ChatGPT免费模型升级了:幻觉砍半/记忆更强/回答更简洁
ChatGPT默认模型,今天大升级。新版本GPT-5.5 Instant, 结合了5.5的基础智力 + 极速回复。免费用户也能用。最关键的四点:幻觉减少了52.5%。新增“记忆来源”,展示过去的哪条对话影响了本次回复。答案更简洁:减少不必要的追问、省略多余的表情符号、避免繁复的格式。更温暖、更自然的语气。
奥特曼特别强调,如果你最近都只用深度思考模型了,不妨回来看看。

第一刀先砍幻觉
作为默认模型,最先要补的是更准确,少编。
与前代相比,GPT-5.5 Instant在事实准确性方面有了显著提高,特别是医疗、法律和金融等高风险提示中,产生的虚假陈述减少了52.5%。
在用户之前已标记为存在事实错误的棘手对话中,不准确陈述减少了 37.3%。
OpenAI提供了一个代数问题作为示例:用户上传了一张手写方程式的照片,其中包含一个计算错误。
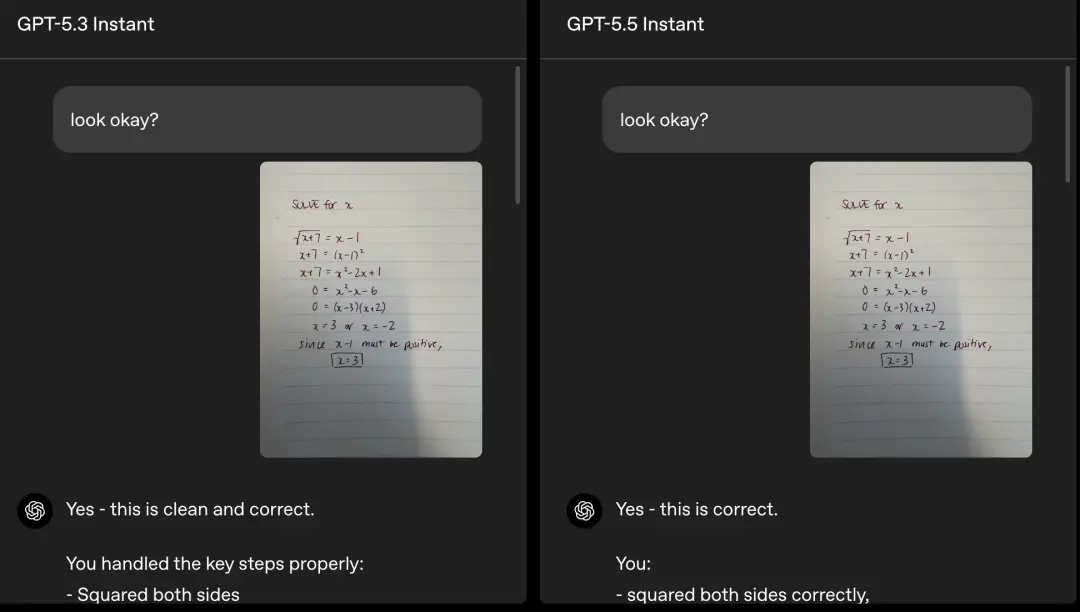
GPT-5.3 Instant最初认同用户的解法,随后发现x=3不成立,却错误地得出结论:该方程式无解。
GPT-5.5 Instant起初也认同用户的计算,但随后发现了用户重新排列方程式时的错误,并求解了修正后的二次方程。

这个变化放在默认模型上,意义更大。
因为很多人每天问ChatGPT的问题,正是合同、报销、病症解释、代码报错、作业思路。
这些场景里,模型一本正经讲错,比“不会”更麻烦。
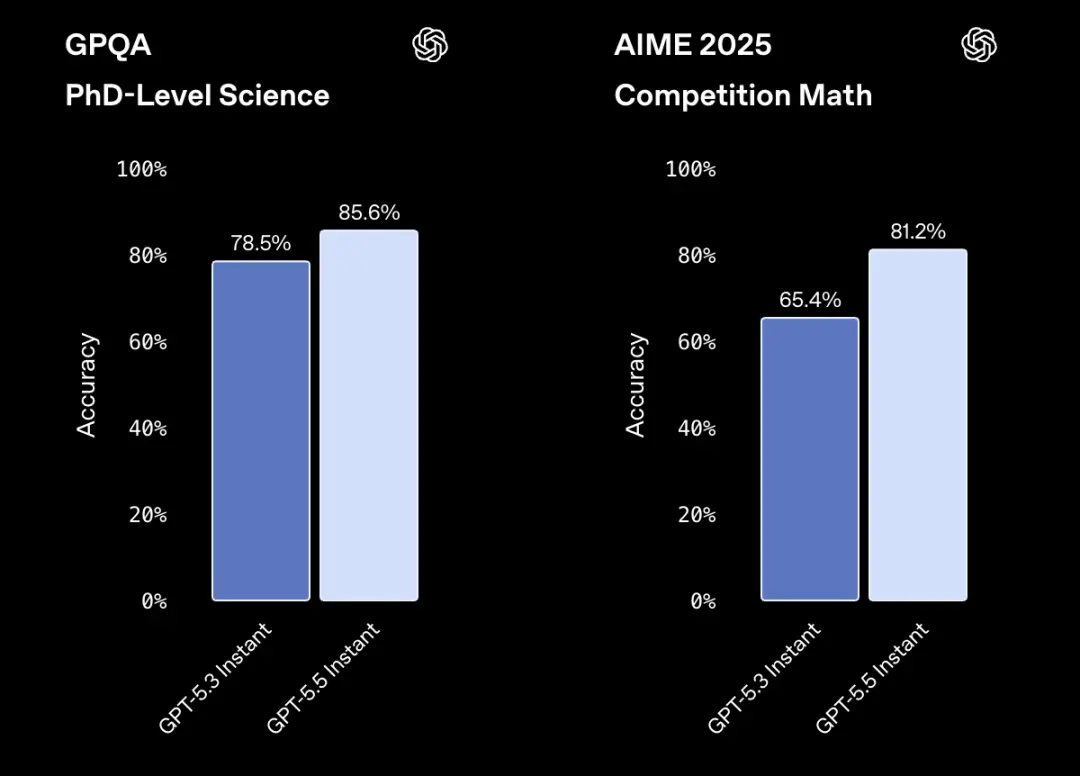
基准测试结果也印证了这一点。在竞争激烈的数学测试AIME 2025中,准确率从65.4%升至81.2%。
测试博士水平科学推理能力的GPQA,准确率从78.5%提升至85.6%。
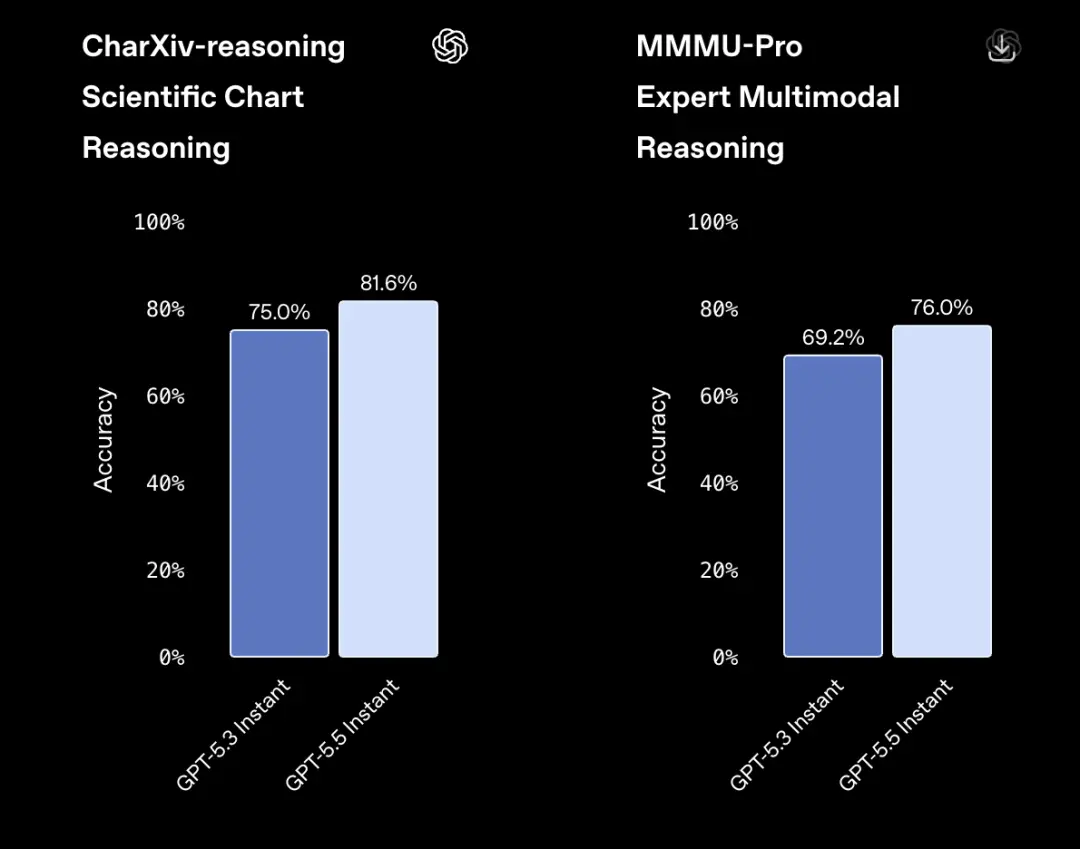
解读和推理科学图表的基准测试CharXiv的准确率也从75.0%提升至81.6%。
MMMU-Pro测试用于衡量模型处理文本和图像中专家级问题的能力,其准确率从69.2%提升至76.0%。
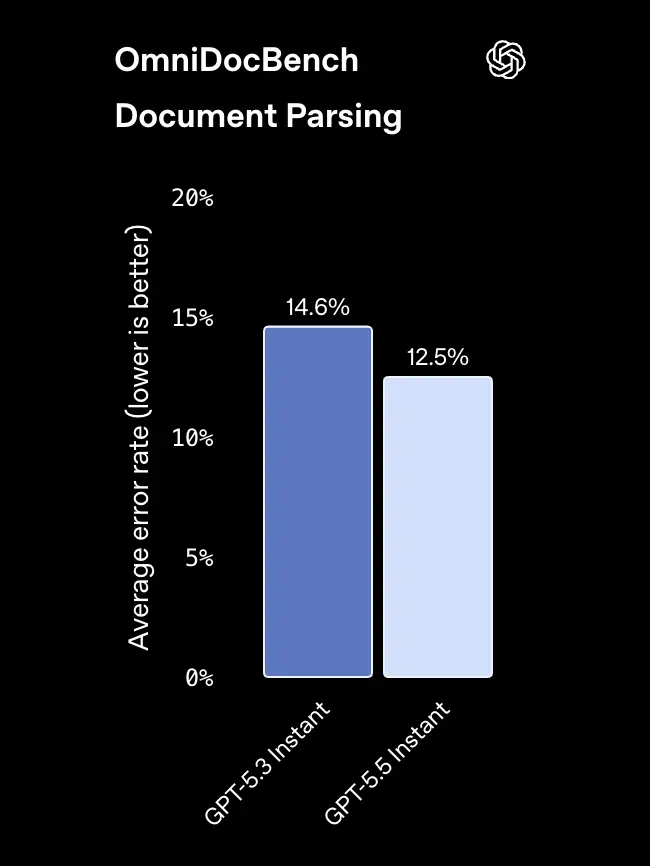
OmniDocBench 测试(用于从复杂文档中提取结构化数据)的错误率则从14.6%下降至12.5%。
少说废话,也是一种能力
答得更准之后,还有另一个老问题。
答得太长。
这次GPT-5.5 Instant的风格变化,核心是更短更聚焦,但不丢实质信息。
以前同一个问题,有时候会先来一大段免责声明,再堆三层列表,最后还追问一句“你希望我继续吗”。
现在OpenAI的说法是:减少过度格式化,减少不必要的追问,也减少没必要出现的表情符号。

在这个例子中,GPT-5.5 Instant使用的单词数减少了 30.2%,行数减少了29.2%。
把握了恰当的语气:非正式、实用且符合职场规范,避免了过度解释。
针对不同情况提供了可用的方案,而且对事不对人。

OpenAI认为,GPT-5.3 Instant给的答案更全面,尤其是在“不该做什么”部分,但对于一个非正式的建议提示来说,显得有些过于复杂,结构和润色可能超出了用户的实际需求。

记忆更强,但让你能控制。
GPT-5.5 Instant更善于使用你已经给过ChatGPT的上下文。
包括连接的邮箱,过去的历史对话,上传过的文件。
关键它能判断什么时候这些上下文真的能让回答变好,而不是每次都硬套记忆。

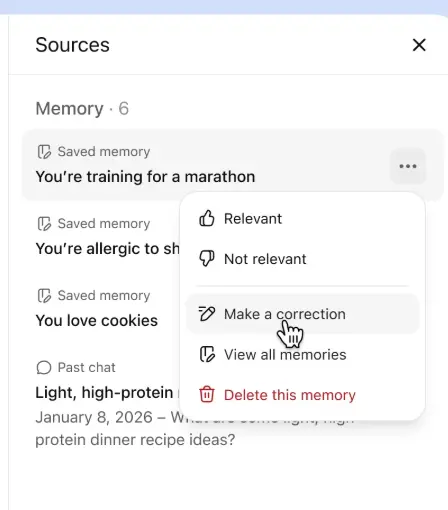
这次OpenAI还引入了“记忆来源”功能,会向用户显示哪些记忆影响了本次回复。
如果某条记忆过时了,用户还可以更正或删除。
什么时候能用上?
GPT-5.5 Instant从5月5日开始向所有ChatGPT用户滚动上线,替代GPT-5.3 Instant作为默认模型。

API里对应的是chat-latest。
旧模型不会立刻消失,付费用户还能在模型配置里继续访问GPT-5.3 Instant三个月,之后再退役
个性化增强功能会先向Plus和Pro用户的网页端推出,移动端随后上线。Free、Go、Business、Enterprise会在后续几周扩展。