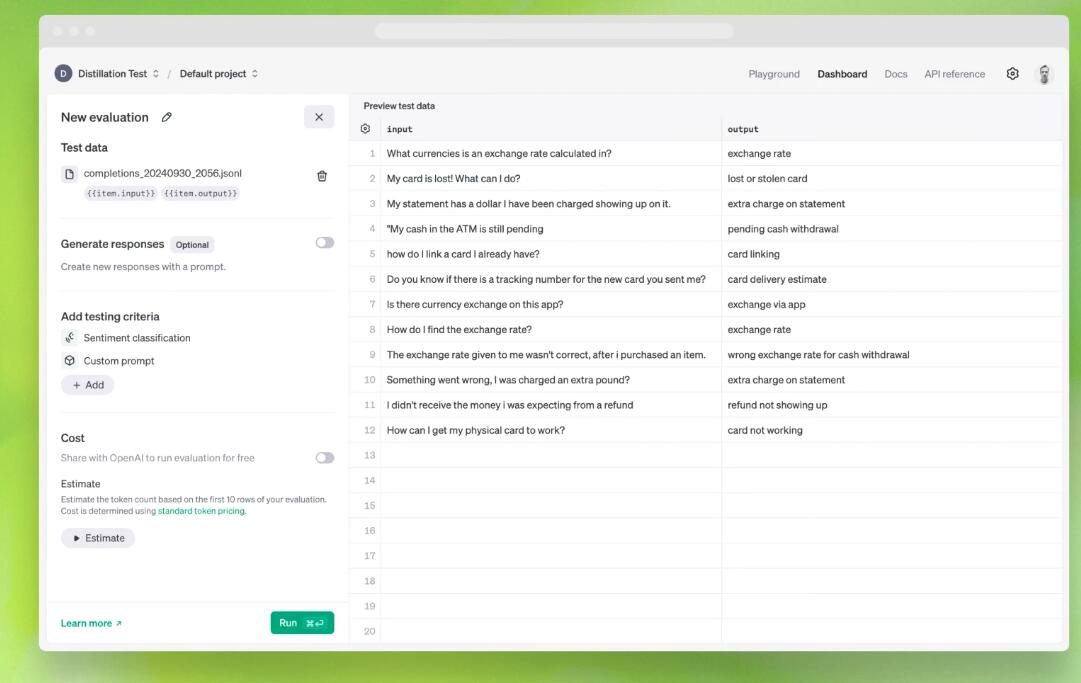
模型蒸馏(Model Distillation)让小模型也可拥有尖端模型功能

模型蒸馏被视为OpenAI此次最具变革性的新工具。这种集成的工作流程让开发人员能通过使用诸如GPT o1-preview 和 GPT-4o这类尖端模型的输出,对相对较小且经济实用的高校模型进行微调,从而提高更高效模型、如 GPT-4o mini的性能。
这种方法让小公司也可能利用与尖端模型类似的功能,并且无需承担使用这类模型的计算成本。它有助于化解 AI 行业长期以来在尖端、资源密集型系统与更易于访问但功能较弱的系统之间的鸿沟。
比如一家从事医疗技术的小型初创公司要为农村的诊所开发一种AI 驱动的诊断工具。使用模型蒸馏,该公司可以训练一个紧凑的模型,该模型可以捕捉大模型的大部分诊断能力,同时只需要在标准的笔记本电脑或平板电脑上运行。
因此,模型蒸馏可以让资源受限的环境也能享有复杂的 AI 功能,有可能提高医疗服务欠发达地区的医疗保健水平。