Google的领先优势,只保持了不到一个月。今天是 OpenAI 的十周年纪念日,十周年之际,来点大的。在“红色警报”后,OpenAI 在北京时间本周五拿出了最新的顶级模型 GPT-5.2 系列 —— 迄今为止在专业知识工作上最强大的模型系列。
简而言之,OpenAI 本次推出:
GPT-5.2 Instant,为日常工作与学习而打造:
与 GPT-5.1 一样温暖、对话自然
更清晰的讲解,把关键信息提前呈现
改进的操作指南与分步骤讲解
更强的技术写作与翻译能力
更好地支持学习与职业规划
GPT-5.2 Thinking,为专业级工作全面提升标准:
业界最先进的长上下文推理能力
在电子表格的生成、分析与排版方面取得重大提升
在演示文稿制作方面已有初步突破
GPT-5.2 Pro,在面对困难问题时最聪明、最值得信赖的模型:
在编程等复杂领域表现更强
最适合帮助并加速科学研究的模型
GPT-5.2 的设计目标,就是为人们创造更多经济价值:它在制作电子表格、构建演示文稿、编写代码、理解图像、处理超长上下文、使用工具,以及执行复杂的多步骤项目方面都有显著提升。
真正的生产力不是空口无凭,让我们来看看数据,GPT-5.2 到底有多强。
在如图所示的众多基准测试中,GPT-5.2 均刷新了最新的 SOTA 水平。
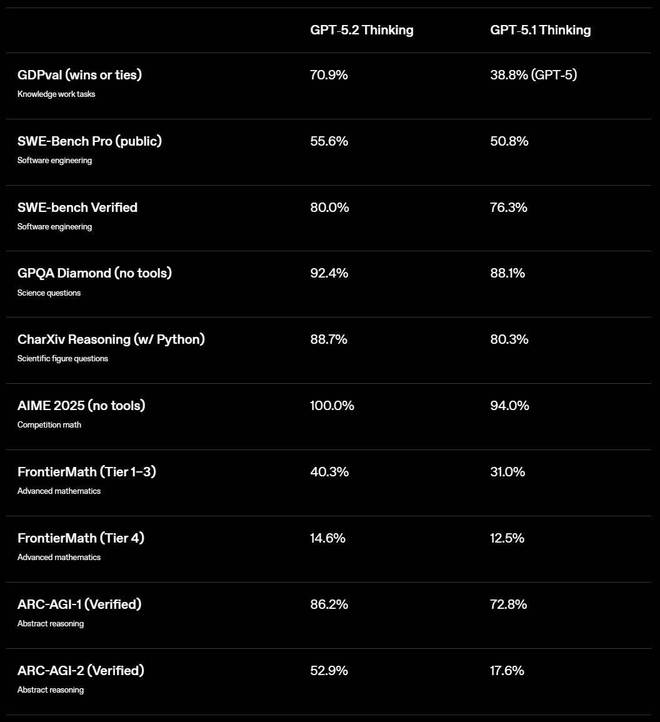
你可以注意到,AIME 2025(数学)的分数是 100%,之前 Gemini 3 Pro 的分数是 95%;ARC-AGI-2(抽象推理)的分数是 52.9%,对比 Gemini 3 Pro 是 31.1 %;此外 SWE-bench pro(编码)的分数是 55.6%,对比 Gemini 3 Pro 是 43.3 %。
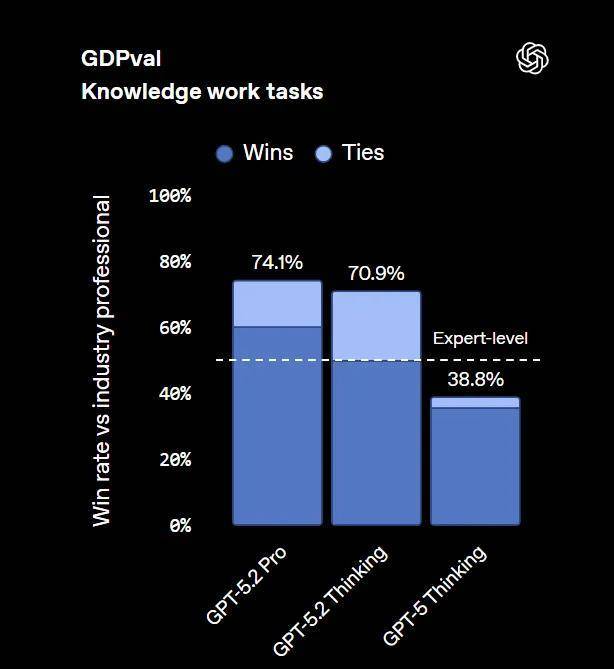
GPT-5.2 在 GDPval(知识工作)基准上的分数为 74.1%,OpenAI 声称这是 AI 模型首次达到了“人类专家水平”。
总体来看,GPT-5.2 在通用智能、长上下文理解、自主式工具调用以及视觉能力方面均带来了显著提升,使其比以往任何模型都更擅长端到端地完成复杂的真实世界任务。
山姆・奥特曼表示,GPT-5.2 是 OpenAI 很长一段时间以来最大的一次升级。
真正的生产力
GPT-5.2 Thinking 是迄今为止最适合真实世界专业场景的模型。在 GDPval—— 一个覆盖 44 个职业、针对明确知识工作任务的评估体系中,GPT-5.2 Thinking 刷新了 SOTA 成绩,并成为 OpenAI 首个整体表现达到或超过人类专家水平的模型。
根据专业评审的判断,在 GDPval 的知识工作任务对比中,GPT-5.2 Thinking 在 70.9% 的对比中击败或与顶尖行业专家持平。这些任务包括制作演示文稿、电子表格以及其他专业产出物。
在执行 GDPval 任务时,GPT-5.2 Thinking 生成输出的速度超过专家 11 倍以上,成本却低于 1%。这表明,在配合人工监督时,GPT-5.2 能显著辅助专业工作。
速度和成本估算基于历史数据;ChatGPT 中的实际速度可能有所差异。
在 GDPval 中,模型需要完成覆盖美国 GDP 贡献度最高的 9 大行业中 44 个职业的、明确规定的知识工作任务。这些任务要求生成真实的工作产出,例如:销售演示文稿、会计报表 / 电子表格、急诊排班表、制造流程图,甚至是短视频等。在 ChatGPT 中,GPT-5.2 Thinking 配备了 GPT-5 Thinking 所不具备的新工具。
在评审一份表现尤其出色的输出时,一位 GDPval 评委评论道:
“这是一次令人兴奋且明显的质量飞跃……[它] 看起来就像是由一家专业公司团队完成的,两个交付物的版式设计和建议都出乎意料地优秀,不过其中一个仍有一些小错误需要修正。”
此外,在 OpenAI 内部用于测试初级投行分析师能力的电子表格建模基准中(例如:为一家财富 500 强企业构建包含三张财务报表的模型,并具备正确格式和引用;或为私有化交易构建杠杆收购模型),GPT-5.2 Thinking 的任务平均得分比 GPT-5.1 提升了 9.3%,从 59.1% 上升到 68.4%。
对比显示,GPT-5.2 Thinking 在生成电子表格与演示文稿时,在专业度与排版质量上都有显著提升:
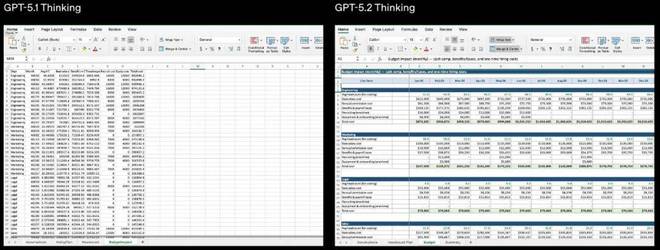
Prompt: Create a workforce planning model: headcount, hiring plan, attrition, and budget impact. Include engineering, marketing, legal, and sales departments.
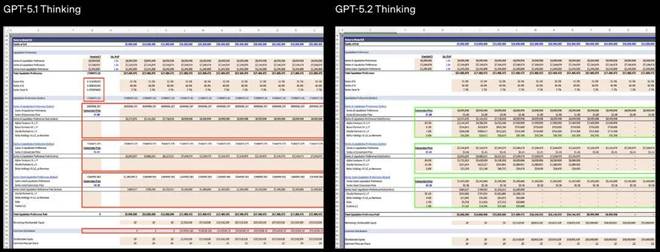
5.1 错误地计算了种子轮、A 轮和 B 轮的清算优先权,并且将这些行的大部分留空,导致最终的股权分配计算结果不正确。它还在表头行中错误地插入了公式。5.2 则完整且准确地完成了所有计算,并以可审计的方式呈现结果。

要在 ChatGPT 中使用新的电子表格和演示文稿生成功能,您需要使用 Plus、Pro、Business 或 Enterprise 方案,并选择 GPT-5.2 Thinking 或 GPT-5.2 Pro。复杂内容的生成可能需要数分钟时间。
新的编码高峰
GPT-5.2 Thinking 在 SWE-Bench Pro 上取得 55.6% 的最新 SOTA 成绩。
SWE-Bench Pro 是一个严格评估真实世界软件工程能力的基准。与只测试 Python 的 SWE-bench Verified 不同,SWE-Bench Pro 涵盖四种编程语言,并设计得更具抗污染性、挑战性、多样性和工业相关性。
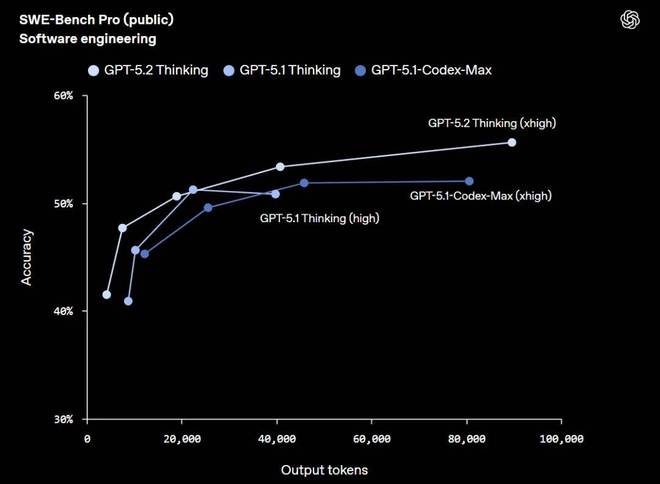
在 SWE-Bench Pro 中,模型会获得一个代码仓库,并必须生成补丁(patch)来解决一个真实的软件工程任务。
在 SWE-bench Verified 上,GPT-5.2 Thinking 取得了 80% 的新的最高分。
对于日常专业使用来说,这意味着模型在以下方面更加可靠:调试生产环境代码、实现功能请求、重构大型代码库,以及以更少人工干预的方式完成端到端修复。
GPT-5.2 Thinking 在前端工程能力上也优于 GPT-5.1 Thinking。早期测试者发现,它在前端开发以及复杂或非常规的 UI 设计(尤其是包含 3D 元素 的界面)方面的能力显著增强,使其成为全栈工程师的强大日常助手。
以下是它根据单条提示词即可生成的部分示例:
新的幻觉低谷
GPT-5.2 Thinking 的幻觉率显著低于 GPT-5.1 Thinking。
在一组来自 ChatGPT 的去标识化真实用户查询上,含错误的回答相对减少了 30%
对于专业用户而言,这意味着在进行研究、写作、分析和决策支持时,模型犯错更少,从而让日常知识工作更加可靠稳健。
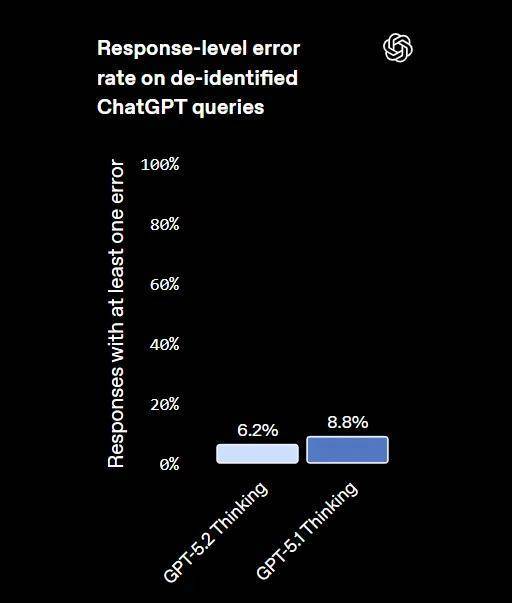
推理力度被设置为可用的最高级别,并启用了搜索工具。错误由其他模型检测,而这些模型本身也可能会出错。在主张级别(claim-level)的错误率远低于回答级别(response-level)的错误率,因为大多数回答都包含多个独立主张。
摆脱上下文限制
GPT-5.2 Thinking 在长上下文推理方面达到了新的业界最先进水平,在 OpenAI MRCRv2 上取得领先表现 —— 这是一个用于测试模型整合长文档中分散信息能力的评估基准。在真实世界任务(如深度文档分析)中,当相关信息分布在数十万 token 中时,GPT-5.2 Thinking 的准确性显著优于 GPT-5.1 Thinking。
特别值得注意的是,GPT-5.2 Thinking 是 OpenAI 首个在 4-needle MRCR 变体(长度可达 256k tokens)上达到接近 100% 准确率的模型。
从实际应用来看,这意味着专业人士可以使用 GPT-5.2 来处理超长文档 —— 例如报告、合同、科研论文、访谈记录以及多文件项目 —— 同时在数十万 token 的跨段信息中保持连贯性和准确性。这让 GPT-5.2 尤其适合深度分析、综合推理以及复杂的多来源工作流。
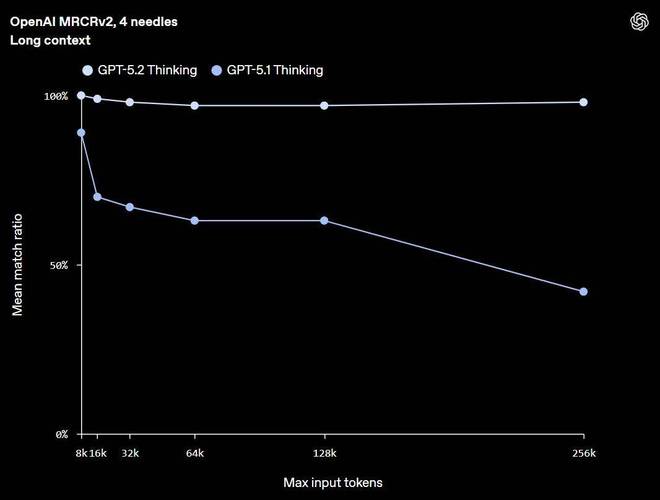
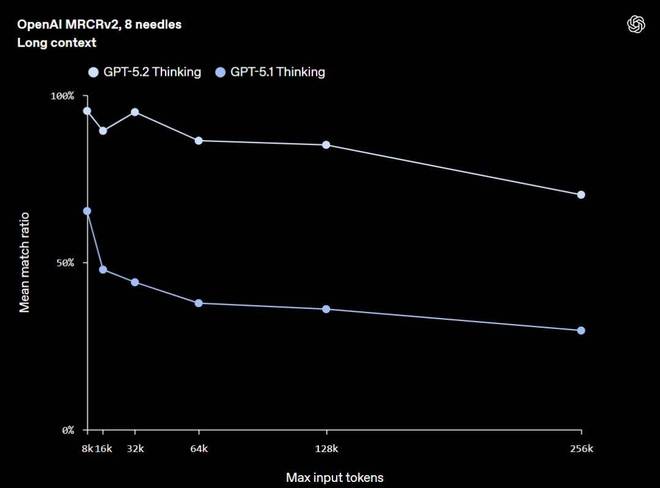
在 OpenAI-MRCR v2(多轮共指消解)评测中,会将多个相同的“针”(needle)式用户请求插入到由大量类似请求与回复构成的长“草堆”(haystacks)中,然后要求模型复现第 n 个针对应的回答。Mean match ratio(平均匹配率) 用于衡量模型回答与正确答案之间的平均字符串匹配程度。图中 256k 最大输入 token 的点代表对 128k–256k token 输入范围的平均表现,以此类推。其中 256k 表示 256 × 1,024 = 262,144 token。推理力度被设置为可用的最高级别。
对于那些需要在最大上下文窗口之外继续推理的任务,GPT-5.2 Thinking 兼容我们新的 Responses /compact 端点,它能够扩展模型的有效上下文窗口。
这使得 GPT-5.2 Thinking 可以处理更多依赖工具、运行时间较长的工作流,而不会受到上下文长度的限制。
精细的视觉理解
OpenAI 表示:“GPT-5.2 Thinking 是我们要目前最强的视觉模型,在图表推理和软件界面理解方面的错误率几乎降低了一半。”
对于日常的专业应用而言,这意味着该模型能够更准确地解读仪表盘、产品截屏、技术图表和视觉报告,从而为金融、运营、工程、设计以及客户支持等以视觉信息为核心的工作流提供强力支持。
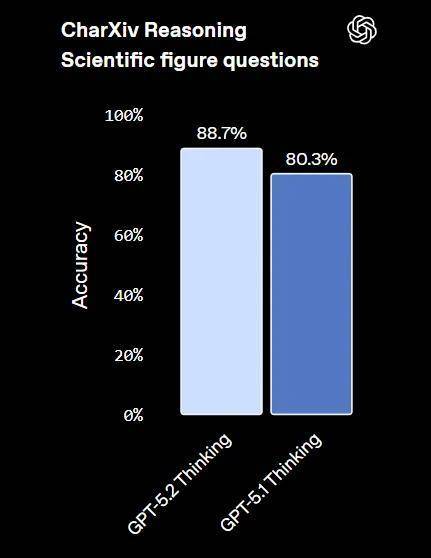
在 CharXiv Reasoning 中,模型需要回答关于科学论文中视觉图表的问题。测试中启用了 Python 工具,并将推理强度(reasoning effort)设为最大。
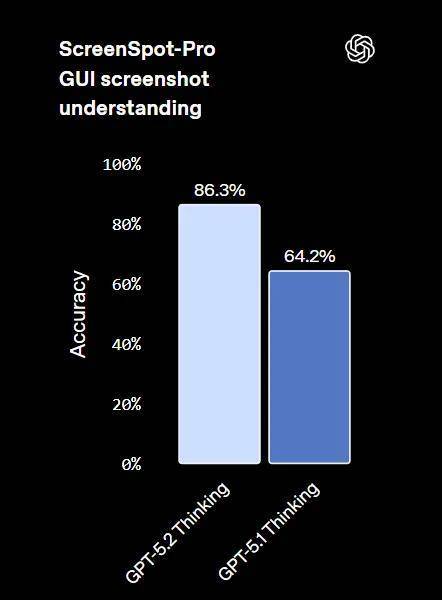
在 ScreenSpot-Pro 中,模型必须对来自各种专业环境的高分辨率图形用户界面(GUI)截图进行推理。测试中启用了 Python 工具,并将推理强度设为最大。如果不使用 Python 工具,得分会低得多。OpenAI 建议在此类视觉任务上启用 Python 工具。
与之前的模型相比,GPT-5.2 Thinking 对图像中各元素的位置关系理解得更加透彻,这对于“相对布局”在解决问题中起关键作用的任务尤为重要。
在下方的示例中,OpenAI 要求模型识别输入图像(本例中为主板)中的组件,并返回带有大致边界框的标签。即使在低质量图像上,GPT-5.2 也能识别出主要区域,并放置有时能与每个组件真实位置相匹配的框;而 GPT-5.1 仅标记了少数几个部分,且对其空间排列的理解要弱得多。

很明显,两个模型都存在错误,但 GPT-5.2 展示出了对图像更好的理解力。
可靠的工具调用
GPT-5.2 Thinking 在 Tau2-bench Telecom 上取得了 98.7% 的新 SOTA 成绩,展示了其在长链路、多轮任务中可靠使用工具的能力。
对于延迟敏感的用例,GPT-5.2 Thinking 在 reasoning.effort='none'(不进行额外推理思考)模式下的表现也要好得多,大幅优于 GPT-5.1 和 GPT-4.1。

在 τ2-bench 中,模型需要使用工具与模拟用户进行多轮交互,以完成客户支持任务。对于电信领域,OpenAI 在系统提示词中包含了一条简短且通用的指导说明以提升性能。由于航空子集的基准真实标签评分质量较低,OpenAI 将其排除在外。
对于专业人士来说,这可以转化为更强大的端到端工作流 —— 例如解决客户支持案例、从多个系统提取数据、运行分析以及生成最终输出,且步骤之间的断裂或阻滞更少。
例如,当询问一个需要多步解决的复杂客服问题时,模型可以更有效地协调跨多个智能体的完整工作流。
在下面的案例中,一位旅客报告了航班延误、错过了转机、需要在纽约过夜以及医疗座位需求。GPT-5.2 管理了整个任务链(重新预订、特殊协助座位和赔偿),提供了比 GPT-5.1 更完整的结果。
“我从巴黎到纽约的航班延误了,导致我错过了去奥斯汀的转机。我的托运行李也不见了,我需要在纽约过夜。此外,因为医疗原因我还需要一个特殊的前排座位。你能帮我吗?”

探索科学与数学边界
OpenAI 表示其对 AI 的愿景之一,是希望它能加速科学研究,造福每一个人。为此,OpenAI 一直与科学家合作并倾听他们的意见,探索 AI 如何能加速他们的工作。
上个月,OpenAI 在论文《Early experiments in accelerating science with GPT-5》中分享了一些早期的合作实验。
OpenAI 表示:“我们相信 GPT-5.2 Pro 和 GPT-5.2 Thinking 是目前世界上辅助和加速科学家工作的最佳模型。”
在 GPQA Diamond(一个研究生级别的“防Google搜索”问答基准测试)上,GPT-5.2 Pro 达到了 93.2%,GPT-5.2 Thinking 紧随其后,达到了 92.4%。

在 GPQA Diamond 中,模型需要回答关于物理、化学和生物的多项选择题。测试中未启用工具,并将推理强度设为最大。
在 FrontierMath (Tier 1–3) 这一专家级数学评估中,GPT-5.2 Thinking 创下了新的 SOTA,解决了 40.3% 的问题。

在 FrontierMath 中,模型解决专家级数学问题。测试中启用了 Python 工具,并将推理强度设为最大。
OpenAI 表示:“我们开始看到 AI 模型以切实可见的方式有意义地加速数学和科学的进步。例如,在最近使用 GPT-5.2 Pro 的一项工作中,研究人员探索了统计学习理论中的一个开放性问题。在一个狭窄且定义明确的设定中,模型提出了一个证明,随后该证明被作者验证并由外部专家审查,这生动地说明了前沿模型如何在密切的人类监督下辅助数学研究。”
通用推理 ARC-AGI 2
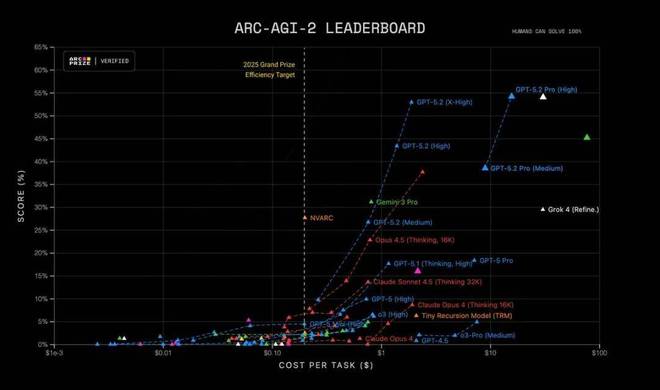
在 ARC-AGI-1 (Verified)(一个旨在衡量通用推理能力的基准测试)上,GPT-5.2 Pro 是首个突破 90% 门槛的模型。相比去年 o3-preview 达到的 87%,它不仅实现了性能提升,还将达成该性能的成本降低了约 390 倍。
在 ARC-AGI-2 (Verified) 上(该测试提高了难度并更好地隔离了流体推理能力(fluid reasoning)),GPT-5.2 Thinking 取得了思维链模型的新 SOTA,得分为 52.9%。GPT-5.2 Pro 的表现甚至更高,达到了 54.2%,进一步扩展了模型对新颖、抽象问题进行推理的能力。
在这些评估中的提升,反映了 GPT-5.2 更强的多步推理能力、更高的定量准确性,以及在处理复杂技术任务时更可靠的问题解决能力。
在 ChatGPT 中使用 GPT-5.2
OpenAI 表示:“在 ChatGPT 中,用户应该会注意到 GPT-5.2 的日常使用体验更佳 —— 它更有条理、更可靠,且对话体验依然令人愉悦。”
该公司给 GPT-5.2 Instant 的定位是日常工作和学习的快速、强力助手。它延续了 GPT-5.1 Instant 引入的更温暖的对话基调,并在信息搜寻、实操指南与分步教程、技术写作以及翻译方面有明显改进。早期测试者特别指出,其解释更加清晰,能够将关键信息前置。
GPT-5.2 Thinking 专为深度工作设计,帮助用户以更高的完成度处理更复杂的任务 —— 特别是在代码编写、长文档总结、基于上传文件的问答、逐步处理数学和逻辑问题,以及通过更清晰的结构和更实用的细节支持规划与决策方面。
GPT-5.2 Pro 是 OpenAI 处理难题时最聪明、最值得信赖的选择。对于那些值得等待的高质量回答,它表现最佳。早期测试显示,其在编程等复杂领域的重大错误更少,表现更强。
安全
GPT-5.2 基于 OpenAI 在 GPT-5 中引入的“安全完成”研究,该研究旨在教会 AI 模型在确保安全的前提下,给出最有帮助的答案。
据说在此版本中,研究人员继续致力于增强模型在敏感对话中的响应能力,显著改进了模型对提示自杀或自残迹象、心理健康困扰或对模型的情感依赖等问题的响应。与 GPT-5.1 和 GPT-5 Instant 及 Thinking 模型相比,这些针对性的干预措施显著减少了 GPT-5.2 Instant 和 GPT-5.2 Thinking 模型的不良响应。
OpenAI 提到,GPT-5.2 能够自动为 18 岁以下用户应用内容保护,从而限制他们访问敏感内容。

定价
ChatGPT 将于今日开始逐步推出 GPT-5.2(包括 Instant、Thinking 和 Pro 版本),首先面向付费用户(Plus、Pro、Go、Business 和 Enterprise 版本)提供。为确保 ChatGPT 的流畅性和稳定性,GPT-5.2 将分阶段部署,可能有人第一时间无法看到。在 ChatGPT 中,付费用户仍可在三个月内继续使用 GPT-5.1(旧版模式),之后 GPT-5.1 将逐步下线。

在 API 平台上,GPT-5.2 Thinking 以 gpt-5.2 的名义提供,GPT-5.2 Instant 则以 gpt-5.2-chat-latest 的名称提供。GPT-5.2 Pro 以 gpt-5.2-pro 的名称提供。开发者现在可以在 GPT-5.2 Pro 中设置推理参数,并且 GPT-5.2 Pro 和 GPT-5.2 Thinking 均支持新的第五级推理难度 xhigh,适用于对质量要求极高的任务。
以下是百万 token 的价格,OpenAI 称,尽管 GPT-5.2 的单个 token 成本更高,但由于其更高的 token 效率,达到特定质量水平的总成本反而更低。
ChatGPT 的订阅价格保持不变。

OpenAI 表示,目前没有计划在 API 中弃用 GPT-5.1、GPT-5 或 GPT-4.1。虽然 GPT-5.2 在 Codex 中开箱即用,但 OpenAI 还预计将在未来几周内发布一个针对 Codex 优化的 GPT-5.2 版本。
GPT-5.2 是 OpenAI 与长期合作伙伴英伟达和 Microsoft 合作开发的。Azure 数据中心和英伟达 GPU(包括 H100、H200 和 GB200-NVL72)为 OpenAI 的大规模训练基础设施提供了支撑。
OpenAI 十周年
今天是 OpenAI 十岁生日,发布新模型的同时,创始人、CEO 山姆・奥特曼撰文说道:
OpenAI 取得的成就远超我的想象;我们当初的目标是做一些疯狂的、几乎不可能的、前所未有的事情。从充满不确定性的开端,克服重重困难,凭借持续不断的努力,我们现在看来很有可能实现我们的使命。
十年前的今天,我们向世界宣布了我们的计划,尽管我们当时并没有正式启动。又过了几个星期,直到 2016 年 1 月初(才正式开始)。
从某种意义上说,十年是一段很长的时间,但就社会变革通常所需的时间而言,十年其实并不算长。虽然日常生活与十年前并没有太大的不同,但我们今天所面临的可能性空间,与我们当年十五个书呆子围坐在一起,苦思冥想如何取得进步时所感受到的截然不同。
回看早期的照片,我首先注意到的是大家看起来都好年轻。但随后,我又注意到大家那种异乎寻常的乐观和快乐。那是一段疯狂而又充满乐趣的时光:尽管我们不被人理解,但我们却有着坚定的信念,觉得这件事意义非凡,即使成功的机会渺茫也值得全力以赴;我们拥有才华横溢的人,以及清晰的目标。
随着我们取得一些成功(以及许多失败),我们逐渐对现状有了更清晰的认识。那时,要确定具体应该做什么并不容易,但我们建立了一种鼓励探索的卓越文化。深度学习无疑是一项伟大的技术,但如果没有在现实世界中积累应用经验就贸然开发,似乎不太合适。我在此略过我们所做的一切(希望将来有人能写成一部历史著作),但我们始终秉持着一种积极进取的精神,不断探索眼前的下一个挑战:研究的下一步方向是什么?如何筹集资金购买更强大的计算机?等等。我们率先开展了使人工智能安全可靠且切实可行的技术工作,这种精神一直延续至今。
2017 年,我们取得了一些奠基性的成果:Dota 1v1 的实验结果,将强化学习推向了新的规模;无监督情感神经元实验,证明语言模型能够清晰地学习语义,而不仅仅是语法;基于人类偏好的强化学习成果,展示了将人工智能与人类价值观相契合的初步途径。当时,创新远未结束,但我们深知,需要借助强大的计算能力来扩展这些成果。
我们坚持不懈,不断改进技术,并在三年前推出了 ChatGPT。世界为之瞩目,而 GPT-4 的发布更是引起了广泛关注;突然之间,通用人工智能(AGI)不再是天方夜谭。过去的三年极其紧张,压力巨大,责任重大;这项技术以前所未有的规模和速度融入了世界。这需要极其高超的执行力,我们必须迅速培养新的能力来应对。在如此短的时间内从零发展成为一家庞大的公司绝非易事,我们每周都要做出数百个决策。我为团队做出的众多正确决策感到自豪,而那些错误决策大多是我的责任。
我们不得不做出一些新的决策;例如,在思考如何让 AI 最大限度地造福世界时,我们制定了一项迭代部署策略,将早期版本的技术成功推向市场,让人们形成认知,社会与技术共同演进。这在当时颇具争议,但我认为这是我们做出的最明智的决策之一,如今已成为行业标准。
OpenAI 成立十年以来,我们拥有的 AI 能够在最艰难的智力竞赛中胜过我们大多数最聪明的人。
世界已经利用这项技术创造了非凡的成就,我们期待明年还能看到更多非凡的成果。迄今为止,世界在减轻潜在的负面影响方面也做得不错,我们需要继续努力,保持这种势头。
我从未像现在这样对我们的研发和产品路线图,以及实现我们使命的整体方向感到如此乐观。我相信,再过十年,我们几乎肯定能够打造出超级智能。我预感未来会有些奇特;在某种程度上,日常生活和我们最关心的事情几乎不会发生太大变化,而且我相信,我们会继续更加关注其他人所做的事情,而不是机器所做的事情。但在另一方面,2035 年的人们将能够做到我们现在难以想象的事情。
衷心感谢那些信任我们并使用我们的产品创造佳绩的个人和公司。如果没有他们的支持,我们或许还只是实验室里的一项技术;我们的用户和客户在很多情况下都对我们寄予了过高的期望,没有他们的支持,我们的工作不可能达到今天的成就。
我们的使命是确保 AGI 造福全人类。面前还有很多工作要做,但我为团队目前的发展方向感到非常自豪。我们已经看到人们利用这项技术所取得的巨大成果,而且我们知道,未来几年还将有更多成果涌现。
参考内容:
https://openai.com/index/introducing-gpt-5-2/
https://openai.com/index/ten-years/
GPT 5.2 System Card:
https://cdn.openai.com/pdf/3a4153c8-c748-4b71-8e31-aecbde944f8d/oai_5_2_system-card.pdf