6月29日,DeepSeek发送给用户的升级提醒邮件显示,DeepSeek V4正式版计划于7月中旬正式上线,与之而来的则是更多功能优化和性能提升,以及峰谷时定价机制。根据邮件,北京时间每日9:00至12:00、14:00至18:00被列为高峰时段,调用价格为平时的2倍。同时,DeepSeek表示,在相关调整发生前,将提前24小时通过邮件通知用户。
“涨价”前的“永久降价”
据悉,今年以来,这已经不是DeepSeek第一次调整价格。官方API文档显示,DeepSeek按百万tokens计费,并根据缓存命中、缓存未命中和输出tokens分别收费,同时DeepSeek V4系列本身对算力的要求也不低。
4月24日,DeepSeek发布V4 Preview时就表示,V4 Pro为1.6万亿总参数、490亿激活参数,V4 Flash为2840亿总参数、130亿激活参数,两者均支持100万tokens上下文。
官方文档还显示,V4 Flash并发限制为2500;而V4 Pro这种高性能版模型并发限制为500,其供给弹性弱于Flash。
5月23日,DeepSeek宣布将此前的V4 Pro的75%优惠降价转为永久价格,API费用从此前最高24元/百万tokens降至最高6元/百万tokens。市场当时猜测,可能来自华为昇腾950芯片的供应增加有关,但DeepSeek并对此作出回应。
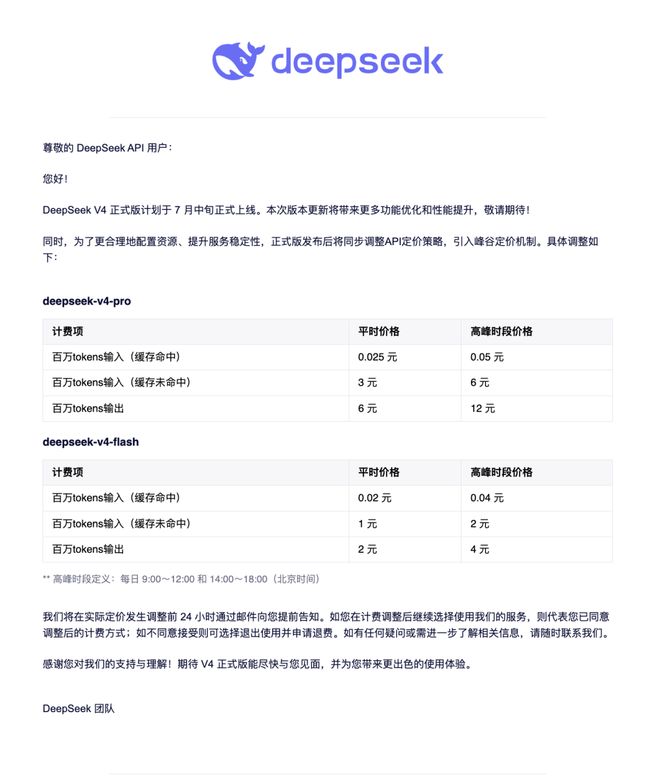
永久降价后,目前V4 Pro的平时价格为,缓存命中输入0.025元/百万tokens,缓存未命中输入3元/百万tokens,输出6元/百万tokens;V4 Flash的对应价格分别为0.02元、1元和2元。而到了高峰时段,这些价格将翻倍,但依然比此前发布时的价格低。
对普通用户而言,这次调整未必会直接体现为聊天应用收费变化;主要受影响的是通过API接入DeepSeek模型的开发者、AI应用公司和企业客户。
同样以V4 Pro为例,在计算输出tokens的情况下,若一家AI应用在高峰时段每天消耗1亿输出tokens,平时成本约为600元,高峰价下约为1200元;若每天消耗10亿输出tokens,成本则由约6000元升至1.2万元。对于客服、代码助手、办公Agent、搜索增强问答等高频应用,价格翻倍可能会直接影响毛利率和调用策略。
并非放弃低价路线
目前,DeepSeek引入峰谷时定价并非放弃低价路线。更准确地说,DeepSeek只是把算力资源按使用时段重新分层,使其低价策略开始从统一便宜变成精细化便宜。
因为仅从tokens的定价看,DeepSeek在引入峰谷时之后仍处于低价的“真香”区间,放在国际市场依然非常具有竞争力,这也是DeepSeek涨价的底气。
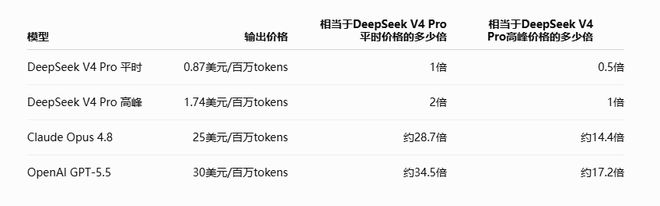
根据DeepSeek英文API价格页显示,V4 Pro输出价格为0.87美元/百万tokens,按高峰翻倍测算约为1.74美元。相比之下,OpenAI官方价格页显示,GPT-5.5标准API价格为输入5美元、缓存输入0.5美元、输出30美元/百万tokens;Anthropic的Claude Opus 4.8常规价格为输入5美元、输出25美元/百万tokens。
若仅看输出tokens,OpenAI和Anthropic高端模型价格仍约为DeepSeek V4 Pro峰时价的14—17倍。
另一方面,随着海外市场大模型定价模式从固定订阅转向按tokens计费,企业的使用成本开始巨大攀升,许多预算有限的海外企业,正把更多调用转向DeepSeek等低成本模型。
据此前报道,以打车软件Uber为例,因为大模型定价模式转变后,仅仅4个月就迅速消耗了公司全年的AI预算,导致不得不限制高管使用,有幸成为“第一个叫停AI烧钱的大厂”。
而微软、Coinbase等公司的高管也开始强调,许多企业任务并不总需要最昂贵、最大的模型。这些变化都推动企业更多采用“多模型路由”,即把简单任务交给便宜模型,复杂任务再交给高端模型。
因此,OpenRouter的数据显示,开源模型已承担其平台上约65%的token处理量,其中以DeepSeek为代表的中国低成本模型的使用量,已明显上升,直观反映出海外用户已进入“精打细算”时代。