Uber想把全球数百万名司机变成公司的“传感器网络”
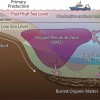
在结束自建自动驾驶项目多年之后,Uber 正试图以另一种方式重返无人车版图:把全球数百万名网约车司机的车辆,改造成为自动驾驶公司和其他实体世界 AI 模型提供数据的移动“传感器阵列”。

Uber 首席技术官 Praveen Neppalli Naga 在接受采访时披露了这一长期构想,并将其描述为公司今年 1 月底宣布的新项目 AV Labs 的“自然延伸”。 他表示,Uber 的最终方向,是在不远的将来给人类司机的私家车加装各类传感器,用于采集真实道路场景数据。Naga 同时强调,在迈向这一步之前,公司需要先彻底弄清不同传感器套件的能力与工作方式,并等待美国各州在“什么是传感器、如何共享数据”上给出更明确的监管指引。
目前,AV Labs 仍运行在一支规模有限的专用车队之上,这些车辆配备传感器,由 Uber 自行运营,与日常接单的司机群体相互独立。 但从 Uber 的叙述可以看出,这只是一个起点:Uber 在全球拥有数以百万计的司机,即便只有一小部分车辆安装了传感器,也足以构建起一张任何单一自动驾驶公司都难以匹敌的道路数据采集网。Naga 认为,如今制约自动驾驶技术演进的瓶颈已经不在底层算法或算力,而是高质量、足够多样的真实世界数据。“瓶颈是数据,”他说,“像 Waymo 这样的公司需要不断出去采集数据,覆盖不同的场景。”
在他的设想中,自动驾驶企业可以通过 Uber 的网络,按需订制极为精细的训练数据,比如提出“在旧金山某所学校门口的路口,在某个特定时间段采集交通情况,以训练模型”的需求。 真正的问题在于,绝大多数自动驾驶公司并没有充足的资本在全球大规模铺设自有车队,去高密度覆盖这些长尾场景。Uber 如果能调动已有的司机和车辆资源,就有望成为整个行业的数据供给层,为自动驾驶技术提供源源不断的“燃料”。
外界曾长期质疑,在放弃自建无人车后,Uber 是否会在未来被自动驾驶公司“绕开”,甚至在出行生态中被边缘化。 联合创始人 Travis Kalanick 也曾公开表示,放弃自动驾驶是一个“巨大错误”。 如今,通过 AV Labs,Uber 正试图把自己的角色从自动驾驶整车开发者,转变为这一领域的基础设施和数据平台,借助广泛的司机网络和订单流量,为所有参与者提供底层能力。
Uber 目前已经与全球 25 家自动驾驶公司达成合作,其中包括在伦敦运营的 Wayve 等玩家。 在此基础上,公司正在搭建一个所谓“AV 云”:即一个标注完备的多模态传感器数据仓库,合作伙伴可以在其中进行检索和调用,用于训练各自的自动驾驶模型。 Naga 介绍,合作公司还可以在 Uber 平台上对真实订单运行“影子模式”推理——也就是在真实行程数据上模拟自己的自动驾驶系统会如何决策,而无需真正把无人车投放到路面上。
从对外表态来看,Uber 试图将这一平台包装为“行业公共设施”。“我们的目标不是靠这些数据赚钱,”Naga 说,“而是希望把它民主化。” 不过,考虑到优质数据在自动驾驶和更广泛 AI 领域的商业价值以及稀缺性,这样的定位未来能否持续仍存疑问。事实上,Uber 近年已经对多家自动驾驶公司进行了股权投资,而如果其掌握的大规模、差异化训练数据成为合作伙伴核心竞争力的一部分,Uber 在这些公司面前的议价能力很可能进一步加强。
在这套构想背后,Uber 的逻辑正在从“造车”转向“做平台”:一方面,它通过自身的出行和外卖网络,继续维持在终端用户层面的入口优势;另一方面,则尝试把司机车辆的真实行程和场景沉淀为结构化数据资产,为自动驾驶企业乃至其他需要实体世界训练数据的大模型公司服务。 对于一家早已不再亲自做自动驾驶硬件和软件栈的公司而言,这或许是继续参与下一轮交通技术变革、并在其中保持存在感的全新路径。