DeepSeek如何弯道大超车:震撼硅谷巨头 击溃出口管制
“当我们所有人都在过圣诞的时候,一个中国实验室却发布了震撼世界的AI模型。这显然具有象征意义。长期以来,美国都在AI竞争中处于全球领先地位,但DeepSeek的最新模型却在改变这一格局。” Scale AI的创始人兼CEO亚历山大·王(Alexandr Wang)在接受美国媒体采访时这样感慨。

短短半个月时间,一款中国实验室发布的AI模型就用令人难以置信的实力数据,震撼了整个硅谷AI领域。从科技巨头到AI新贵再到技术专家,几乎所有人都感受到了来自中国AI行业的强烈冲击。更令人震惊的是,中国AI行业在遭受出口管制和算力匮乏情况下,实现了弯道超车。
横空出世空降登顶
这个实验室就是来自中国的DeepSeek,2023年刚刚创建。他们在去年年底发布了一个免费开源的大语言模型。根据该公司发表的论文,DeepSeek-R1在多个数学和推理基准测试中超越了行业领先的OpenAI o1等模型,更在性能、成本、开放性等指标方面压倒了美国AI巨头。
科技行业需要用数据说话。在一系列第三方基准测试中,DeepSeek的模型在从复杂问题解决到数学和编程等多个领域的准确性上,超越了Meta的Llama 3.1、OpenAI的GPT-4o以及Anthropic的Claude Sonnet 3.5。
就在上周,DeepSeek又发布了推理模型R1,同样在诸多第三方测试中超越了OpenAI最新的o1。在AIME 2024数学基准测试中,DeepSeek R1取得了79.8%的成功率,超过了OpenAI的o1推理模型。在标准化编码测试中,它展示了“专家级”的表现,在Codeforces上获得了2,029的Elo评分,超过了96.3%的人类竞争对手。
Scale AI则使用了“人类最后考试”(Humanity’s Last Exam)来测试AI大模型,它采用来自数学、物理、生物、化学教授提供的“最难问题”,涉及最新的研究成果。在测试了所有最新的AI模型后,亚历山大·王不得不赞叹,DeepSeek的最新模型“实际上是表现最出色的,或者至少与o1等最好的美国模型不相上下”。
毫不夸张地说,DeepSeek在美国AI行业引发了一场地震,更引发了媒体的争相报道。几乎所有的主流媒体和科技媒体,都报道了中国AI模型超过美国这一爆炸新闻。短短几天时间,DeepSeek就已经成为苹果应用商店排名第一的免费应用,力压OpenAI的ChatGPT。
性能成本震撼巨头
实打实的测试对比结果,不得不服。几乎所有的AI巨头、风投和技术人员都只能承认,在大模型这个领域,DeepSeek至少已经可以和OpenAI平起平坐,中国已经追上了美国。
微软首席执行官萨蒂亚·纳德拉(Satya Nadella)在世界经济论坛上谈到DeepSeek时表示:“DeepSeek的新模型令人印象深刻,他们不仅有效地构建了一个开源模型,能够在推理计算时高效运行,而且在计算效率方面表现出色。我们必须非常非常认真地对待中国的AI进步。”
中国AI不仅是性能卓越,更是经济实惠。让硅谷诸多AI巨头感到震撼和汗颜的是DeepSeek的低廉成本。R1模型的查询成本仅为每百万个token 0.14美元,而OpenAI的成本为7.50美元,使其成本降低了98%。
真的是小米加步枪,DeepSeek仅仅用了两个月时间,耗费了不到600万美元就打造了大语言模型R1,而且他们用的还是性能较弱的英伟达H800芯片。这意味着什么?打个比方,中国AI公司居然开着普通轿车,就实现了弯道超车,在竞赛中超越了硅谷巨头们的超级跑车。
除了训练成本低廉,DeepSeek的团队组成也与硅谷诸多AI巨头大相径庭。DeepSeek创始人梁文峰在组建研究团队时,并未寻找经验丰富的资深软件工程师,而是专注于来自北大、清华等顶级高校的博士生。许多人曾在顶级学术期刊发表论文,并在国际学术会议上获奖,但缺乏行业经验。
“我们的核心技术岗位主要由今年或过去一两年毕业的人员担任,”梁文峰在2023年接受媒体采访时表示。这种招聘策略有助于营造一个自由协作的公司文化,研究人员可以利用充足的计算资源来开展不拘一格的研究项目。这与中国传统互联网公司形成鲜明对比,在后者中,团队通常为资源争斗激烈。
没有囤积顶级GPU,没有招揽资深AI人才,没有高昂的运行成本,一样可以拿出最佳的大模型,DeepSeek的一切都让硅谷AI巨头们感到沮丧。
硅谷巨头陷入沮丧
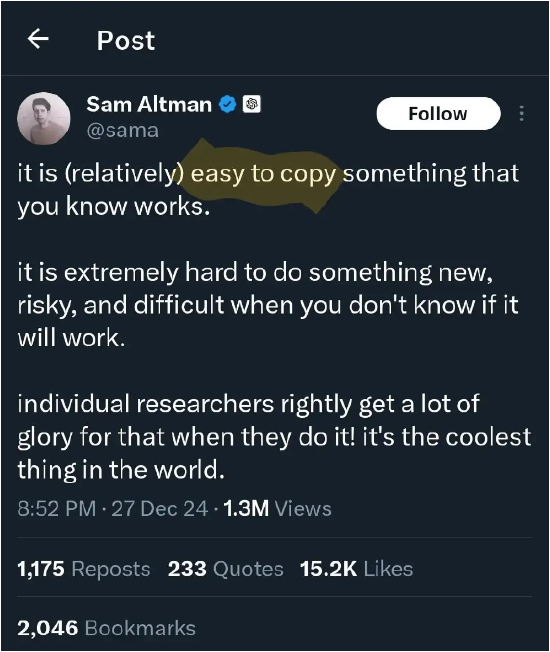
被挑战的巨头们是怎么看待DeepSeek呢?OpenAI创始人兼CEO奥特曼(Sam Altman)的表态让人感觉有点酸。他在社交媒体上表示:“复制已知有效的方案相对容易,但探索未知领域则充满挑战。” 这一言论被广泛解读为对DeepSeek的暗讽,暗示中国AI模型缺乏真正的创新,仅仅是在复制现有的有效方法。
Perplexity AI的CEO斯林尼瓦斯(Arvind Srinivas,印度人)从市场影响的角度来看待这一发布:“DeepSeek在很大程度上复制了OpenAI o1 mini并开源了它。”但他也赞叹了DeepSeek的快速步伐:“看到推理如此迅速地商品化,这有点疯狂。”他表示,自己的团队会将DeepSeek R1的推理能力引入Perplexity Pro。
Stability AI的创始人Emad Mostaque暗示DeepSeek的发布给资金更充裕的竞争对手带来了压力:“你能想象一个筹集了10亿美元的前沿实验室现在无法发布其最新模型,因为它无法击败DeepSeek吗?”
Meta AI首席科学家杨立昆(Yann LeCun,法国人)则强调中国人是依靠开源的优势取得成功。他在对DeepSeek的成功表示赞赏的同时强调,DeepSeek的成功并非意味着中国在AI领域超越美国,而是证明了开源模型正在超越闭源系统。
杨立昆表示,DeepSeek从开源研究和开源代码中受益匪浅,他们提出了新想法,并在他人工作的基础上进行创新。由于他们的工作是公开和开源的,所有人都能从中获益。这体现了开源研究和开源代码的力量。 他认为,DeepSeek的成功提现开源生态系统在推动AI技术进步中的重要性,表明通过共享和协作,开源模型能够实现快速创新和发展。

但Meta内部可没有这么淡定。过去几天,职场匿名平台teamblind上有一个来自Meta员工的贴子被疯传。帖子称Meta内部因为DeepSeek的模型,现在已经进入恐慌模式,不仅是因为DeepSeek的优秀表现,更是因为极低的成本和团队组成。
“一切都因为DeepSeek-V3的出世,它在基准测试中已经让Llama 4相形见绌。更让人难堪的是,一家中国公司仅用550万美元训练预算就做到了这一点。现在Meta的工程师们正在争分夺秒地分析DeepSeek,试图复制其中的一切可能技术。这绝非夸张。而且,管理层正为GenAI研发部门的巨额投入而发愁。当部门里一个高管的薪资就超过训练整个DeepSeek V3的成本,而且这样的高管还有数十位,他们该如何向高层交代?
高效算法弯道超车
那么,DeepSeek究竟是怎样实现弯道超车,在算力明显落后,成本只是零头的情况下,打造出可以媲美甚至超越硅谷AI巨头的大模型呢?
美国的出口管制严重限制了中国科技公司以“西方式”的方法参与人工智能竞争,即通过无限扩展芯片采购并延长训练时间。因此,大多数中国公司将重点放在下游应用,而非自主构建模型。但DeepSeek的最新发布证明,获胜的另一条道路是:通过重塑AI模型的基础结构,并更高效地利用有限资源。
因为算力资源不足,DeepSeek不得不开发更高效的训练方法。“他们通过一系列工程技术优化了模型架构——包括定制化芯片间通信方案、减少字段大小以节省内存,以及创新性地使用专家混合模型(Mixture-of-Experts)方法,”Mercator研究所的软件工程师温迪·张(Wendy Chang)表示。“许多这些方法并非新鲜,但成功地将它们整合以生产尖端模型是相当了不起的成就。”
DeepSeek还在“多头潜在注意力”(Multi-head Latent Attention,MLA)和“专家混合模型”方面取得了重大进展,这些技术设计使DeepSeek的模型更具成本效益,训练所需的计算资源远少于竞争对手。事实上,据研究机构Epoch AI称,DeepSeek的最新模型仅使用了Meta Llama 3.1模型十分之一的计算资源。
中国AI研究人员实现了许多人认为遥不可及的成就:一个免费、开源的AI模型,其性能可以媲美甚至超越OpenAI最先进的推理系统。更令人瞩目的是他们的实现方式:让AI通过试错自我学习,类似于人类的学习方式。
研究论文中写道:“DeepSeek-R1-Zero是一个通过大规模强化学习(RL)训练的模型,无需监督微调(SFT)作为初步步骤,展示了卓越的推理能力。”
“强化学习”是一种方法,模型在做出正确决策时获得奖励,做出错误决策时受到惩罚,而无需知道哪个是哪个。经过一系列决策后,它会学会遵循由这些结果强化的路径。
DeepSeek R1是AI发展的一个转折点,因为人类在训练中的参与最少。与其他在大量监督数据上训练的模型不同,DeepSeek R1主要通过机械强化学习进行学习——本质上是通过实验和获得反馈来解决问题。该模型甚至在没有明确编程的情况下,发展出了自我验证和反思等复杂能力。
随着模型经历训练过程,它自然学会了为复杂问题分配更多的“思考时间”,并发展出捕捉自身错误的能力。研究人员强调了一个“顿悟时刻”,模型学会了重新评估其最初的问题解决方法——这是它没有被明确编程去做的事情。
开源模型广获赞赏
值得一提的是,DeepSeek愿意将其创新成果开源,使其在全球AI研究社区中获得了更大的赞赏。 与专有模型不同,DeepSeek R1的代码和训练方法在MIT许可证下完全开源,这意味着任何人都可以获取、使用和修改该模型,没有任何限制。
对许多中国AI公司来说,开发开源模型是赶超西方竞争对手的唯一方式,因为这样可以吸引更多用户和贡献者,帮助模型不断成长。在OpenAI逐渐封闭化的当下,DeepSeek的开源得到了AI从业人员的交口称赞。
英伟达资深研究员樊锦(Jim Fan)博士赞扬了DeepSeek前所未有的透明度,并直接将其与OpenAI的原始使命相提并论。“我们生活在一个非美国公司保持OpenAI原始使命的时间线上——真正开放的、前沿的研究,赋能所有人,”樊锦指出。
樊锦指出了DeepSeek强化学习方法的重要性:“他们可能是第一个展示[强化学习]飞轮持续增长的开源软件项目。”他还赞扬了DeepSeek直接分享“原始算法和matplotlib学习曲线”,而不是行业中更常见的炒作驱动公告。
遵循同样的推理,但带有更严肃的论证,科技企业家Arnaud Bertrand解释说,竞争性开源模型的出现可能对OpenAI冲击巨大,因为这会使OpenAI模型对付费意愿强烈的高级用户的吸引力降低,从而损害OpenAI的商业模式。“这基本上就像有人发布了一款与iPhone相当的手机,但售价为30美元而不是1000美元。这是戏剧性的。”
出口管制面临挑战
这对英伟达来说,DeepSeek的横空出世是一个利空因素。很多AI行业人士不禁开始思考另一个问题:既然DeepSeek用上一代芯片的阉割版就可以训练出最强劲的大模型,那么科技巨头们还需要继续疯狂烧钱抢购英伟达的最新GPU吗?这个问题细思极恐。
众所周知,因为美国政府的AI芯片禁运,中国无法采购英伟达最高性能的AI芯片,而H800则是高算力A100芯片的阉割版。与A100相比,H800的核心数量、频率和显存方面明显较低,算力上降幅大约在10-30%之间,主要不需要顶级算力的场景,例如中等规模的AI训练与推理任务。H800的内存带宽被限制在 1.5 TB/s,而A100 80GB版本可达到 2 TB/s,这将直接影响数据处理能力,尤其在深度学习任务中。
Scale AI的亚历山大·王坚持认为,DeepSeek的芯片数量可能远远高于外界想象。他公开表示,自己认为DeepSeek至少拥有5万块H100,他们不会公布具体数字。
H100的算力是A100的六到七倍,这款3万美元起售的顶级GPU也是目前硅谷科技巨头们争先抢购的军火。Meta和微软都超过采购了15万块H100,Google、甲骨文和亚马逊都采购了5万块,马斯克的xAI更部署了10万块H100组成的超级计算机集群用于训练大预言模型Grok3。
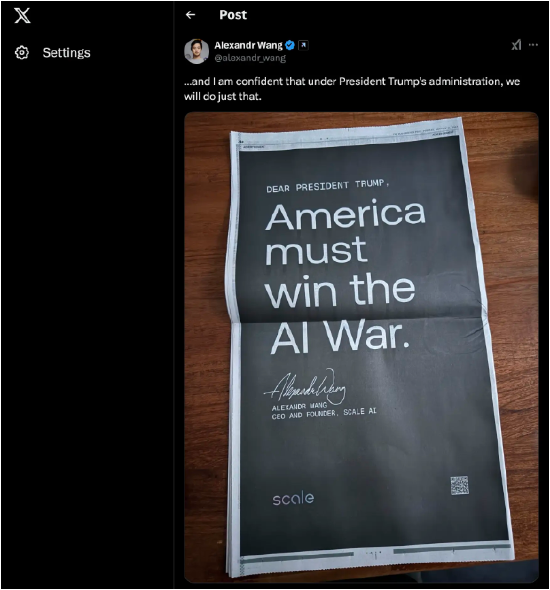
亚历山大·王进一步表示,未来中国AI行业可能会面临更多挑战,“未来他们将受到我们已经实施的芯片和出口管制的限制,难以再获取更多芯片。”他上周在《华盛顿邮报》购买了整版广告,写道“美国必须赢下这场AI战争!”