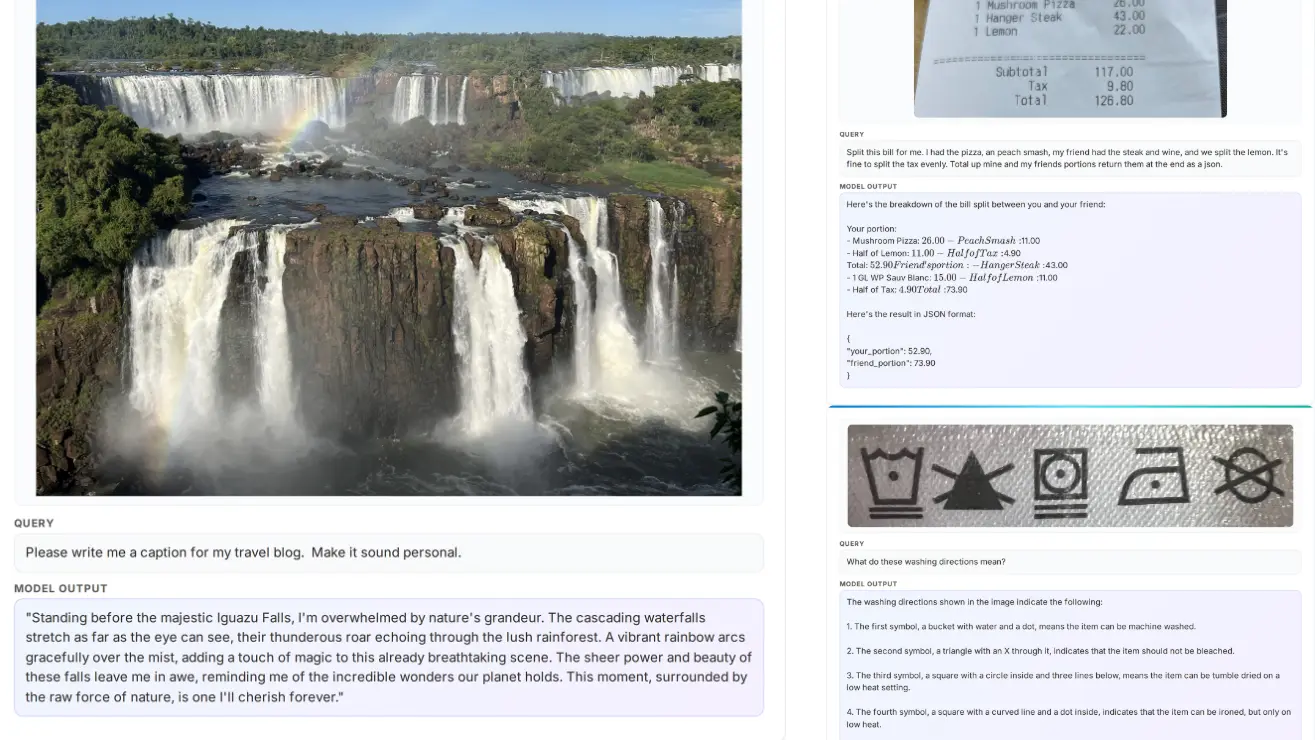
微软近日发布了一款全新的开源权重多模态大模型 Phi-4 15B,其最大亮点在于号称能够“自己决定什么时候该认真思考、什么时候该直接给出答案”,这一特性在目前的开源大模型中并不多见。 这款完整名称为 Phi-4-reasoning-vision-15B 的模型拥有 150 亿参数,面向图像描述、界面元素理解定位以及复杂数学推理等高难度任务场景进行设计。
微软在其架构中加入了一种“思考模式”控制机制,使得模型可以在需要深入推理时主动拉长思考链条,而在简单问题上则快速返回结果,而不再像其他模型那样只能由用户统一打开或关闭“思考模式”。 微软认为,这种按需“开启思考”的方式有望在效率与效果之间取得更好平衡,但同时也承认这一行为可能在实际应用中表现出一定不可预测性,仍需更多真实场景测试来检验其实际表现。
在训练数据方面,Phi-4 15B 也走了一条“精训而非海量堆料”的路线。据介绍,该模型仅使用了约 2000 亿 token 完成训练,而行业中同体量乃至更大规模的模型往往需要消耗上万亿级别的 token 才能“养成”。 微软研发团队强调,他们在训练数据选取上更加偏向高质量内容,理论上有助于模型给出更准确、更可靠的回答。 不过,报道也指出,理论上的高质量并不必然等同于实际使用中的高水平表现,尤其是在微软还借助 GPT‑4o 参与辅助训练的前提下,Phi‑4 15B 在真实环境中的输出效果还需要时间验证。
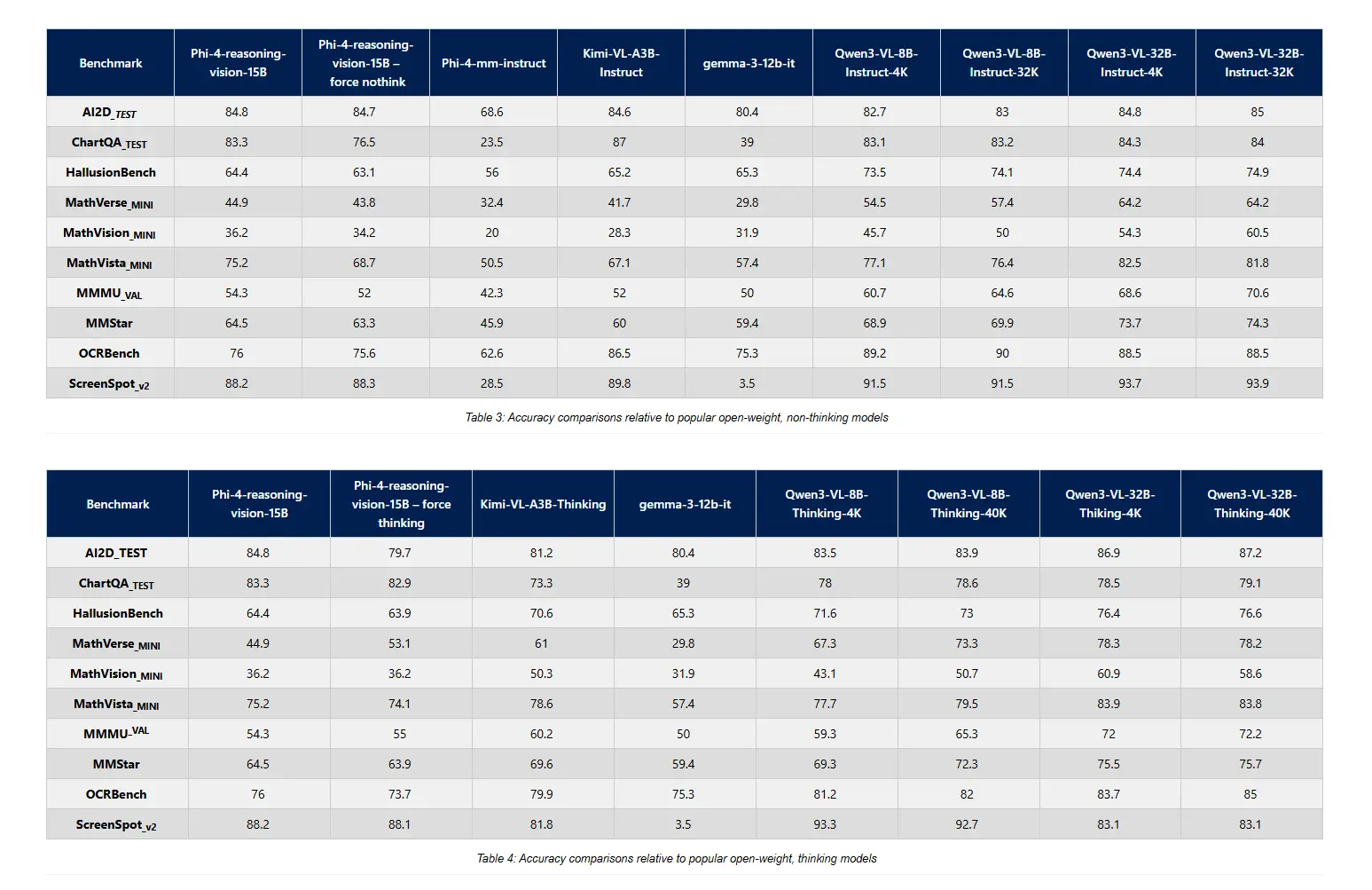
在公开的基准测试中,微软将 Phi-4 15B 与同级甚至略大规模的其他开源多模态模型进行了对比,结果可谓“喜忧参半”:在部分测试项目中,Phi-4 15B 确实实现了对更大模型的反超,但在另一些指标上则落后于竞品。微软在展示这些数据时并未刻意“美化”,而是给出了相对真实的对比表现,这一点也在报道中被特别点出。 文章同时提醒,基准测试往往只能反映模型能力的一个切面,并不能完全代表其在真实场景中的综合表现,最终评价仍有赖开发者与用户的长期使用体验。
报道还提到,微软 Phi-4 系列开源权重模型在社区中整体存在“被低估”的情况:一方面,开源圈当前的讨论焦点更多集中在来自中国厂商的模型(例如 Qwen 3.5 等),另一方面,微软自身在宣传这些小模型上的投入也相对有限,其重心更多放在为各类“前沿大模型”提供底层云基础设施与平台服务上。 即便如此,Phi-4 15B 依旧被认为在“小而精”的路线中具有一定竞争力:参数规模相对克制,推理能力在部分任务上不输更大模型,加上多模态与“自适应思考”的特性,使其对有本地部署或者成本敏感需求的开发者来说,依然是一个值得关注的选项。
目前,微软已在多处渠道向公众开放了 Phi-4 15B 的模型权重与配套资源。开发者可以前往微软技术社区博客了解更详尽的技术说明与设计思路,也可以直接在 Hugging Face 以及 Microsoft Foundry 上获取模型开源权重,并将其集成到自身的应用与服务之中。 随着更多开发者开始在真实业务场景中试用 Phi-4 15B,这一号称能“自己决定何时思考”的新模型究竟能否在开源生态中脱颖而出,也将在接下来的实践中逐步见分晓。