老黄亮出全球最小超算,大模型在家跑 5090惊天问世 惊爆价16499
就在刚刚,RTX 5090震撼发布,国行版定价16499元!同时震撼亮相的,还有全球最小AI超算Project Digits,在办公桌上就能跑出数据中心级算力!这一刻老黄摆出别致pose,吸引了全球目光。
他来了,他来了,今天,老黄穿着崭新的夹克出场了。刚刚的CES大会上,老黄宣布RTX 5090正式发布。

50系列GPU,价格如下——
RTX 5090:1999美元 / RTX 5090 D:16499元
RTX 5080:999美元 / 8299元
RTX 5070 Ti:749美元
RTX 5070:549美元

RTX 5090系列和RTX 5080将于1月30日上市,RTX 5070 Ti和RTX 5070将于2月上市,RTX 50系列笔记本电脑将于3月推出
紧接着,老黄以一个别致的“美国队长”造型赢得全场喝彩,并揭秘了全新的数据中心超级芯片——Grace Blackwell NVLink72。
它配备了72个Blackwell GPU、1.4 exaFLOPS算力和130万亿个晶体管,目标是超越世界最快超算。


随后,全球首款真正意义上的桌面超算——Project Digits震撼登场。
这款全球最小AI超算,售价仅3000美金。
有了它,200B大模型在办公桌上就能跑了。
也就是说,它只占用你桌面一个咖啡杯的体积,却能提供数据中心级的算力!

搭载全新GB10 Grace Blackwell超级芯片的Project Digits,能在FP4计算精度下,提供高达1 PFLOPS的性能。
老黄预言:在未来,每个数据科学家、研究者和学生的桌子上,都会有一台Project Digits这样的个人AI超算。
AI时代,将属于每一个人。

RTX 5090首秀,DLSS 4也来了
经过数月的泄密和小道消息,全新一代的RTX Blackwell GPU终于正式亮相了。
首先来看一波性能参数:
920亿个晶体管
4000 TOPS的AI算力
380 TFLOPS的光追算力
125 TFLOPS的着色器算力
32GB的GDDR7显存
1792GB/秒的内存带宽
高达21760个CUDA核心
值得注意的是,RTX 5090 D的AI算力只有2375 TOPS。
不过,虽然比满血版的5090少了一半,但至少比4090 D高了一倍。


如此豪华的配置,再加上DLSS 4和Blackwell架构的加持,RTX 5090的性能直接达到了RTX 4090的两倍之多。
然而,这也意味着它的功耗会很高,(RTX 5090的总显卡功耗为575瓦特,推荐电源供应器功率为1000瓦特)。
demo显示,在RTX 5090上运行《赛博朋克2077》时,启用DLSS 4后达到了238帧每秒,而在RTX 4090上启用DLSS 3.5时,只有106帧每秒。

RTX 5080比RTX 4080快一倍,配备16GB的GDDR7显存,内存带宽为960GB/秒,CUDA核心数量为10752个。
RTX 5070 Ti配备16GB的GDDR7显存,内存带宽为896GB/秒,CUDA核心数量为8960个。
RTX 5070则配备12GB的GDDR7显存,内存带宽为672GB/秒,CUDA核心数量为6144个。
老黄甚至宣称,RTX 5070将以549美元的价格,提供RTX 4090级别的性能,这无疑是由于DLSS 4的提升。




左右滑动查看
另外,老黄还展示了RTX Blackwell GPU,并进行了一场实时渲染演示。
他表示,“新一代的DLSS不仅仅是生成帧,它还能预测未来。我们用GeForce推动了AI,而现在AI正在革新GeForce。”
NVIDIA全新的RTX神经着色器可用于压缩游戏中的纹理,而RTX神经面孔则利用生成式AI来提高面部质量。
下一代DLSS包含了多帧生成技术,可以在每个传统帧的基础上生成最多三个额外的帧,使帧率比传统渲染提高了多至8倍。
并且,DLSS 4还包括了Transformer在实时应用中的使用,能够提升图像质量、减少鬼影效果,并在动态画面中增加更高的细节。

值得一提的是,英伟达在RTX 50系列的Founders Edition上采用了全新设计。
配备了两个双流量风扇、3D均热板和GDDR7显存。RTX 50系列所有显卡均支持PCIe Gen 5,并配有DisplayPort 2.1b接口,能够驱动最高8K分辨率和165Hz的显示器。
令人惊讶的是,RTX 5090 Founders Edition是一款双插槽显卡,能够适配小型机箱,跟RTX 4090的尺寸相比,这是一个巨大的变化。

英伟达高级科学家Jim Fan,发现了老黄演讲中关于图形技术的“华点”。
你们都在期待RTX 5090的发布,关注它的规格参数,但你们是否真正理解黄仁勋关于图形技术的说法? 新显卡使用神经网络来生成游戏中90%以上的像素! 传统的光线追踪算法只渲染约10%的内容,相当于一个“粗略的草图”,然后由生成式模型实时地在一次前向传递中填充其余的细节。 女士们先生们,AI就是新一代的图形技术。

50系显卡首秀之后,老黄提到“Scaling law仍在继续”:
第一个scaling law是预训练
第二个scaling law 是后训练
第三个scaling law是测试时计算
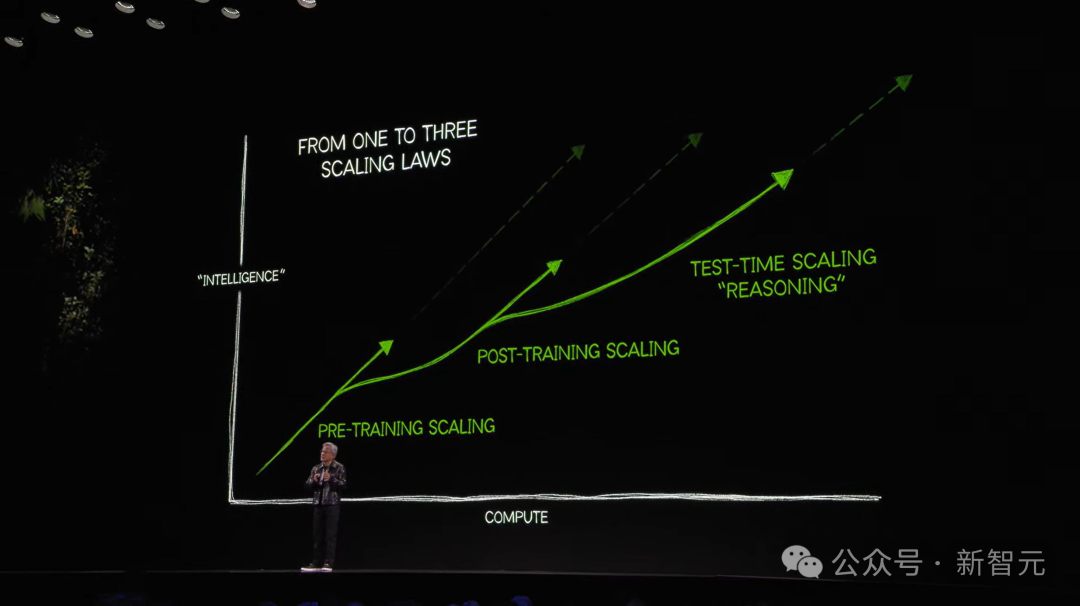
scaling law不断演进,推动着AI对计算的巨大需求。
令人惊叹的是,包括微软、Meta、xAI约15个超算中心,都已经装上了Blackwell GPU。

接下来,他又提到了智能体AI,是测试时scaling完美的应用示例。
同时,他还宣布推出了一系列开放许可的基础模型—— Llama Nemotron,能够在各类智能体任务中提供极高的精度。
老黄称,“AI智能体可能是下一个机器人产业,可能是价值数万亿美元机会”。

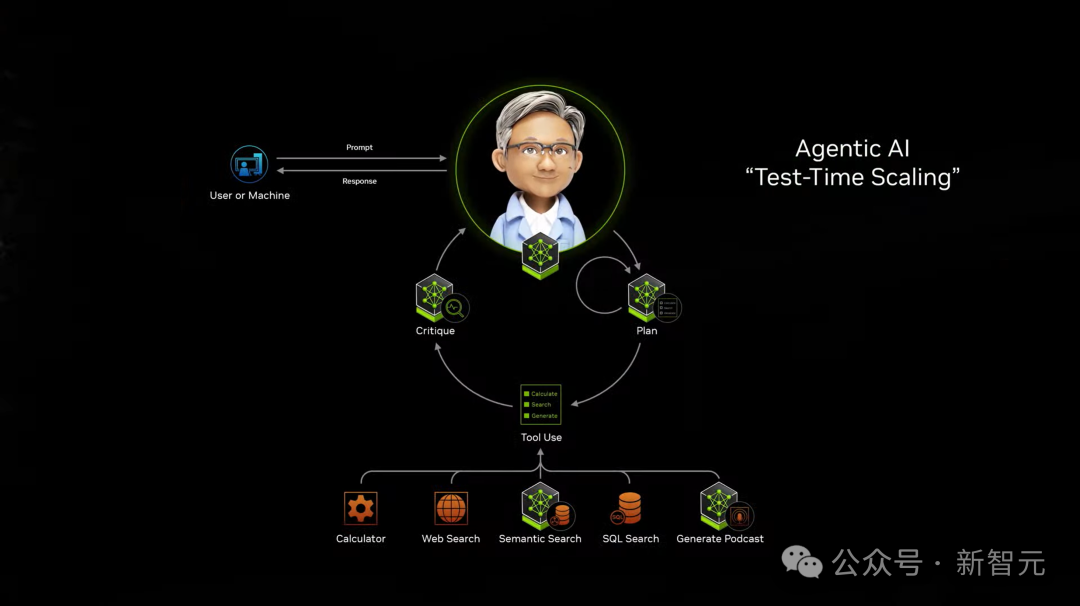

左右滑动查看
此外,英伟达NIM Blueprint即将在PC上线,借助这些蓝图,开发者能够基于 PDF 文档创建播客、生成由 3D 场景引导的令人惊艳的图像等。


左右滑动查看
桌面级AI超算,可跑4050亿LLM
CES大会收尾前,老黄还揭开了一款革命性的压轴产品——Project Digits,一台真正意义上“桌面超级计算机”!
它专为AI开发者、数据科学家、学生等,那些从事AI工作的专业人士而设计。

这款小型计算机是“全球最小”可运行200B参数模型的AI超级计算机,售价3000美金(约21986元)。
正如老黄所展示的那样,这款紧凑型台式系统提供强大算力的同时,仅占用了极小的桌面空间——
宽度大约相当于一个普通咖啡杯的长度,高度也仅有其一半左右。
想象一下,你的办公桌上放置一个微型设备,却能提供堪比数据中心级算力。
这就是Project Digits带来的革命性突破!
Project Digits搭载了全新的GB10 Grace Blackwell超级芯片,能在FP4计算精度下,提供高达1 PFLOPS(千万亿次浮点运算/秒)的AI性能。

这颗强大的芯片,还搭载了20个ARM核心的Grace CPU。CPU和GPU通过NVIDIA NVLink C2C技术实现高速互联。
每个Project Digits都配有128GB低功耗统一的高一致性内存,以及最高4TB的NVME存储。
有了它,开发者可以直接在桌面上,运行高达2000亿的大模型。
令人惊喜的是,通过ConnectX网络芯片,可以将2台Project Digits超级计算机互联,能够运行高达4050亿参数的模型。

此外,Project Digits预装了NVIDIA DGX基础操作系统(基于Ubuntu Linux)和NVIDIA AI软件栈,为开发者提供了一个开箱即用的AI开发环境。
开发者可以即插即用,快速启动AI项目的开发。
对于数百万开发者来说,它将成为一款改变游戏规则的创新产品。
尤其是,Project Digits特别适合处理,需要依赖云计算/数据中心资源才能运行的AI大模型。
这款桌面AI超算应用场景非常广泛,AI模型实验和原型开发、AI模型微调和推理(用于模型测试或评估),以及本地AI推理服务(如聊天机器人或代码智能助手)。
此外,数据科学家还以利用系统运行NVIDIA RAPIDS,直接在桌面就能高效处理大规模数据科学工作流。

有了英伟达AI完整技术栈的加持(框架、工具、API),Project Digits成为了边缘计算应用的理想开发平台,特别适用于机器人技术、VLM等领域。
Project Digits的出世,标志着个人AI计算进入了一个全新的时代。
它能让全世界开发者能够在自己的办公桌上,运行超大规模的AI模型,补充了现有的云计算资源,极大地提升了AI开发效率。
物理AI新纪元,世界基础模型全开源
智能体AI之后,老黄又将话题引到了“物理AI”。在他看来,“AI的下一个前沿就是物理AI”。
大模型的工作原理是,根据提示一次生成一个token产生输出。
如果这个上下文变成了现实周围环境,如果提示问题变成了请求,大模型需要从生成“内容token”转变为生成“动作token”。
而现在,我们需要做的是创建有效的“世界模型”,而不再是GPT系语言模型。

这个“世界模型”必须理解世界的语言,必须理解物理动力学,比如重力、摩擦,必须理解几何和空间关系,理解因果关系,理解物理永恒性......
CES现场,老黄官宣了革命性世界基础模型开发平台——Cosmos,旨在理解物理世界。
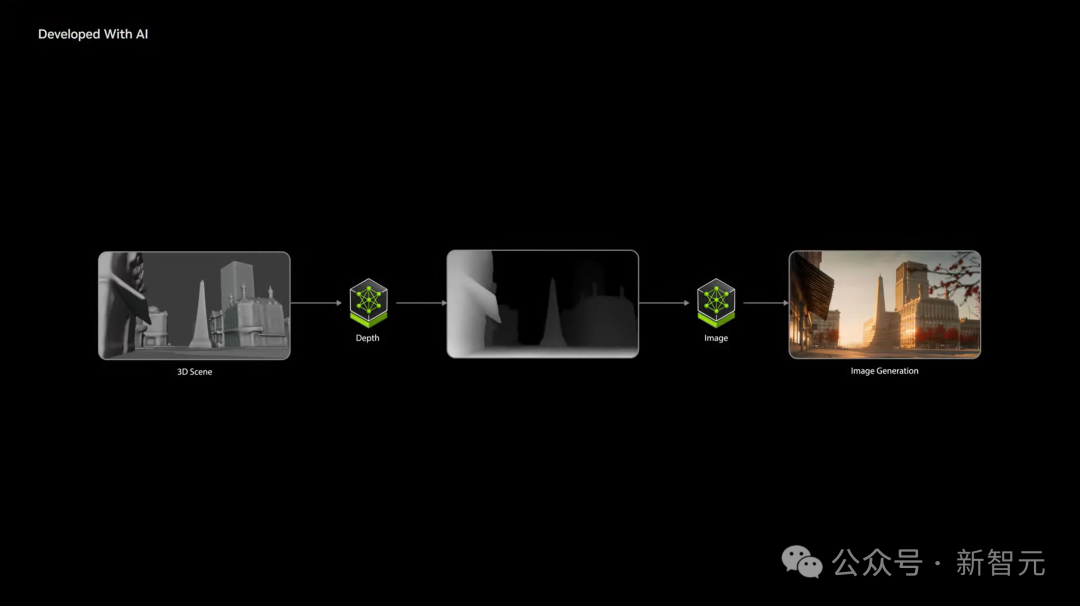
它基于2000万小时数据集完成训练,能够将文本、图像、视频作为输入,可以生成虚拟世界状态、视频。
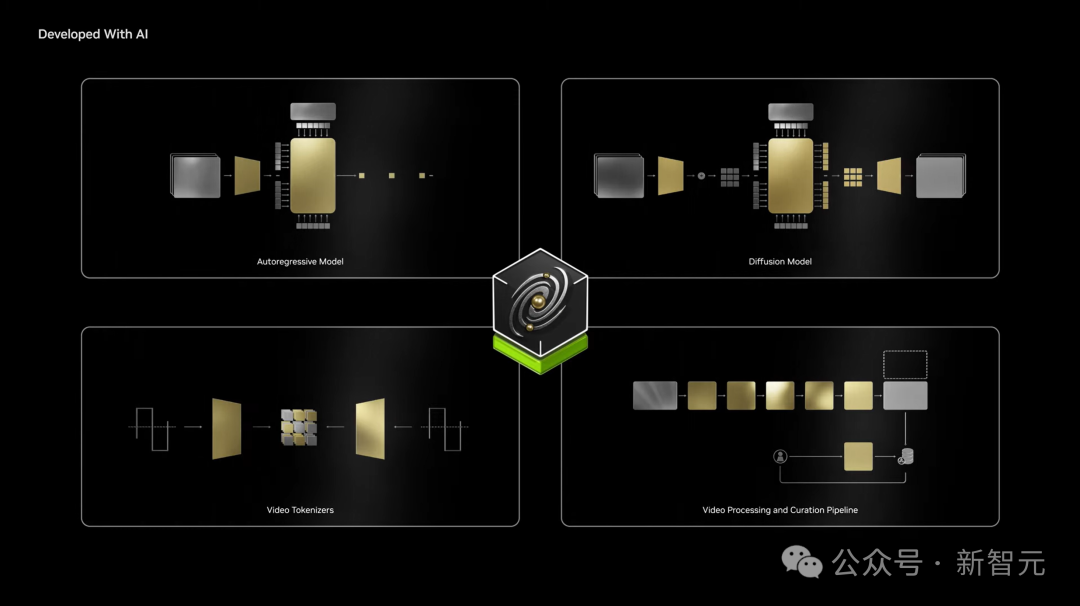
该平台包含多个功能模块,比如扩散模型、自回归模型、视频分词器,开发者可以根据具体需求选择使用。
值得一提的是,老黄现场直接将Cosoms全部开源,Nano、Super、Ultra全部公开可下载。
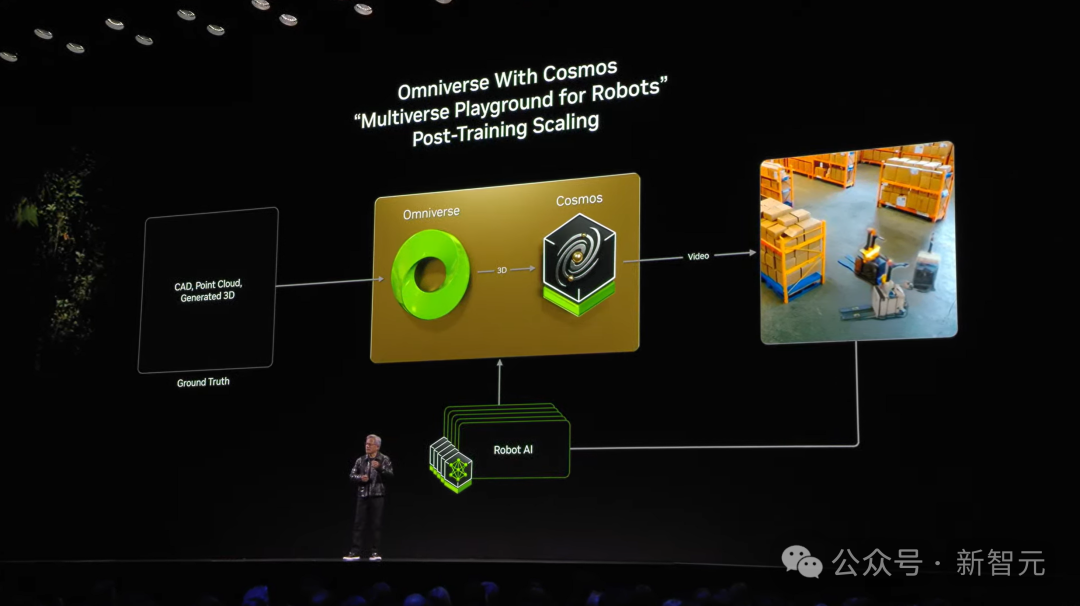
此外,Cosoms还能与Omniverse两者结合使用,能够提供一个物理真实的多元生成器。
也就意味着,物理模拟世界的一切,都可以通过Cosoms一次性生成出来。
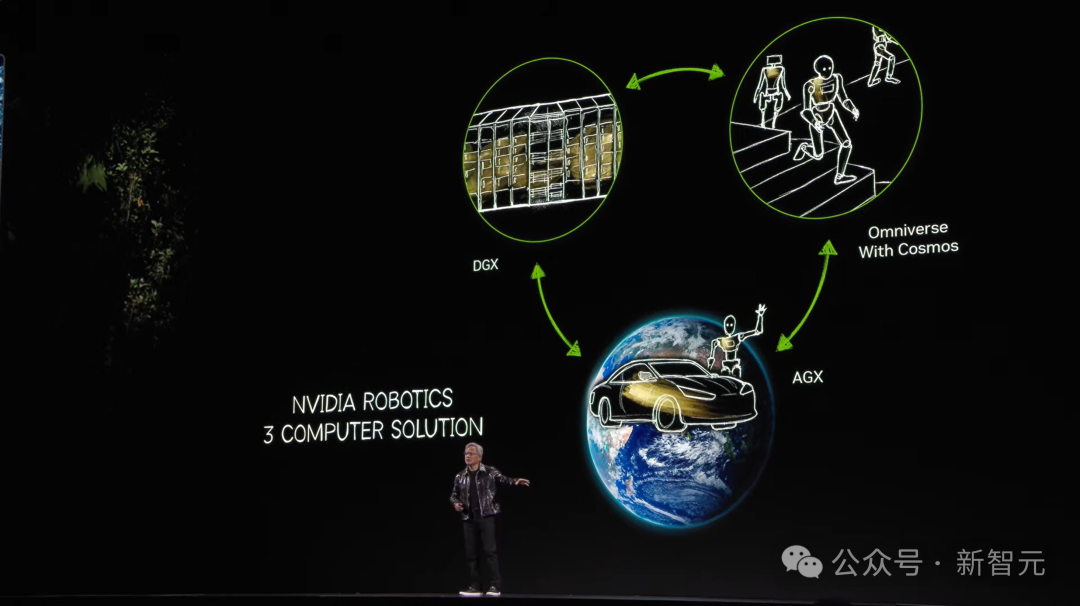
老黄还提到了三台计算机——一台DGX用来训练AI,另一台AGX用来部署AI,最后一台便是Omniverse+Cosmos。
若是连接前两者,我们就需要一个数字孪生。
老黄认为,“未来,每一个工厂都有数字孪生,你可以将Omniverse 和Cosoms结合,生成一大堆未来场景”。
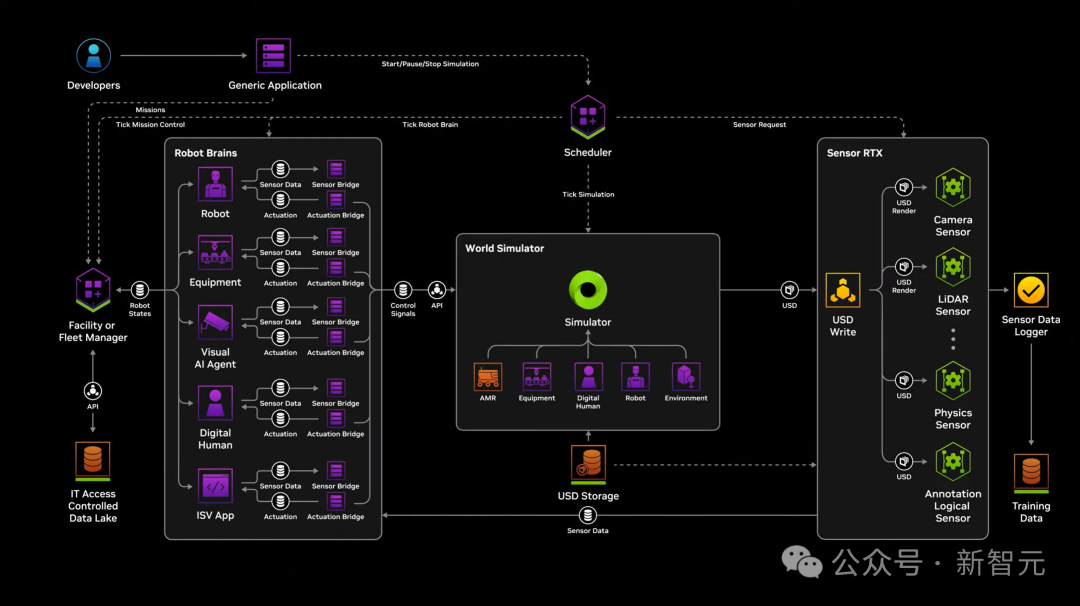
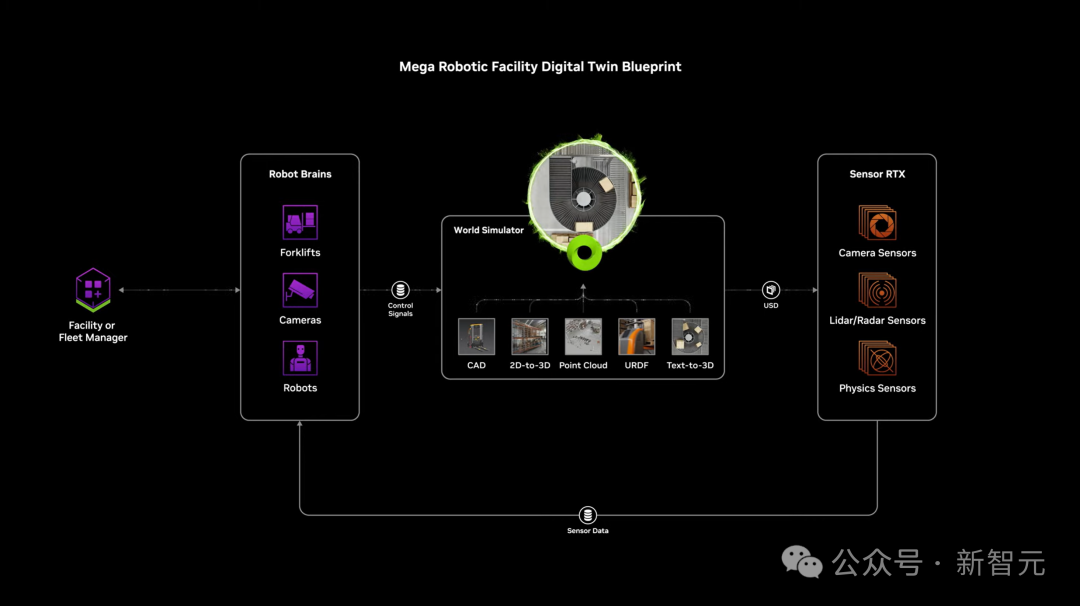


左右滑动查看
自动驾驶汽车+机器人
制造自动驾驶汽车,就像机器人一样,同样需要这三台计算机。
截至目前,每年生产1亿辆车,全球有数十亿辆车,都将在未来逐步变成高度自动化、完全自动化驾驶系统。
老黄预测道,这将会成为首个价值数万亿美金的机器人产业。
同时,他发布了下一代汽车处理器——Thor,处理性能比上一代Orin飙升20倍,而且也是通用机器人处理器。
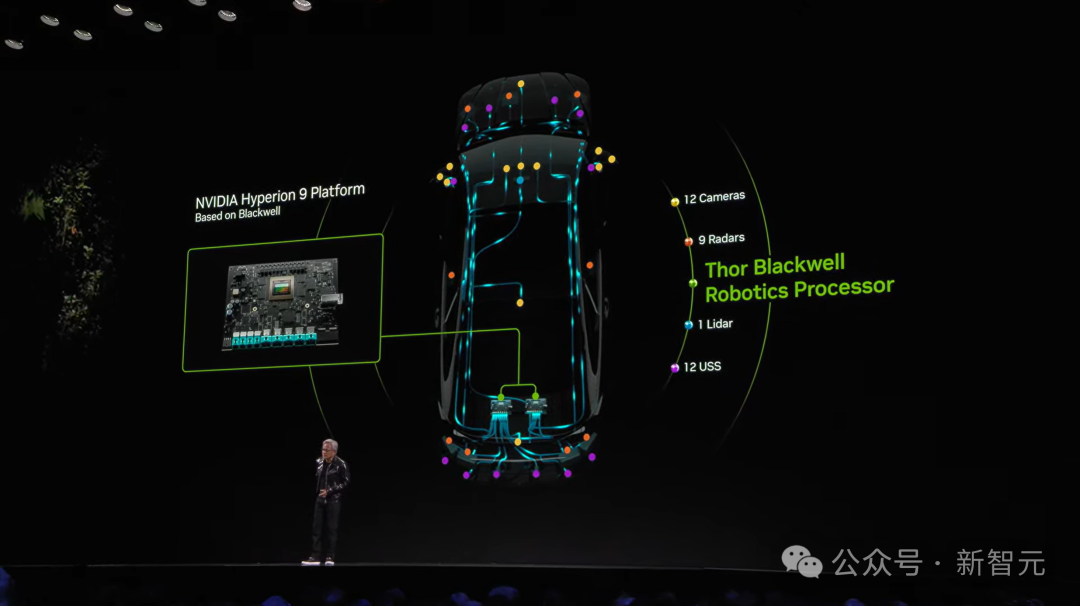

那么,在自动驾驶背景下,Omniverse+Cosoms能做什么?
它能够生成无限驾驶场景,加速短尾、无法收集数据等场景的自动驾驶的研发。
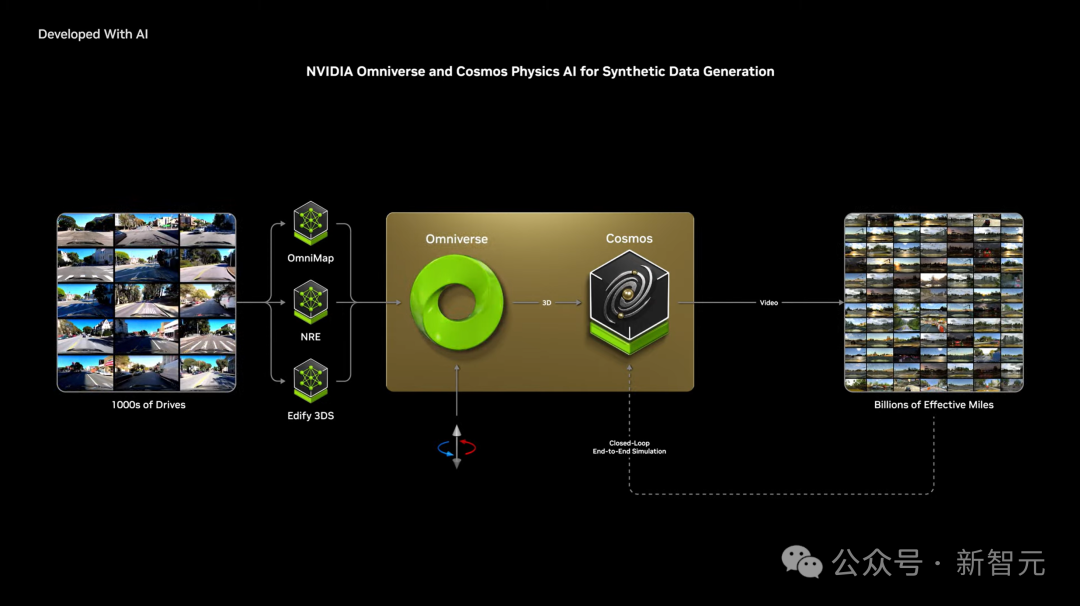
接下来,老黄召唤出所有机器人登台,并表示“通用机器人的ChatGPT时刻到来”。
他称,“目前有三种机器人——智能体AI、自动驾驶汽车、机器。如果我们拥有解决这三个问题技术,机器人时代就在眼前”。
在发布会最后的最后,老黄总结道,我们现在共有三台全新Blackwell系统正在生产中。
除了Grace Blackwell NVLink72超算,还有一个是物理AI基础模型,另一个是在智能体AI上研发的三类机器人。

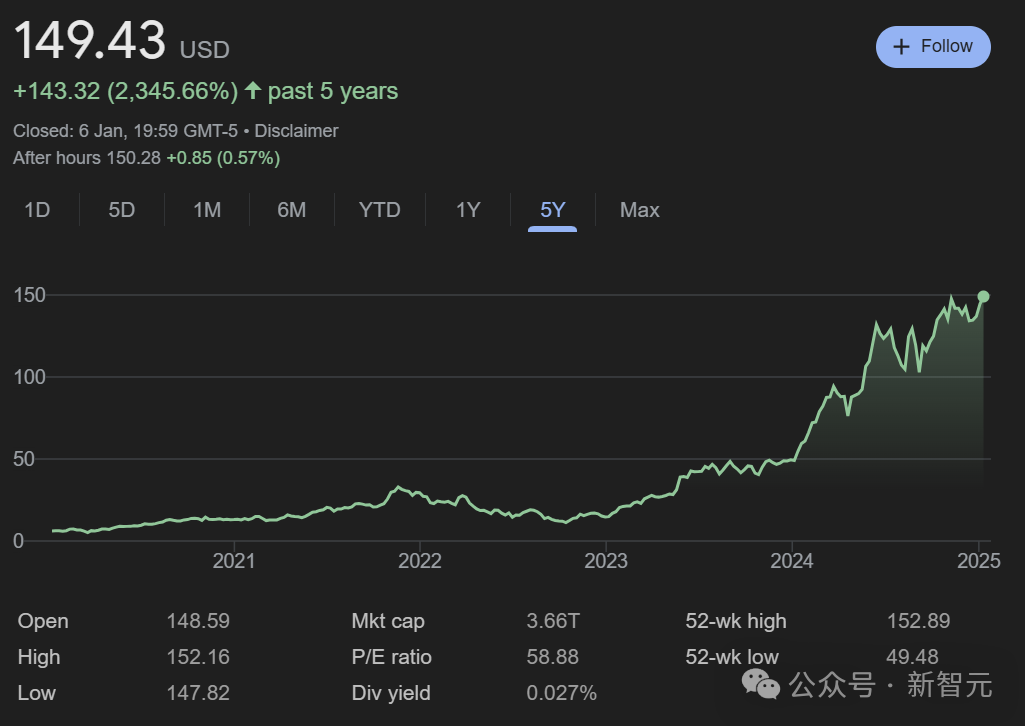
而就在刚刚,英伟达股价再次创下历史新高。
一夜间,英伟达股价大涨超3%,以每股超150美元的价格收盘,超过11月创下的每股148.88历史最高收盘纪录。
现在,如今,英伟达的最新估值已经达到了3.66万亿美元。