2024 年的最后一天,智谱 GLM 模型家族迎来了一位新成员——GLM-Zero 的初代版本 GLM-Zero-Preview,主打深度思考与推理。从年初到年末,在接连推出新一代基座大模型、多模态模型、视频生成模型以及语音模型之后,智谱补上了推理模型这块拼图。
据介绍,GLM-Zero-Preview 是 GLM 家族中专注于增强 AI 推理能力的模型,擅长处理数理逻辑、代码和需要深度推理的复杂问题。同基座模型相比,GLM-Zero-Preview 既没有显著降低通用任务能力,又大幅提升了专家任务能力。
以数学能力为例,智谱让 GLM-Zero-Preview 做了一整套 2025 年考研数学一,最后得分为 126,达到了优秀研究生水平。从下图可以看到,模型给出了详细的解题步骤。

再看下代码能力,GLM-Zero-Preview 熟练使用多种编程语言,可以帮助开发者快速编写代码,如下使用 HTML 语言独立编写了一个第一人称射击游戏。另外它还可以调试代码,快速识别错误并给出修复建议。

目前,GLM-Zero-Preview 已经上线使用。用户可以在智谱清言网页端选择“Zero 推理模型”智能体,上传文字或图片就能免费体验。另外,GLM-Zero-Preview 的 API 也在智谱开放平台同步上线以供开发者调用。

智谱清言:http://chatglm.cn/
智谱开放平台:https://bigmodel.cn/
2000万token免费体验资源包领取地址:https://zhipuaishengchan.datasink.sensorsdata.cn/t/7K
一手实测
智谱深度推理大摸底
先来看官方给出的指标。作为智谱首个基于扩展强化学习技术训练的推理模型,GLM-Zero-Preview 在多个基准上与 OpenAI o1-preview 互有胜负,其中在数学基准测试 AIME 2024、MATH500 以及代码生成基准测试 LiveCodeBench 中实现小幅超越。

在技术实现上,由于强化学习训练量的增加,GLM-Zero-Preview 的深度推理能力得到稳步提升。同时随着模型在推理阶段可以思考的 token 数变多以及计算量增加,GLM-Zero-Preview 的输出结果质量也稳步提升。
得益于以上两点,GLM-Zero-Preview 表现出了类人的思考决策过程,初步具备了“推理过程中自主决策、问题拆解、尝试多种方式解决问题”等能力。
是骡子是马,溜后才知道。GLM-Zero-Preview 在真实世界任务中的表现如何?机器之心进行了一波全方位的测试。
我们搜罗了各种类型的推理问题,看看 GLM-Zero-Preview 能不能 hold 住这些容易绕晕人的中文逻辑陷阱题,以及需要数学、物理等专业学科知识与思辨能力的题目。
比大小不会翻车、有干扰项也无妨
大模型以前经常翻车的小数点后比大小问题,GLM-Zero-Preview 轻松搞定。我们看到了该模型的深度思考链路,它的显著特点是在理解问题及解题关键的基础上,从不同的角度分析、验证并给出答案。整个过程看下来,GLM-Zero-Preview 有点“PUA”自己,生怕会出错,多次检查并肯定自己的答案无误。

对于一些设置了干扰项的推理问题,GLM-Zero-Preview 也丝毫不会受到影响,很快理清思路,排除干扰项。

不落入语言陷阱、拿捏复杂推理
中文语境下有很多陷阱,比如歧义性、语境依赖、隐含信息、文化背景等,应对起来要求推理大模型“吃透”语言特点,并能够结合上下文信息、语义知识和常识推理,明辨其中的弯弯绕。
面对这类中文陷阱题目,GLM-Zero-Preview 给出的深度思考过程显示,它从不同的视角考虑和深度推理,排除一切的不可能之后,确认最合理的解释和答案。

另外,面对复杂的中文逻辑推理问题,尤其涉及多个角色人物时,GLM-Zero-Preview 不会被搞混。通过深度思考进行情况罗列与假设分析,并辅以缜密的条件验证,整个过程像抽茧剥丝的判案一样。

GLM-Zero-Preview 给出了逻辑清晰的解题步骤。

常识推理无压力、时间感知能力强
如今的大模型在“喂”给足够多的高质量数据之后,像人一样掌握了丰富的常识,做起此类推理题来没有压力。

在时间推理中,大模型需要理解时间顺序、事件发生的时序关系,要有清晰的预测和推断能力。比如下面的时间推理场景,想必很多人都会被绕晕,而 GLM-Zero-Preview 做到了对多个角色参与的复杂时间关系的准确判断。

数学小能手上线
大模型的数学能力可以为人们在很多数学任务中提供有力支持,比如代数、微积分、概率统计。GLM-Zero-Preview 具备了更强的归纳与演绎能力,比如下面这道序列求解题,它在深度思考过程中观察规律、找出规律、验证规律。

面对经典的青蛙爬井问题,GLM-Zero-Preview 不仅给出了正确的解题思路和答案,还总结了一波经验心得。

再考它一道出自 2024 高考数学北京卷的条件判断题,显然难不倒 GLM-Zero-Preview,它通过等价代换的方式得出了正确答案。

hold 弱智吧
在面对一些弱智吧问题时,GLM-Zero-Preview 一板一眼地进行理论层面以及实际可行性的分析,并展开论证,令人忍俊不禁。

视觉推理多面手
目前,GLM-Zero-Preview 支持上传 png、jpg、jpeg、webp 等多种格式的图片,并能够应对很多类型的推理任务,比如解带有电路图的高考物理题(2024 北京卷):

以下为完整的解题步骤:

还能理解梗图:

推理模型大 PK
谁更胜一筹
接下来,机器之心让 GLM-Zero-Preview 与 o1、DeepSeek-R1-Lite 预览版、QwQ-32B-Preview 等竞品模型来了一场对决。
先考它们一道数学组合题,看看哪个模型逻辑性更强。
首先是 GLM-Zero-Preview:

然后是 o1:

接着是 DeepSeek-R1-Lite 预览版:

最后是 QwQ-32B-Preview:

比较下来,我们可以发现,o1 的推理过程最简单,缺少验证的环节。其他三个模型在给出解题思路之后都对步骤和计算进行了确认,其中 DeepSeek-R1-Lite 预览版、QwQ-32B-Preview 的验证相对简单一些,而 GLM-Zero-Preview 不仅解题过程更清晰完整,还展示了自我反思、自我怀疑、自我肯定等拟人化的思维模式。
再来第二轮较量,这次是一道中文陷阱推理题,看看哪个模型头脑更清楚。
首先是 o1 与 QwQ-32B-Preview,思考过程很短:

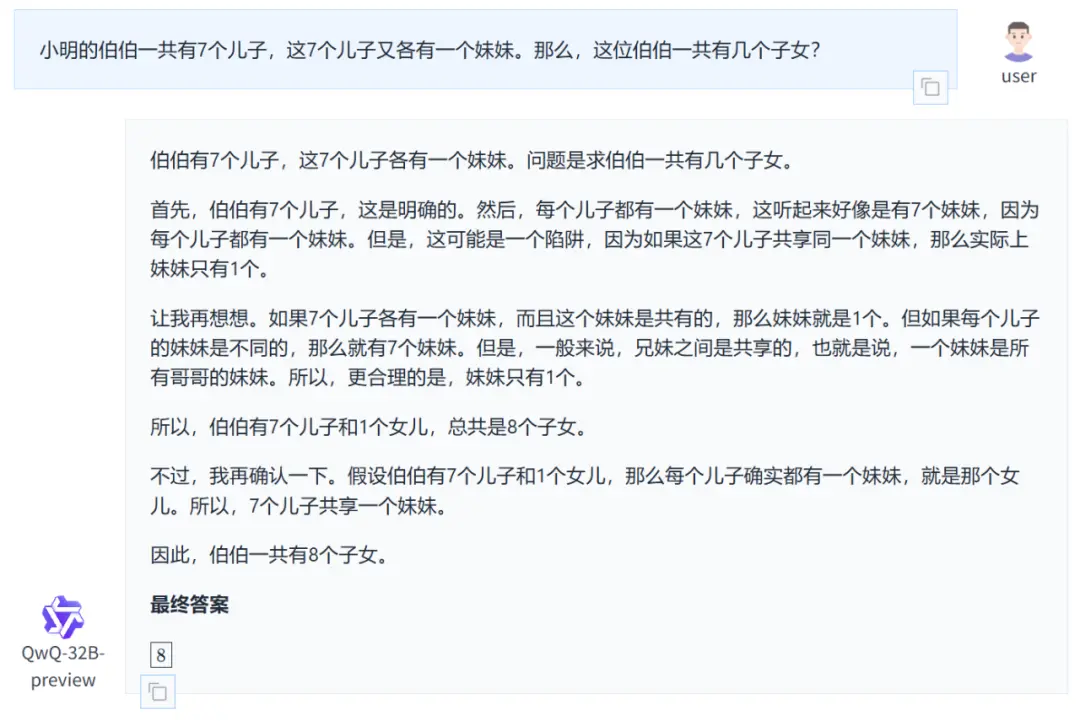
GLM-Zero-Preview、DeepSeek-R1-Lite 预览版的解释更透彻,充分考虑了条件限制与现实世界的可能性。不过,DeepSeek-R1-Lite 预览版的一些解释又略显重复,不如 GLM-Zero-Preview 明了。


思考过程与思维链路上的优势,足以让 GLM-Zero-Preview 不输其他一众推理大模型。
结语
在对 GLM-Zero-Preview 体验一番后,我们的最大感受是:它的深度思考过程让逻辑推理更加完整、连贯,准确度和说服力更强。从“审题、分析、多方式证明”到“自我怀疑、验证、再验证”到“最后确认”,环环相扣。
当然,智谱表示,目前 GLM-Zero-Preview 与 o3 还有不少的差距,未来会通过强化学习技术的持续优化迭代,让它成为更聪明的推理者。正式版 GLM-Zero 将很快推出,到时候深度思考能力会从数理逻辑扩展到更通用的技术,保证更专精的同时全能性也更强。
回看这一整年,智谱动作不断,GLM 家族更加壮大,包括基座模型、多模态模型、视频生成模型、语音模型、推理模型以及智能体方面火出圈的 AutoGLM、GLM-PC,如今这家大模型独角兽的产品矩阵在完整度层面称得上业界领先。
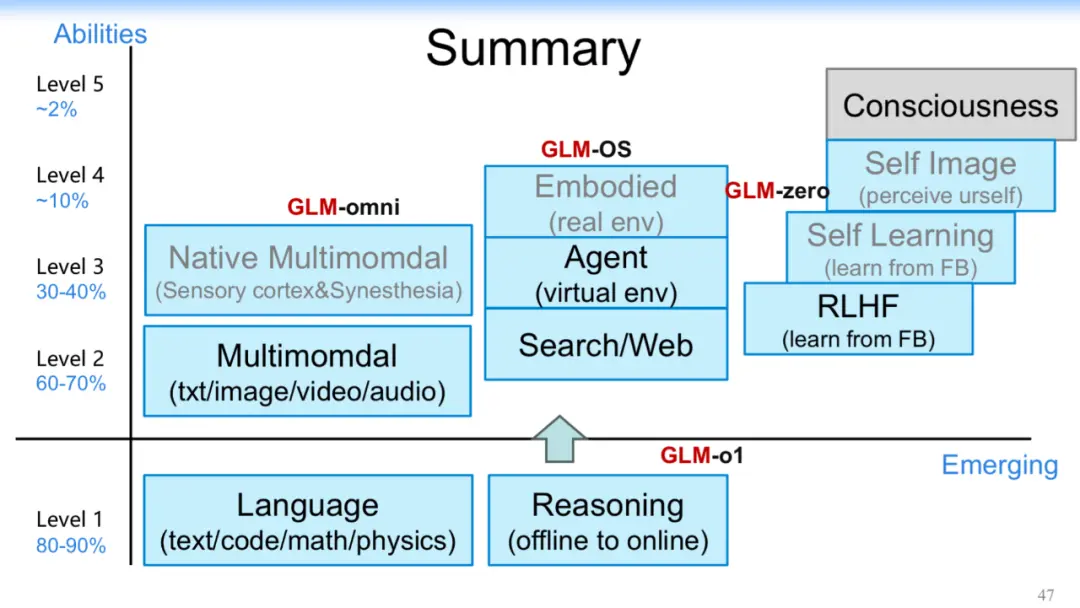
持续出新的背后是智谱对 AGI 终极目标的追求。智谱形成了一套从 L1 到 L5 阶段的 AGI 路线图,在 AI 分级上注入自己的能力进化思考。在一步步迈向 AGI 的过程中,从低到高在各个 AI 层级做能力填充,夯实语言、多模态、逻辑推理、工具使用等基础能力。GLM-Zero-Preview 代表智谱迈出了 L4 阶段的关键一步,大模型开始内省,并具备自我学习、自我反思、自我改进能力。
现在,市面上的推理大模型已经有了一些,甚至 OpenAI 发布了更强的 o3 系列模型。智谱在年末最后一天这个时间节点推出了自己的 GLM-Zero,可见对于所有以 AGI 为目标的玩家来说,2025 年模型推理能力无疑是被寄予厚望的一年。