高通Cloud AI 100平台开始出样:75W实现400TOPS算力
AnandTech 报道称,高通去年宣布的 Cloud AI 100 推理芯片平台,现已投产并向客户出样,预计 2021 上半年可实现商业发货。虽然更偏向于“纸面发布”,且未能披露硬件的更多细节,但借助其在移动 SoC 世界的专业知识,这也是该公司首次涉足数据中心 AI 推理加速器业务、并将之推向企业市场。

随着芯片开始出样,高通 Cloud AI 100 推理芯片终于从实验室走向了现实,并且披露了有关其架构设计、性能功耗目标在内的诸多细节。
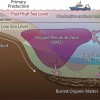
据悉,高通为商业化部署提供了三种不同的封装形式,包括成熟的 PCIe 4.0 x8 接口(在 75W TDP 上实现 400 TOPS 算力)、以及 DM.2 和 DM.2e 接口(25W / 15W TDP)。

DM.2 的外形类似于彼此相邻的两个 M.2 连接器,在企业市场上颇受欢迎。DM.2e 则是体型更小,封装功耗也更低。
从架构的角度来看,该设计借鉴了高通在骁龙移动 SoC 上部署的神经处理单元(NPU)的丰富经验,但仍基于一种完全针对企业工作负载而优化的独特架构设计。

与当前的通用计算硬件(CPU / GPU / FPGA)相比,专用型 AI 设计的最大优势,在于能够实现“传统”平台难以企及的更高的性能和能效目标。
性能数据方面,高通拿目前业内常用的解决方案进行了对比,包括英特尔 Goya 和英伟达 T4 推理加速器(基于砍了一刀的 TU104 GPU 芯片),每瓦每秒的推理能力为 ResNet-50 。

据说 Cloud AI 100 在每瓦性能上较竞品实现了重大飞越,且高通在另一幅图表中展示了一个相对公平的比较。
有趣的说法是,其甚至能够在 75W 的 PCIe 外形尺寸内击败英伟达 Ampere 架构的 250W A100 加速器。且在功耗降低 25% 的情况下,性能还较英特尔 Goya 加速器翻了一番。

这样的性能数据,让许多人觉得难以置信,不过从 Cloud A100 的芯片规格来看,事情其实并不简单。该芯片包含了 16 组 AI 内核,和达成 400 TOPS 的 INT8 推理吞吐量。
辅以 4 路 @ 64-bit 的 LPDDR4X-4200(2100MHz)的内存控制器,每个控制器管着 4 个 16-bit 通道,总系统带宽达 134 GB/s 。

如果你对当前的 AI 加速器设计比较熟悉,就知道它与英伟达 A100 和英特尔 Goya 等推理加速器竞品的带宽有较大差距,因为后者具有高带宽缓存(HBM2)和高达 1-1.6 TB/s 的带宽。
即便如此,高通还是设法为 Cloud AI 100 平台配备了 144MB 的片上 SRAM 高速缓存,以达成尽可能高的存储流量。

高通承认,在工作负载的内存空间占用超过片上 SRAM 的情况下,该架构的性能将有所不同。但对于目标客户来说,这样的平衡设计,仍是有意为之。
后续该公司还展望了更大的内核、以及在多个 Cloud AI 100 加速器之间横向扩展。在被问及如何达成 15W 至 75W 的动态功耗范围时,高通宣称其正在调整频率 / 电压曲线,以及调制 AI 核心的数量。

想象一下,一套完整的 400 TOPS 75W 设计,包含了一个工作频率较高的芯片。而 15W TDP 的版本,可能以较低的频率在运行。与此同时,7nm 的工艺节点,有助于其进一步降低功耗。
精度方面,Cloud AI 100 的架构体系支持 INT8 / INT16 和 FP16 / FP32 精度,能够带来足够的灵活性。高通还提供了一组 SDK,以便为各项行业标准提供交换格式和框架支持。

高通公司目前正在向客户提供 Cloud AI 100 推理加速器的样品,主要部署目标为工业和商业领域中的边缘推理工作负载。
为推动生态系统和为软件开发提供支持,该公司还推出了新的 Cloud Edge AI 100 开发套件,其中包括了一个集成该加速器的小型计算设备、骁龙 865 SoC、以及用于蜂窝连接的 X55 5G 调制解调器。