DeepSeek连夜改页面 免费的AI用不长了
4月8日凌晨,DeepSeek悄悄上线了一种新的分层模式界面:在网页版/App中出现了“快速模式(Fast)”和“专家模式(Expert)”两个入口,同时还有一个带图标的“视觉模式(Vision)”选项正在灰度测试。
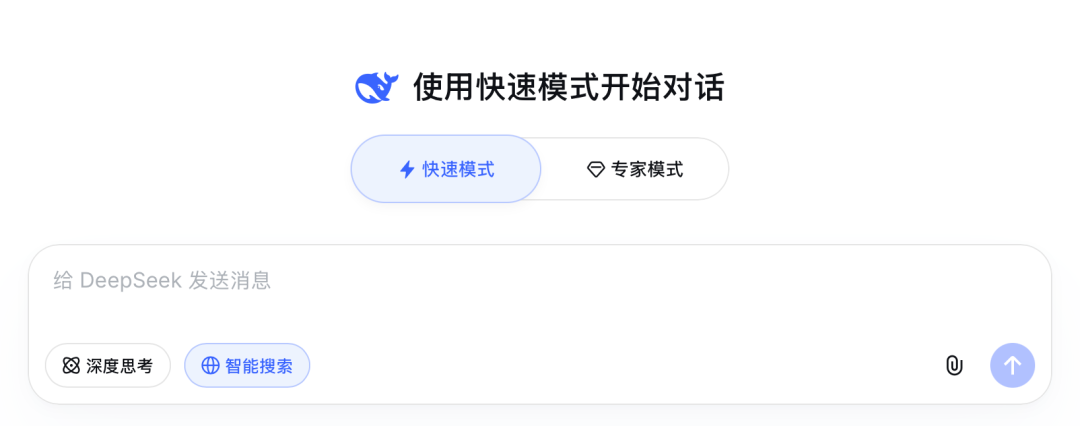
图|Deepseek网页版截图
新的功能分工十分明确:快速模式面向日常对话和低延迟响应;专家模式针对复杂推理和深度任务,可能触发更长推理时间但响应慢;而视觉模式则开启了图像输入等多模态能力,不过凤凰网科技检索发现,被灰度到视觉模式的人非常之少。
外界普遍认为,这是为即将发布的新一代V4模型做的功能和体验预热。但相比发新模型,当前的分级制度或许更值得关注,作为一种“按需调用算力”的调度机制,就是将简单任务交由低成本路径处理,仅在必要时启用高算力推理,从而减少无效Token消耗,实现整体成本的结构性下降。
大模型公司的算力焦虑
大概在一周前,Anthropic宣布自4月5日起,旗下大模型Claude的订阅服务将不再覆盖包括龙虾在内的第三方集成工具。用户如想继续使用该模型,只能通过与订阅服务分开计费的按需付费方案,并为此支付额外费用。
背后的逻辑非常好理解,随着黄仁勋在GTC大会上高呼Token经济学。全球科技大厂一时间把token消耗量变成了考核标准,更有国内的互联网大厂拉了月度token消耗排行,唯token消耗论甚嚣尘上。
据Anthropic表述,订阅制的定价模型原本是基于“个人用户正常使用强度”设计的,而OpenClaw这类自动化代理工具的使用强度远超预期——有重度用户每月仅支付200美元订阅费,却消耗了价值5000美元的算力资源,给Anthropic带来了巨大的成本压力。
小米AI负责人、前DeepSeek核心成员罗福莉对这个理念进行了拆解,认为Anthropic终于走出了天坑。其在社交平台X上发布长文,认为全球算力供给已经跟不上Agent创造的token需求增速。真正的出路不是更便宜的token,而是“更高token效率的Agent框架”叠加“更强大高效的模型”之间的协同进化。
据行业数据显示,截至2026年3月,中国AI大模型日均Token调用量已突破140万亿,较2024年初增长超千倍。
罗福莉算了一笔账:按API定价折算,这类框架的真实成本大概是订阅价格的数十倍。她觉得这一差距“不是缺口,而是天坑”。

更值得国内AI公司注意的是,Anthropic在4月7日宣布,其年化收入(ARR)突破300亿美元,正式反超OpenAI的250亿美元。
从2025年底的90亿到如今300亿,其仅用三个多月就实现了233%的爆发式增长,即便如此,Anthropic仍在算一笔精细的账。
在罗福莉看来,Anthropic封杀“龙虾”的真正价值在于:让效率低下的成本真实可见,从而倒逼整个生态走向工程自律。短期阵痛不是坏事,它会推动框架开发者认真改进上下文管理、最大化prompt缓存命中率、削减无效token消耗。
发新模型眼下可能没那么重要
DeepSeek R1最初的惊艳,原本也是架构的创新,极大的实现了token的节约。当时,低价token的源头虽然是DeepSeek,但其本意从来不是为了价格战,只是后来者把这种创新完成了价格战游戏。
2025年初的爆红,也让DeepSeek几度面临容量不足的窘迫,时常宕机。
在第一拨大规模用户涌入后,曾有DeepSeek内部人士告诉凤凰网科技,因为当时资源不够,所以用户看起来被限制了使用次数,后来内部通过优化方法,重新分配资源。
但这种内部架构的创新已经难以满足当前的token调用需求。
国金证券在研报中指出,算力供需正在发出关键信号——需求端以指数级膨胀,供给端却受限于芯片出口管制与成本约束,难以同步扩张。
免费模式,成了这场危机的加速器。大模型运营成本极高,免费模式让平台算力扩容始终滞后于用户增长。
在2026年开年以来,DeepSeek已经上演了至少7次大规模服务中断。3月29日晚至30日上午,平台再度突发全局崩溃,网页端与APP端同时无法使用,宕机时间持续约12小时,直至次日9时13分才恢复正常。
或许是压力之下,DeepSeek在4月8日低调更新了对话界面,在输入框上方新增了“快速模式”和“专家模式”选项。在行业人士看来,分层设计既可以通过算力分流缓解峰值压力,也能为后续搭建付费体系、限额限流铺路。
不久前,OpenAI宣布下线Sora,将有限的算力资源重新聚焦于核心服务,与DeepSeek开启分层、Anthropic的高峰限流措施共同揭示了一个现实:需求增速已远超基础设施的扩张能力。
AI赛道的“房间里的大象”
从DeepSeek的免费模式难以为继,到Anthropic的封杀令,再到罗福莉的价格战警告,这些看似独立的事件共同指向同一个结构性矛盾:AI赛道的token用量正在以指数级速度膨胀。
海外的AI数据中心大手笔抢购存储芯片,再向华尔街开出账单,犹如一场没有尽头的赌注游戏。
实际上,不止是芯片,电力危机也在叠加:AI算力耗电占全社会用电量增速的46%,远超整体6.1%的增长水平,电力弹性不足成为硬约束。
在这种背景下,行业正在经历一场从“免费烧钱换用户”到“算力精细化运营”的范式切换。阿里云、腾讯云早前已启动算力涨价,最高涨幅达34%。但说起来是涨价,实际也只不过是把之前价格战时期的优惠给抹掉了,恢复了正常定价。
4月8日,在智谱发布旗舰开源模型GLM-5.1之际,再度提价10%,此前其已经进行过两次提价。
如果说过去两年,大模型行业的关键词是“规模”和“速度”,那么现在,关键词已经悄然变成了两个字:成本。
即便是像OpenAI和Anthropic这样的海外明星企业,目前都还处于高投入阶段,算力、人才、基础设施等等开支巨大。在持续依赖融资的同时,它们都必须回答一个现实问题:这门生意什么时候能自我造血?
于是,行业开始出现一个明显转向:当AI开始赚钱,第一步不是赚更多,而是少亏一点。
以OpenAI为代表的一类玩家,选择的是更激进的路线:产品快速迭代、能力优先、生态开放,同时通过持续融资维持扩张节奏;而以Anthropic为代表的另一类,则明显更克制,把重点放在成本结构、稳定性和企业服务上,通过工程优化来提升效率。
两者的差异,可以简单理解为:一个是“先做出来再说”,一个是“先算清楚再做”。
这种变化,对普通用户其实也会产生直接影响。
首先,API价格未必会像很多人预期的那样持续大幅下降。虽然单位价格在降低,但成本控制的压力并没有消失,企业更可能通过优化结构,而不是无限降价来消化成本。
其次,免费额度和补贴可能逐步收紧。过去依赖“烧钱换增长”的阶段正在结束,当每一个Token都需要被精确计量时,慷慨的免费策略本身就变得不可持续。
再次,在体验层面,用户也可能感受到变化:模型回复会更克制、更精简;长文本、复杂推理或高频调用,可能被更严格地限制或分层定价。你看到的“更短回答”,背后往往不是模型变“懒”,而是系统在主动做成本优化。
从某种意义上说,Token被省下来的那一刻,成本并没有消失,而是被重新分配——在模型厂商、企业客户与终端用户之间流动。
说到底,AI正在完成一次从“实验品”到“商品”的转变。大模型从来不是纯技术问题,而是一门重资产生意。当增长神话退去,算账就成为最核心、最现实、也最无法回避的问题。
这,才是“抠Token”背后真正的行业逻辑。