OpenAI推出适用于macOS的Codex智能编程应用
2 月 2 日,OpenAI 正式发布面向 MacOS 的全新 Codex 桌面应用,将过去一年间在业界流行的多代理“自主编程”(agentic coding)实践系统性地集成到本地开发工作流之中。 新应用主打多智能体并行协作、自动化任务调度以及可定制的代理人格,意在缩短从构想到可运行软件的整体开发周期。
过去一年,AI 在软件开发领域的影响迅速扩大,大量编程体力活正被由主代理与子代理组成的“代理群”所接管,开发者也在积极试验新的人机协作界面与工作形态。 在这一趋势下,主打自主编程体验的 Claude Code、Cowork 等应用率先占据了开发者心智,而 OpenAI 则一边推进 Codex 工具的形态演进,一边加紧追赶:Codex 去年 4 月先以命令行工具形式发布,一个月后扩展出 Web 界面。
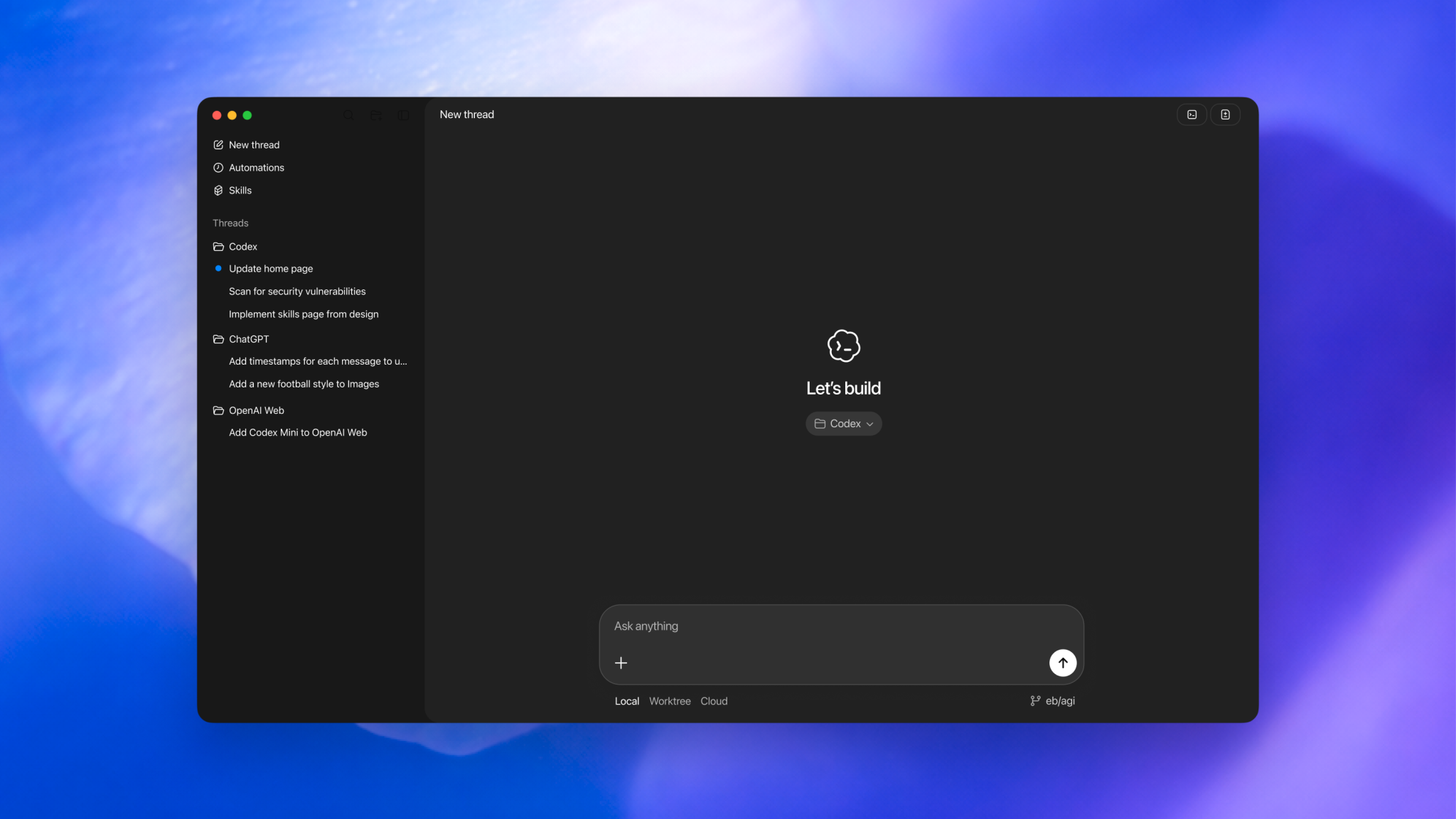
此次发布的 MacOS 应用,被视为 OpenAI 在“追平乃至超车”竞争对手道路上的关键一跃。 官方介绍称,新版 Codex App 针对多代理协同进行了深度优化,支持在本地同时运行多个代理,并整合了诸如 Agent Skills 等前沿工作流组件,以便开发者在同一界面内编排、调度不同专长的代理协同完成复杂任务。
新应用发布距离 GPT-5.2-Codex 模型上线还不到两个月,这也是 OpenAI 当前最强的代码生成与理解模型。 公司希望,结合更强大的底层模型与更灵活直观的桌面应用界面,有望吸引一部分目前使用 Claude Code 等竞品的开发者迁移到 Codex 生态。 OpenAI 首席执行官 Sam Altman 在媒体电话会上表示,如果要在复杂项目上开展高难度工作,“5.2 目前是实力最强的模型”,真正的挑战在于如何让这种能力以更易用的界面触达更多开发者。
不过,围绕 GPT-5.2 的性能优势,业内基准测试给出的图景更为复杂。 在针对命令行编程任务的 TerminalBench 榜单上,GPT-5.2 目前位居首位,但 Gemini 3 与 Claude Opus 等模型的得分与之相近,差距处在误差范围之内。 面向真实软件缺陷修复场景的 SWE-bench 测试也显示,各家头部模型整体表现接近,尚难得出 GPT-5.2 具有压倒性优势的结论。 另一方面,围绕多代理实际使用体验的场景,目前仍缺乏成熟的量化评估方法,不同模型在真实用户体感上的差异也难以用统一指标衡量。
在具体功能层面,OpenAI 强调,新版 Codex App 不仅是一个“更强模型的外壳”,还提供了一系列围绕效率与个性化设计的新特性。 用户可以在应用中配置后台自动化流程,让特定任务按预设时间表自动运行,并将结果汇总到队列中,方便开发者回到桌面时集中审阅与处理。 此外,应用还支持为代理选择不同的“人格”设定,例如偏重务实执行或更具同理心的互动风格,以适配不同开发者的工作偏好和沟通习惯。
对于这类工具带来的开发效率飞跃,Altman 给出了颇具野心的描述。 在他看来,借助新的 Codex App,开发者可以从一张白纸起步,在短短数小时内完成一款相当复杂的软件作品,真正的瓶颈已经从编程本身转移到人类“输入新想法的速度”上。 他表示,只要开发者能持续提出新需求与构想,系统就能够以相近的节奏把这些创意转化为可运行的功能模块。
在多代理自主编程迅速扩散的当下,MacOS 版 Codex 的推出意味着 OpenAI 正试图在桌面开发工具这一关键入口上重新卡位。 在模型实力差距缩小、基准测试难以拉开明显领先的背景下,谁能在产品形态和实际开发体验上占据优势,正成为新一轮 AI 编程竞赛的关键变量。