GPT-5惨遭零分打脸 顶级AI全军覆没 奥特曼AI博士级能力神话破灭
奥特曼在GPT-5的发布会上曾说过一个结论。“以后每个人的兜里都有一个博士级AI随时随地的提供建议”。GPT-5的发布后也被全球的疯狂实测,API使用量暴增。当然,有些讨论重点关注的是“还我GPT-4o”这种情绪化的能力方面。
但重点是,奥特曼一直强调,GPT-5有“博士级”推理能力。这事儿,真的靠谱吗?
这不,一个叫FormulaOne的硬核测试,就让世界上这些最顶级的模型“现了原形”。
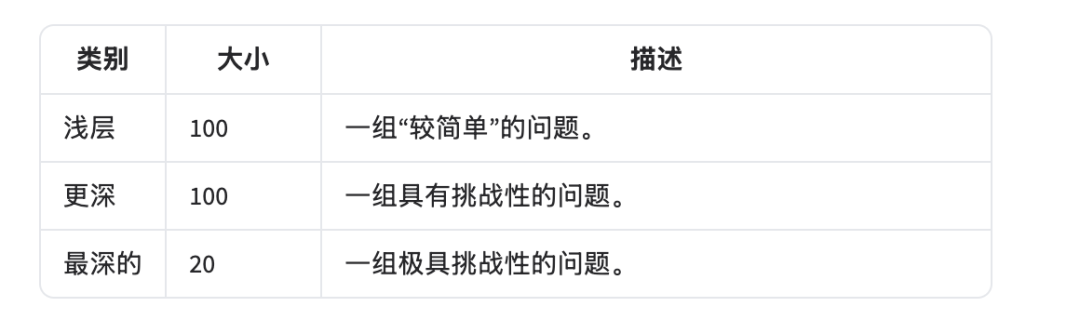
FormulaOne题目分三关,一关比一关难。

论文地址:https://arxiv.org/pdf/2507.13337
结果呢?有点扎心了。
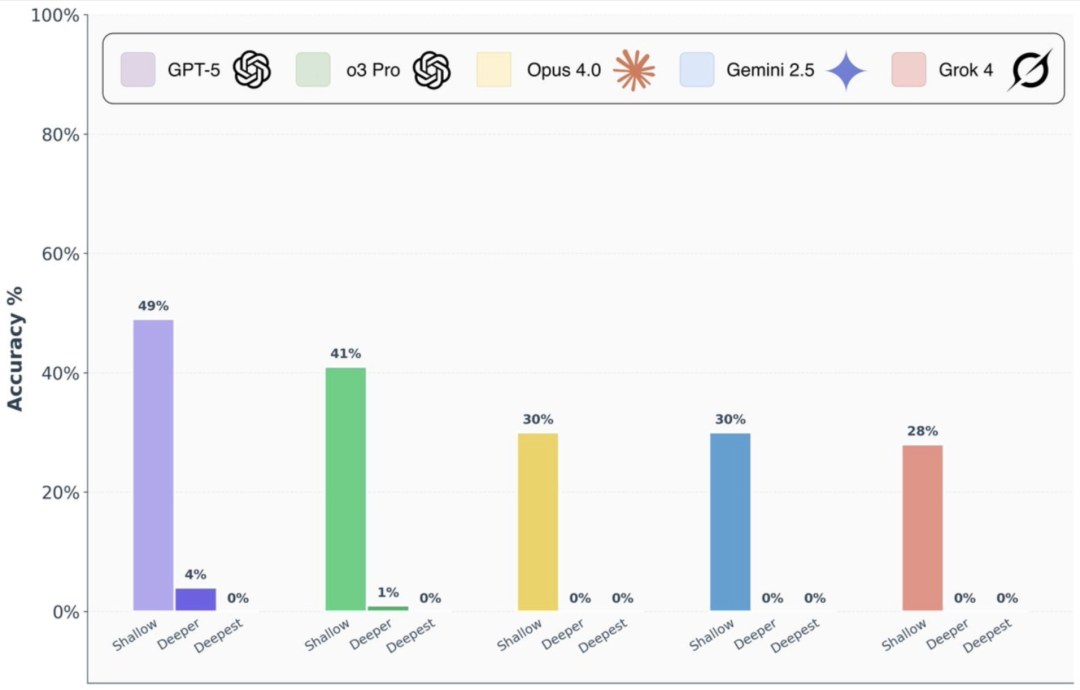
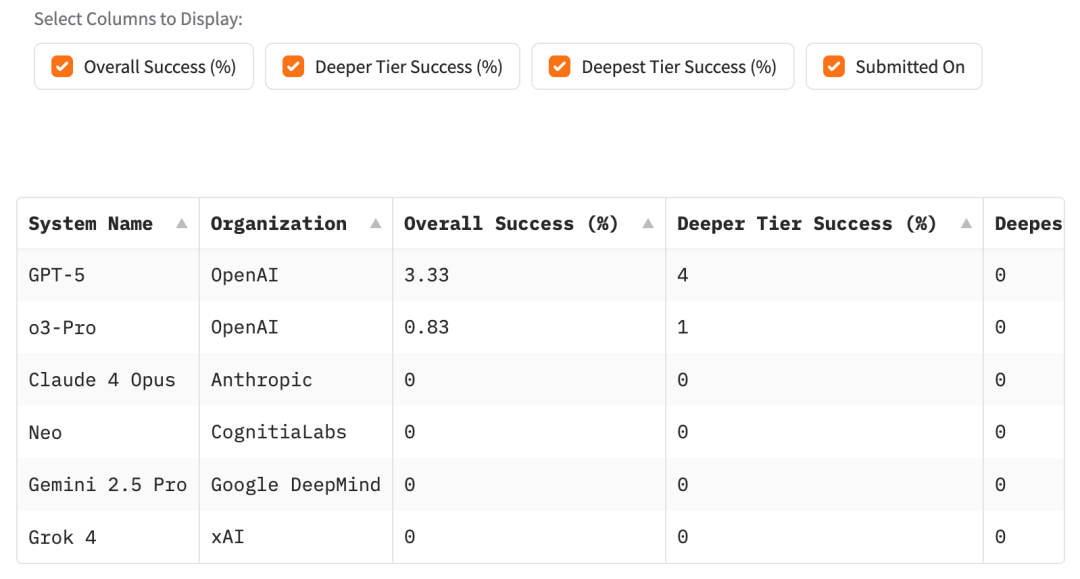
基础题,AI们还算顶得住,正确率还可以,唯一一个GPT-5能接近50%。
可到了进阶题,画风突变。
就算是GPT-5,也只做对了4%。其他模型更是惨不忍睹。
至于最难的“最深层问题”部分?所有模型,全军覆没。直接交了白卷,全部零分。
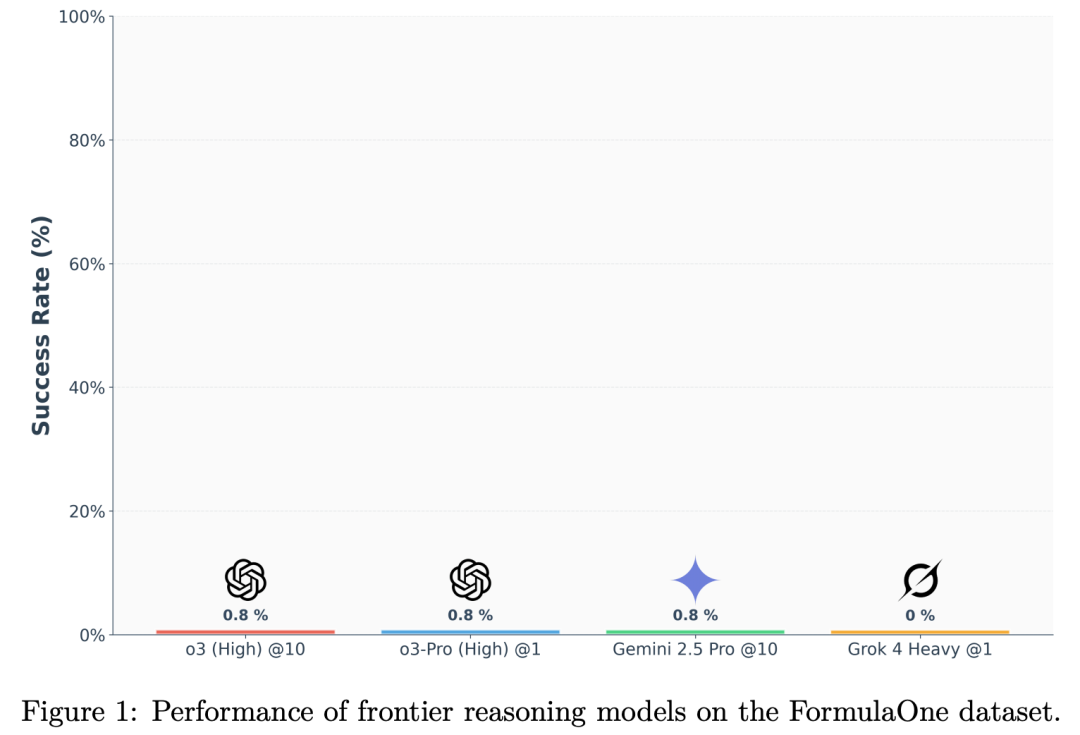
FormulaOne测试基准给自己取名字叫做:超越竞赛编程的算法推理深度测量。
这是由一家名为AAI的公司出品的,他们的官网是:doubleai.com。

公司是由Mobileye联合创始人、希伯来大学教授Amnon Shashua发起的科研向AI创业公司,2023年8月在耶路撒冷成立,长期“半隐身”。

Amnon Shashua曾于2020年荣获丹·大卫奖(Dan David Prize)人工智能领域的获奖者,并于2022年被汽车名人堂(Automotive Hall of Fame)评为移动创新者。
1999年,Shashua联合创立了Mobileye,该公司于2014年成为以色列历史上规模最大的IPO。
2017年,公司被Intel以153亿美元收购。
2022年,公司再次于纳斯达克证券交易所上市。
AI必须硬核
现在的AI离真正的专家,到底还有多远?
真正的专家,那可是要解决硬核难题的,他们是推动科学边界的人。
所以,得给AI上点真正的强度了。
目前的基准测试往往无法完整描绘出人工智能理解的深度。
尽管最近取得了一些显著成就,例如OpenAI在CodeForces上获得了2724的评分,或是在国际信息学奥林匹克竞赛中获得金牌。
但这些成绩仍然掩盖了一个令人清醒的现实:为这些竞赛磨炼出的技能,并不能涵盖解决大规模现实世界研究问题所需的全部推理能力。
例如优化全球供应链、管理大规模电网、设计具有弹性的网络基础设施等任务要困难多个数量级,它们所需的算法洞察力远远超出了典型竞技编程的范畴。
FormulaOne包含220个新颖的、基于图的动态编程问题。这些问题分为三个类别,从适中的难度到研究级别的难度不等。
FormulaOne是一个处于图论、逻辑和算法交叉点的基准测试,完全在前沿模型的训练分布范围内。
这些问题极具挑战性,需要一系列推理步骤,涉及拓扑和几何洞察、数学知识、组合考虑、精确实现等。
FormulaOne具有三个关键特性。
第一,它具有商业价值,与实际的大规模优化问题相关,例如路径规划、调度和网络设计中出现的问题。
第二,它生成自图上的单一二阶(Monadic Second-Order,MSO)逻辑这一高度表达的框架,为大规模自动问题生成铺平了道路——非常适合构建强化学习(RL)环境。
第三,许多问题与理论计算机科学的前沿以及其中的核心猜想密切相关,例如强指数时间假设(Strong Exponential Time Hypothesis,SETH)。
为什么模型在“deepest”(最深层)任务上会出现概念崩溃,即使它们在算法编程竞赛中达到了超越人类顶尖选手的水平?
“deepest”层级的问题需要非常深入的推理能力,而这是现有模型根本无法做到的。
FormulaOne可能需要一种定性不同的方法,正通过一个实时排行榜和评估框架与社区分享它。
FormulaOne中的问题都很简洁,仅由一两句话组成,任何本科生都能理解,但解决这些问题却需要创造力和深入的推理。



虽然这些问题通常很容易描述,但它们的解决方案远非显而易见。这一大类问题的可解性由一个Courcelle提出的算法元定理所保证,该定理大致表述为:
对于每个足够树状的图,任何可在一种表达能力强的形式逻辑——单子二阶(MSO)逻辑中定义的问题,都可以通过一个动态规划算法来求解,该算法的运行时间与图的阶数成线性关系。
FormulaOne中的问题源自一个单一的无限族:图上的单阶二阶(MSO)逻辑。
简单来说,这些问题就是图上的自然动态规划问题。
虽然许多问题在一般情况下是NP难的,但在“树状”图上它们变得易于处理。
在这种情况下,这些问题可以通过一种线性时间的动态规划算法来解决——该算法在一个称为“bags”的小图窗口上进行操作。
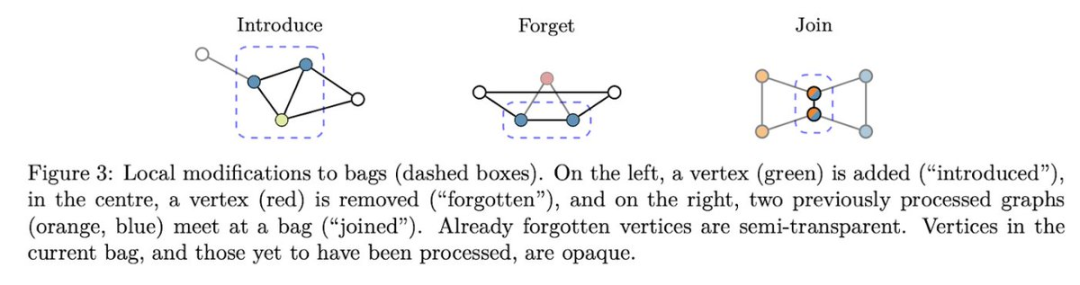
“包”是使用一种称为树分解的结构,它将图的顶点组织成一系列重叠的集合,这些集合本身以树的形式排列。
然后,算法可以遍历这个包(bag)树,使用动态规划逐块解决该问题。
此过程包括设计一个“状态”,用以概括包中部分解决方案的所有必要信息,并定义当顶点被引入、遗忘或包被合并时,该状态如何转换。
“最深层”级别问题难在哪里
那么,是什么让“最深层”级别的难度远高于“浅层”级别呢?换句话说,如何解释前沿模型在这些问题上的崩溃?
是因为数据不足吗?还是因为在动态规划方面的专业知识水平较低?
不,前沿模型最近在算法编程竞赛和奥林匹克竞赛中已经达到了顶尖人类水平,而动态规划(DP)正是这类竞赛中的关键技术之一。
相反,像CodeForces中的竞赛题目通常是这样构建的:一个人想出一个非常巧妙的技巧(或者可能两个),然后围绕这个技巧设计一个问题。
一旦参赛者理解了这个技巧,通常很快就能写出一个简短的解决方案。对于“浅层”阶段来说,情况某种程度上也是如此。
相比之下,现实世界的问题,以及“更深”和“最深”阶段的问题,通常涉及多个不确定的步骤,并且没有任何简单的捷径可循。
设计一个正确且高效的动态规划程序很难。
关键在于每个包所存储的信息——“状态”。
状态设计既是一门艺术,也是一门科学。
状态必须足够丰富,以便在我们从一个包过渡到下一个包时能够进行更新,但同时又必须足够简洁,以确保计算上的可行性。
模型倾向于急切地过度承诺;做出过早且不可逆的决策,而这些决策的无效性往往要到很久之后才会显现出来。
随着不确定性的增加,这种情况会变得更加明显。
事实上,这仅仅是模型所犯的一系列分类错误之一。
为了帮助理解模型的优势与不足,每个FormulaOne问题都由一系列标签进行标注,代表其核心思想。
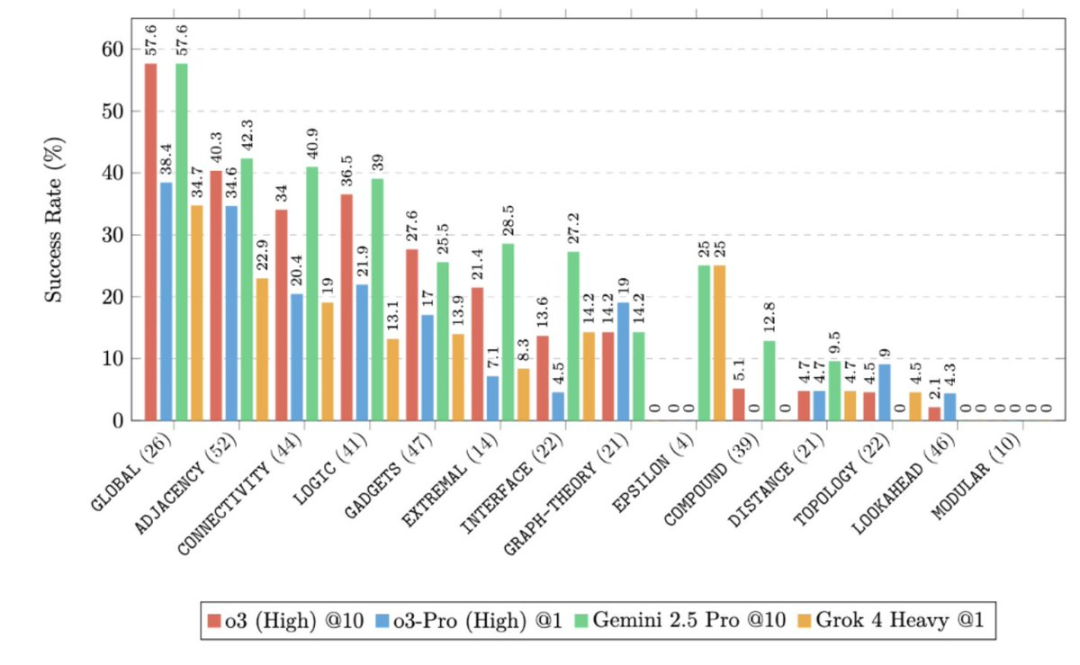
那么要突破这个新基准需要什么?
虽然GPT-5在“更深”层级上显示出一些进展迹象,但这种进展非常有限,而在“最深”层级上则完全没有进展。
这可能可以解释为一种“信号缺失”,因为在“最深”层级的问题中存在太多不确定点和需要做出的决策,要让所有这些都正确对齐变得异常困难——以至于传统的训练技术都失效了。