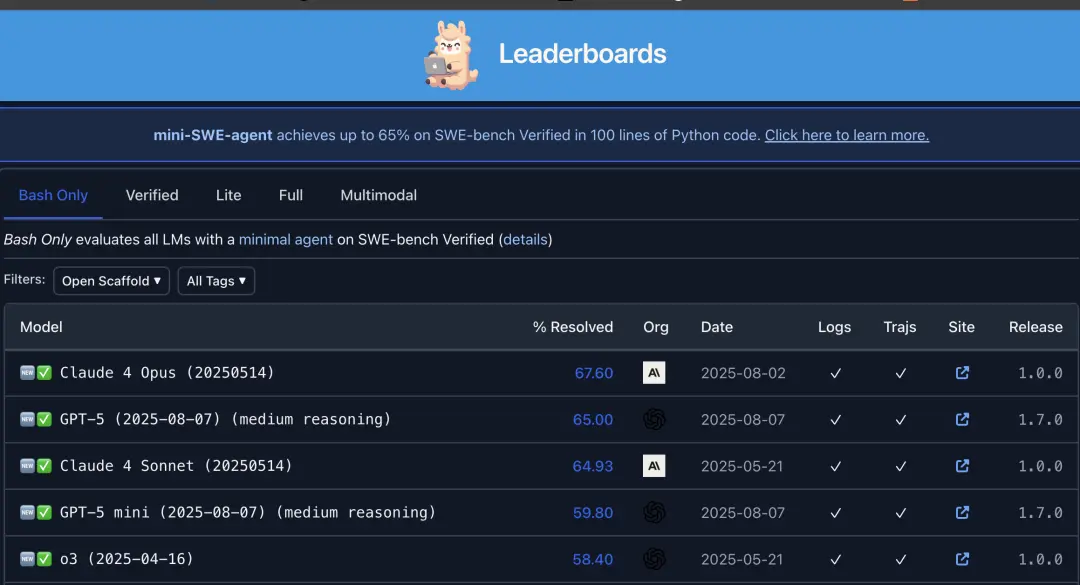
别急着用GPT-5编程了,可能它能力没有你想象中那么强。有人发现,官方测试编程能力用的SWE-bench Verified,但货不对板,只用了477个问题。什么意思呢?我们知道,SWE-bench是评估模型/智能体自主编程能力的一个通用且常用的指标。而SWE-bench Verified作为它的子集,本来一共有500个问题。
现在相当于OpenAI自行省略的那23个问题,自己搞了个子集的“子集”来评估模型能力。
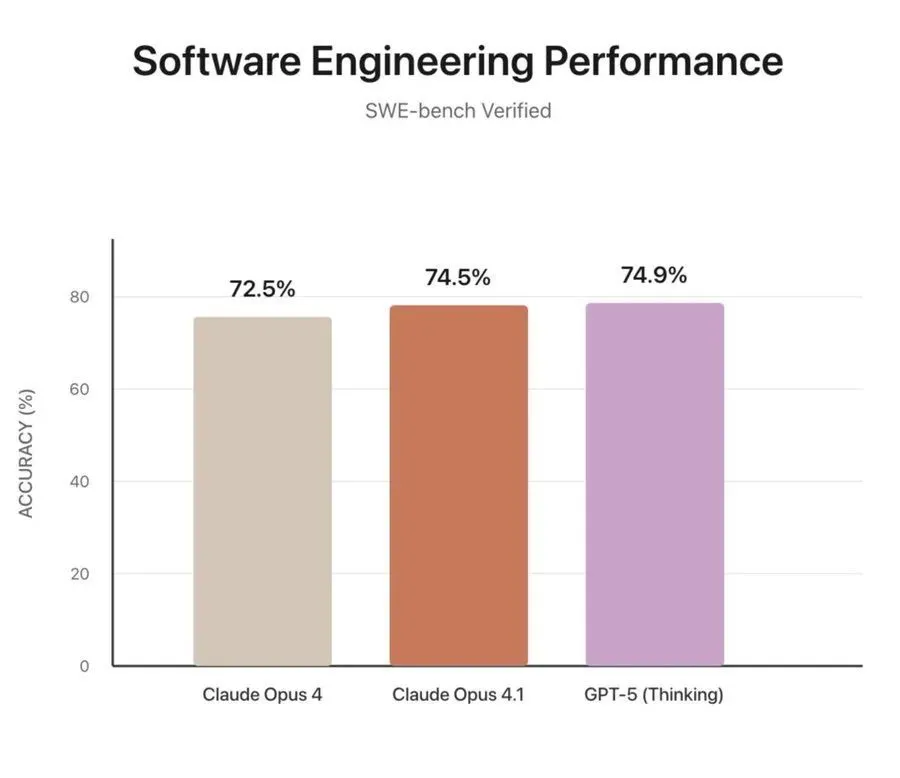
而如果这些题默认零分,那么得分实际上是比Claude Opus 4.1还要低的。因为现在仅有0.4%的差距。
OpenAI这种自行忽略23道题的操作,已经不是第一次了。
早在GPT-4.1发布时就信誓旦旦地说,之所以忽略是因为这些问题的解决方案无法在他们的基础设施运行。

离谱了朋友们!要知道SWE-bench Verified这个OpenAI自己提的,理由也是因为SWE-bench无法系统评估模型的编程能力,所以决定自己再提炼一个子集。
现在又因为测试题无法正常运行,所以自行又搞了个子集的“子集”。
本来以为GPT-5直播里出现图表错误已经够离谱了,结果现在告诉我这里面的成绩可能还有假?
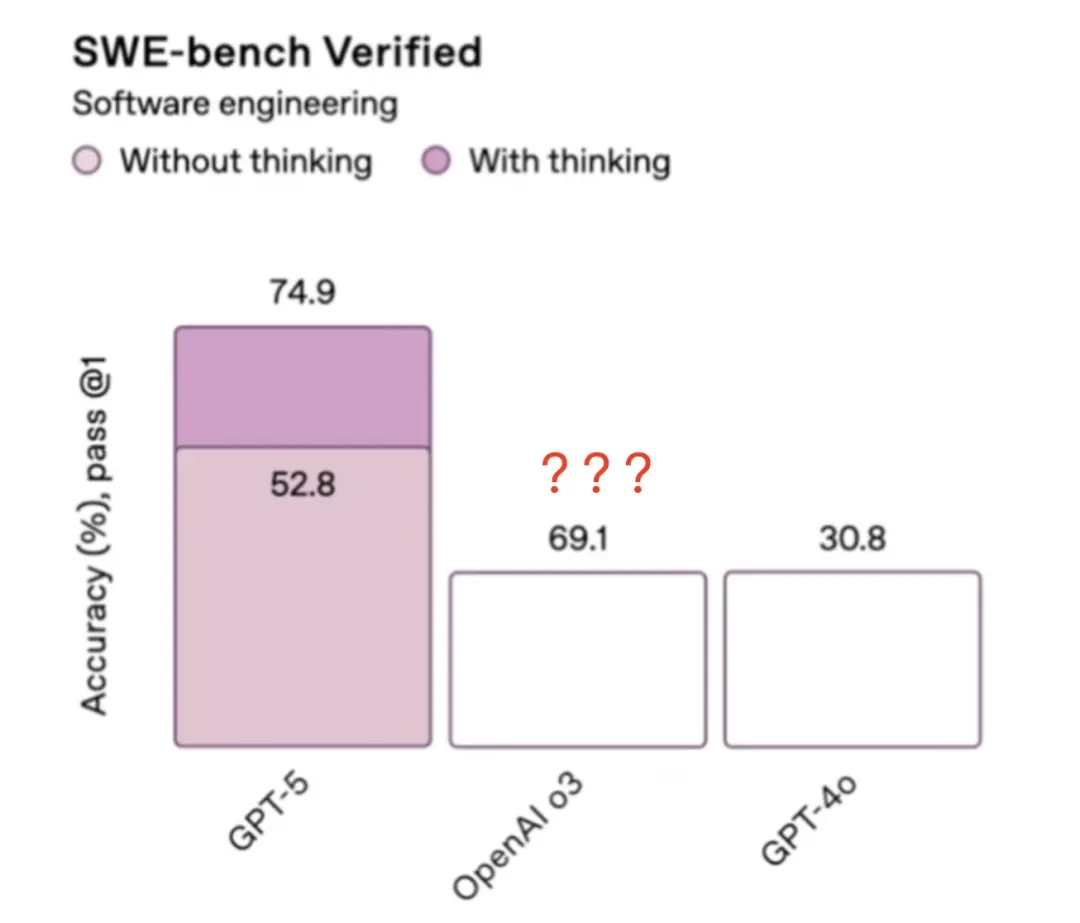
OpenAI一直省略23个问题
已经开始有网友发现,GPT-5能力并不比Claude 4.1 Opus好多少。
现在来看,这个官方给的结果或许根本没有参考价值。
网友们除了自行忽略部分测试题,“伪造了结果”这一发现外,还发现,他们是将具有最大思维努力的GPT-5与没有扩展思维仅靠原始模型输出的Opus 4.1进行比较。这种比较实际上没有参考意义。

而他们之所以只使用477个问题来测试,理由也跟GPT-4.1发布时一样,因为他们内部的基础设施运行不了剩下的23个问题。
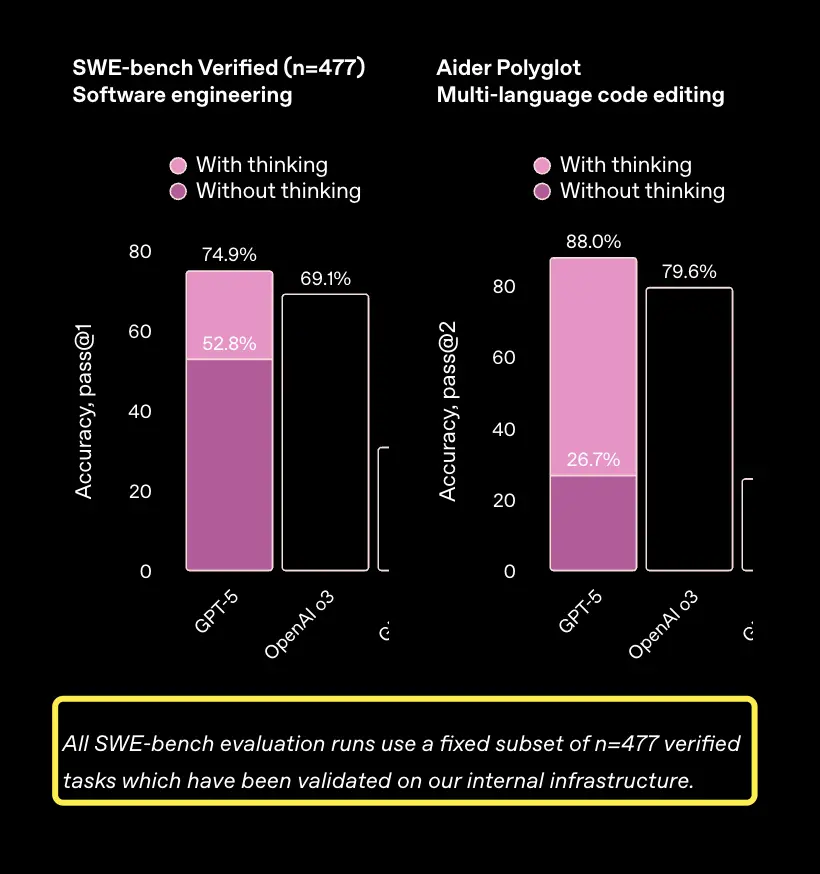
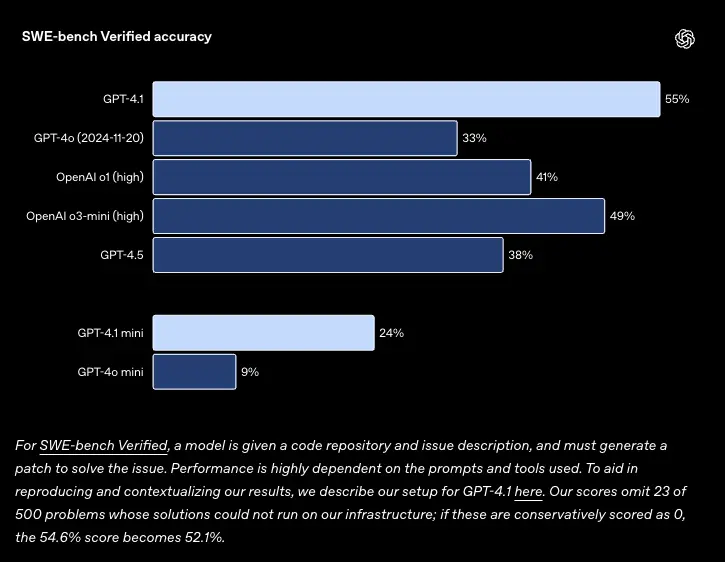
今年4月份发布GPT-4.1时,在同一基准仅使用477个问题下得得分在54.6%。
当时官方还指出,如果保守地将这些问题的得分定为 0,那么54.6%的得分就变成了52.1%。即便是这样,这个数值放在当时也是最高的。
而Anthropic这边,其实也已经发现了OpenAI这个操作。
就在Claude Opus 4.1发布公布编程成绩之时,在文章的末尾有这么一句话。
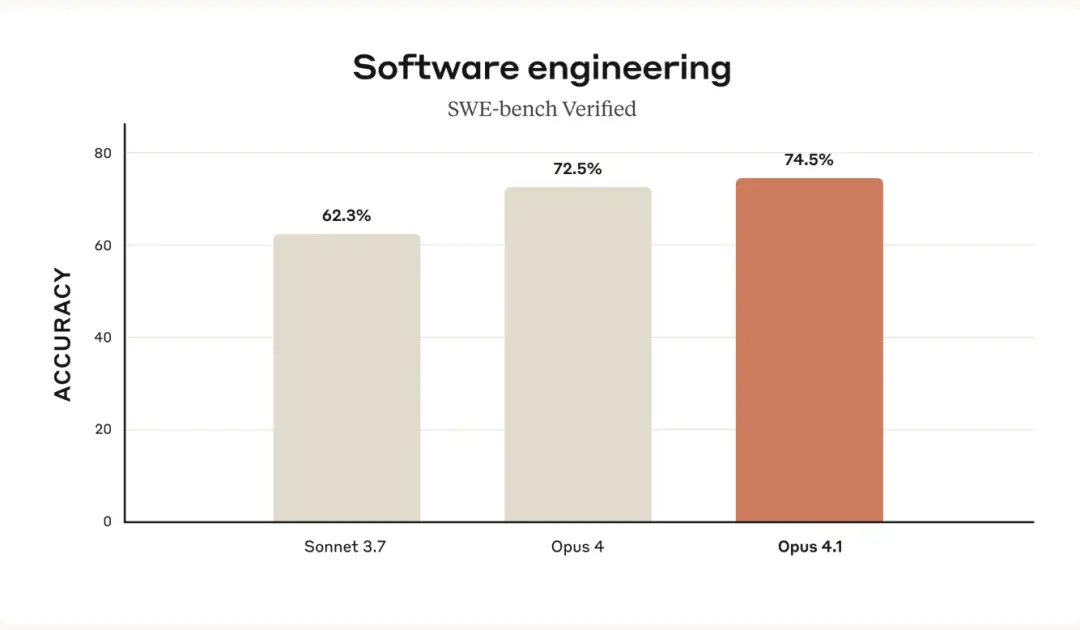
对于Claude 4系列模型,他们继续使用相同的简单框架,该框架仅为模型配备了两种工具——一个Bash工具和一个通过字符串替换进行文件编辑的工具,并且不再包含Claude 3.7 Sonnet中使用的第三个“规划工具”。
并在最后注明:在所有Claude 4模型中,他们报告的分数基于完整的500个问题。OpenAI模型的得分基于477道问题的子集进行报告。

基准还是OpenAI自己提的
如果说,SWE-bench Verified还是OpenAI自己提的基准,那这件事就更离谱了。
这不就相当于自己搬起石头砸自己的脚啦嘛。

当时啊还是因为类似的原因——他们测试发现SWE-bench的一些任务可能难以解决甚至无法解决,导致SWE-bench无法系统性评估模型的自主编程能力。
于是乎,他们决定与SWE-bench的作者合作,决定弄出个新版本,希望能够提供更准确的评估。
他们共同发起了一项人工注释活动,共有93位资深程序员参与进来,以筛选SWE-bench测试集每个样本,从而获得适当范围的单元测试和明确指定的问题描述。
他们随机抽取了1699个样本,然后基于统一标准来进行标注。
比如,问题描述是否明确?每个注释都有一个标签,范围从 [0, 1, 2, 3],严重程度依次递增。
标签0和1 表示轻微;标签2和3表示严重,表示样本在某些方面存在缺陷,应予以丢弃。
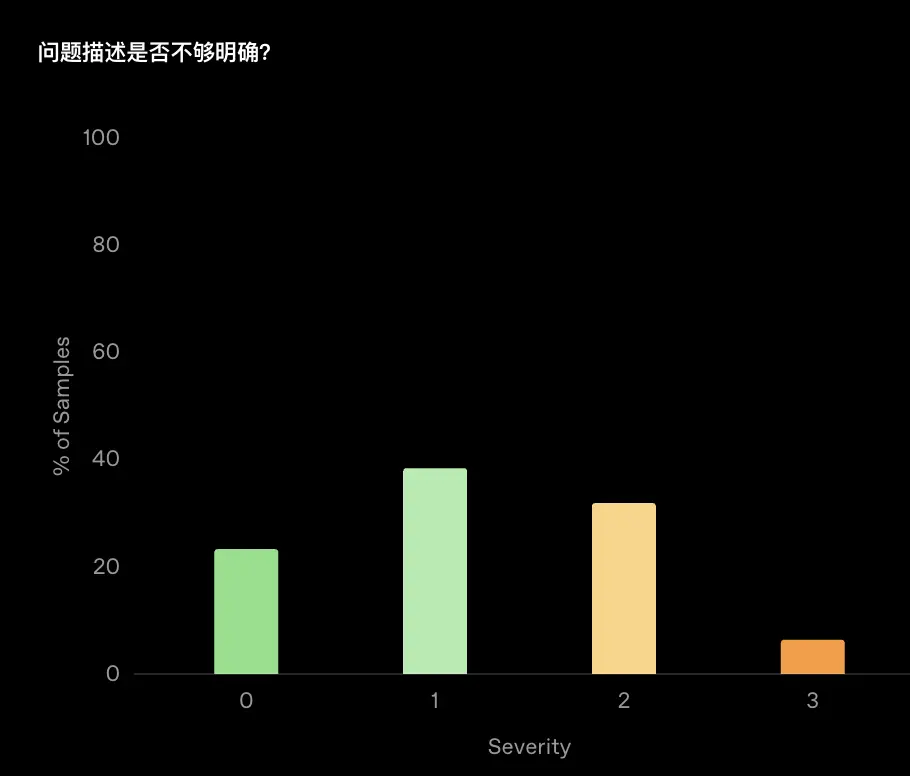
此外,我们还会评估每个示例的难度,方法是让注释者估算开发人员确定并实现解决方案所需的时间。
最终得到了500个经过验证的样本,并且按照难度对数据集进行细分。“简单”子集包含196个小于15分钟的修复任务,而“困难”子集包含 45 个大于 1 小时的任务。
结果现在这个子集又被OpenAI缩减了。
One More Thing
不过,还是有个总榜单或许值得参考,就是那个最原始的SWE-bench。
在这个榜单中,Claude 4 Opus还是占据着领先位置。