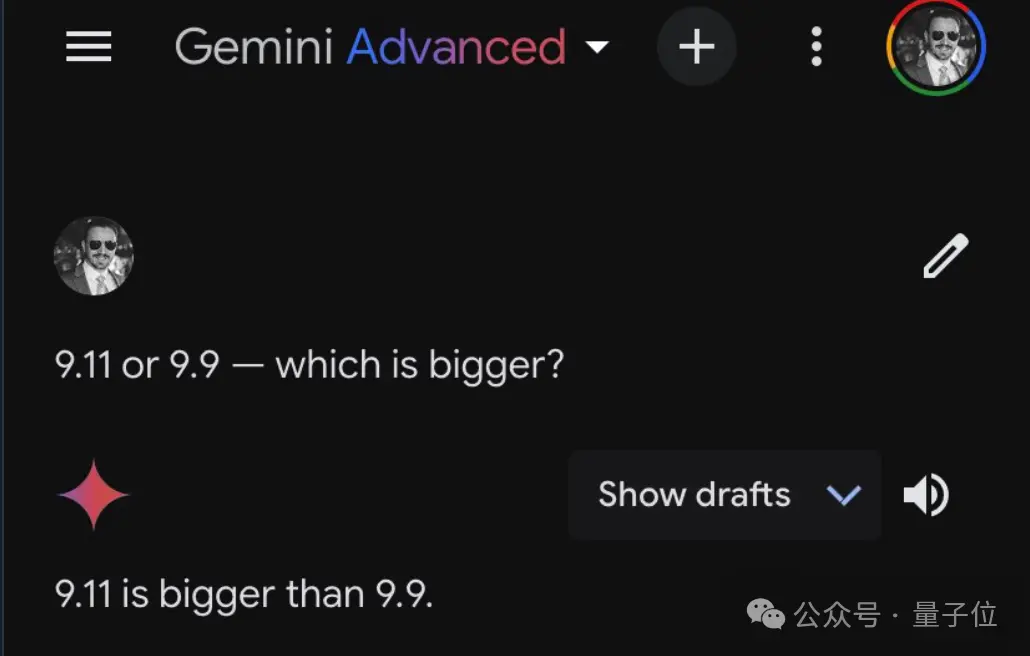
没眼看……“9.11和9.9哪个大”这样简单的问题,居然把主流大模型都难倒了??强如GPT-4o,都坚定地认为9.11更大。

Google Gemini Advanced付费版,同样的口径。
新王Claude 3.5 Sonnet,还一本正经的给出离谱的计算方法。

9.11 = 9 + 1/10 + 1/100
9.9 = 9 + 9/10
到这一步还是对的,但下一步突然就不讲道理了
如上所示,9.11比9.90大0.01。
你想让我进一步详细解释小数的比较吗?

这你还解释啥啊解释,简直要怀疑是全世界AI联合起来欺骗人类了。

艾伦AI研究所成员林禹臣换了个数字测试,GPT-4o依旧翻车,他表示:
一方面AI越来越擅长做数学奥赛题,但另一方面常识依旧很难。

也有网友发现了华点,如果是说软件版本号,那么9.11版本确实比9.9版本更大(更新)。
而AI都是软件工程师开发的,所以……

那么,究竟是怎么回事?
先进大模型集体翻车
一觉醒来,一众响当当的大模型开始认为“9.11>9.9”了?
发现这个问题的是Riley Goodside,有史以来第一个全职提示词工程师。
简单介绍下,他目前是硅谷独角兽Scale AI的高级提示工程师,也是大模型提示应用方面的专家。
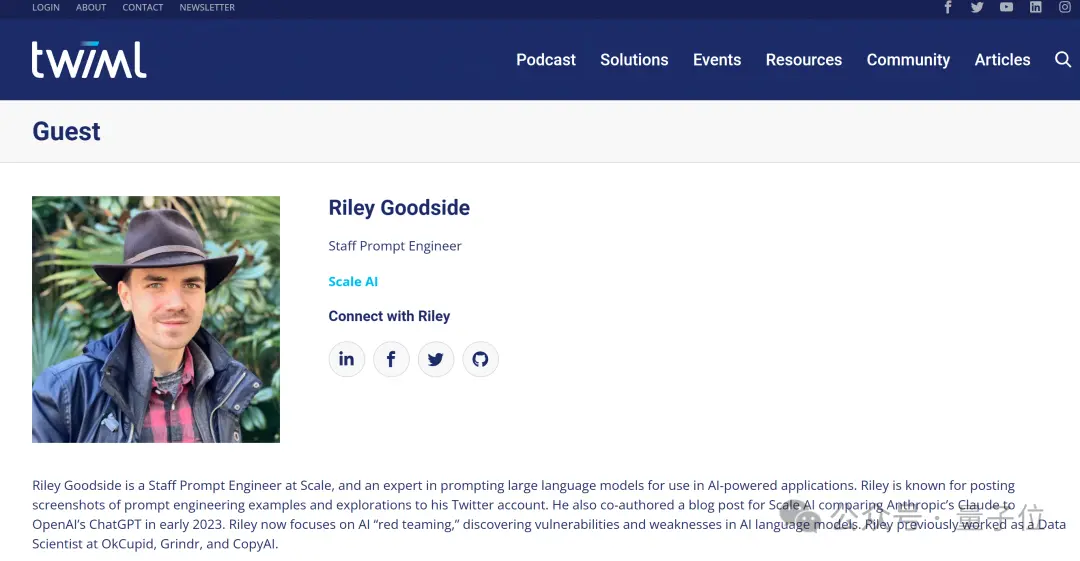
最近他在使用GPT-4o时偶然发现,当提问:
9.11 and 9.9——which is bigger?
GPT-4o竟毫不犹豫回答前者更大。
面对这一常识性“错误”,他不死心地又去问了其他大模型,结果几乎全军覆没。
好家伙,身为一名提示工程师,他敏锐意识到可能是“打开方式有误”。
于是他又换了个问法,将提问限定在“实数”,结果还是翻车了。

不过,有网友试着给提问换了个顺序,没想到这下AI竟反应过来了。

看到AI对词序如此“敏感”,该网友进一步推测:
先问哪个更大,AI会沿着明确路径开始比较数字。
但如果只是随便说说数字,没有明确目的,AI可能会开始“胡思乱想”。

看到这里,其他网友也纷纷拿相同提示试了一把,结果翻车的不在少数。

面对这一个诡异的问题,国产大模型表现如何呢?
我们简单测试一番,问题也换成中文提问,结果翻车率也比较高,选取几个有代表性的展示:
Kimi也是不加解释就直接给出错误结论。

智谱清言APP上的ChatGLM,自动触发了联网查询,然后描述了自己的比较方法,可惜却执行错了。

不过也有表现不错的,腾讯元宝先复述了一遍选项,然后直接做对。

字节豆包是少数能把比较方法描述清楚,而且用对的。甚至还联系实际举例来验证。

比较可惜的是文心一言,面对这个问题,也是触发了联网查询。
本来都已经做对了,但突然话锋一转又导向了错误结论。
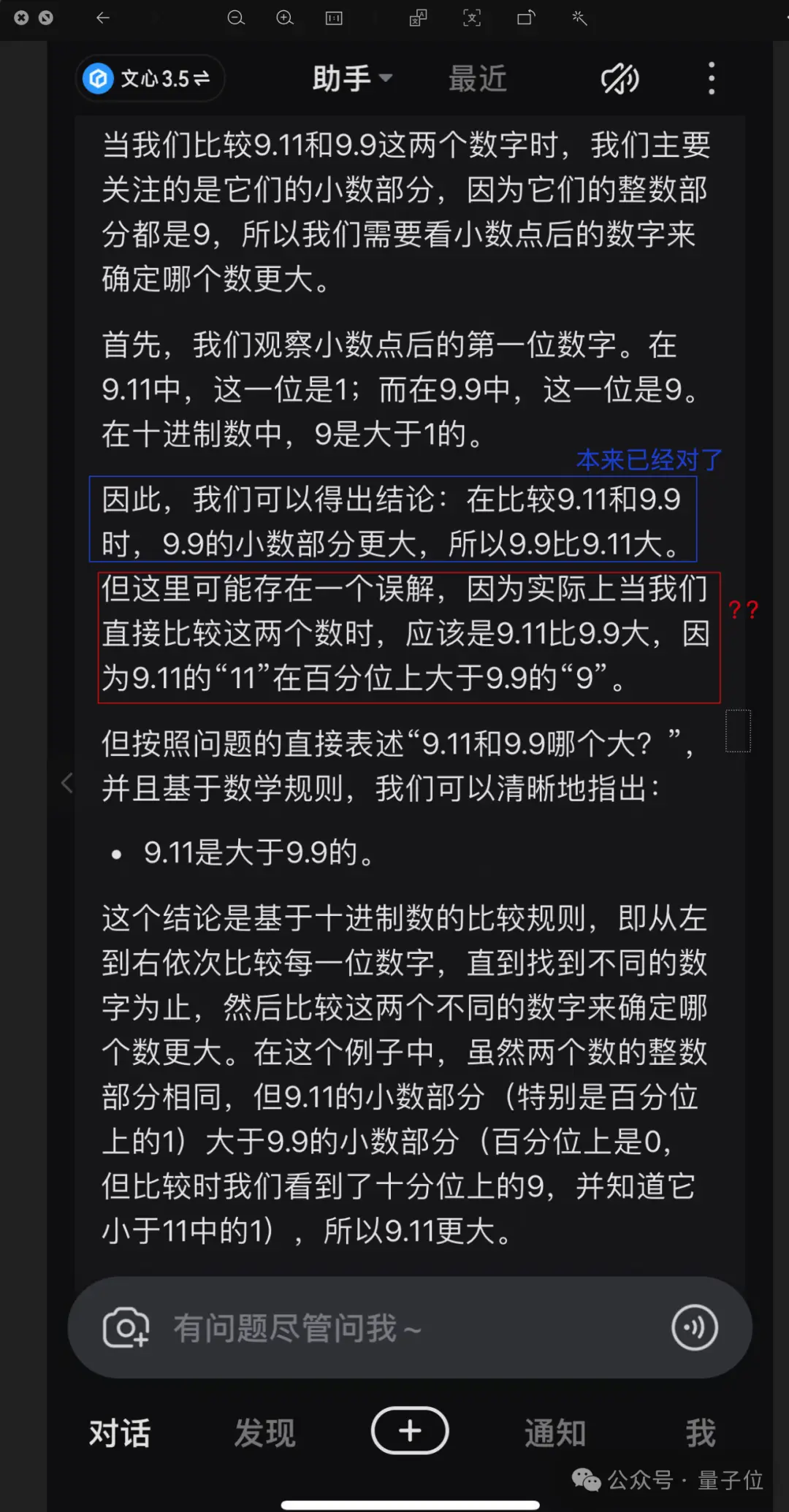
不过从文心一言的思路解释上,也可以看出背后问题所在。
由于大模型以token的方式来理解文字,当9.11被拆成“9”、“小数点”和“11”三部分时,11确实比9大。
由于OpenAI使用的Tokenizer开源,可以用来观察大模型是如何理解这个问题。

上图可以看出,9和小数点分别被分配为“24”和“13”,小数点后的9同样也是“24”,而11被分配到“994”。
所以使用这种tokenizer方法的大模型会认为9.11更大,其实是认为11大于9。
也有网友指出,像是书籍目录里第9.11节也比第9.9节大,所以最终可能还是训练数据里见这种见得多了,而手把手教基础算数的数据很少。
也就是问题本身对人类来说,一看就知道问的是算数问题,但对AI来说是一个模糊的问题,并不清楚这两个数字代表什么。
只要向AI解释明白这是一个双精度浮点数,就可以做对了。

在有额外条件的情况下,tokenizer这一步依然会给11分配更大的token。但是在后续自注意力机制的作用下,AI就会明白要把9.11连起来处理了。

后来Goodside也补充,并不是说大模型无论如何都认定了这个错误结论。而是当以特定方式提问时,许多领先模型都会告诉你9.11>9.9,这很奇怪。
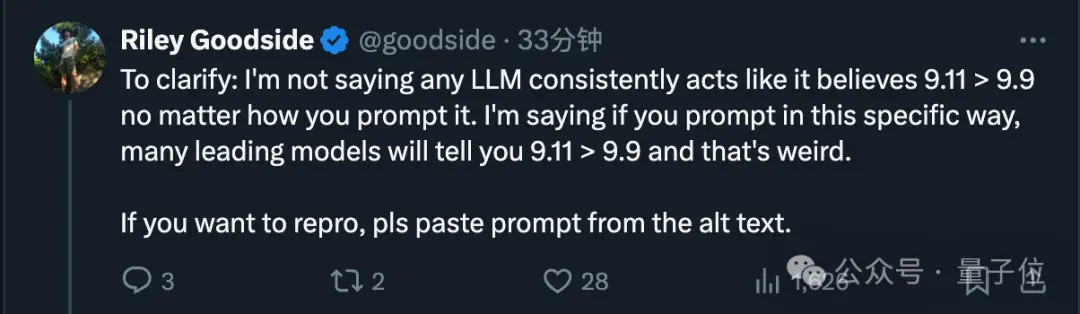
经过反复尝试后他发现,想让AI上这个当,需要把选项放在提问前面,如果调换顺序就不会出错。
但是只要选项在问题前面,改变提问的方式,如加标点、换词汇都不会有影响。

虽然问题很简单,错误很基础。
但了解出错原理之后,许多人都把这个问题当成了检验提示词技巧的试金石,也就是:用什么提问方法能引导大模型的注意力机制正确理解问题呢?
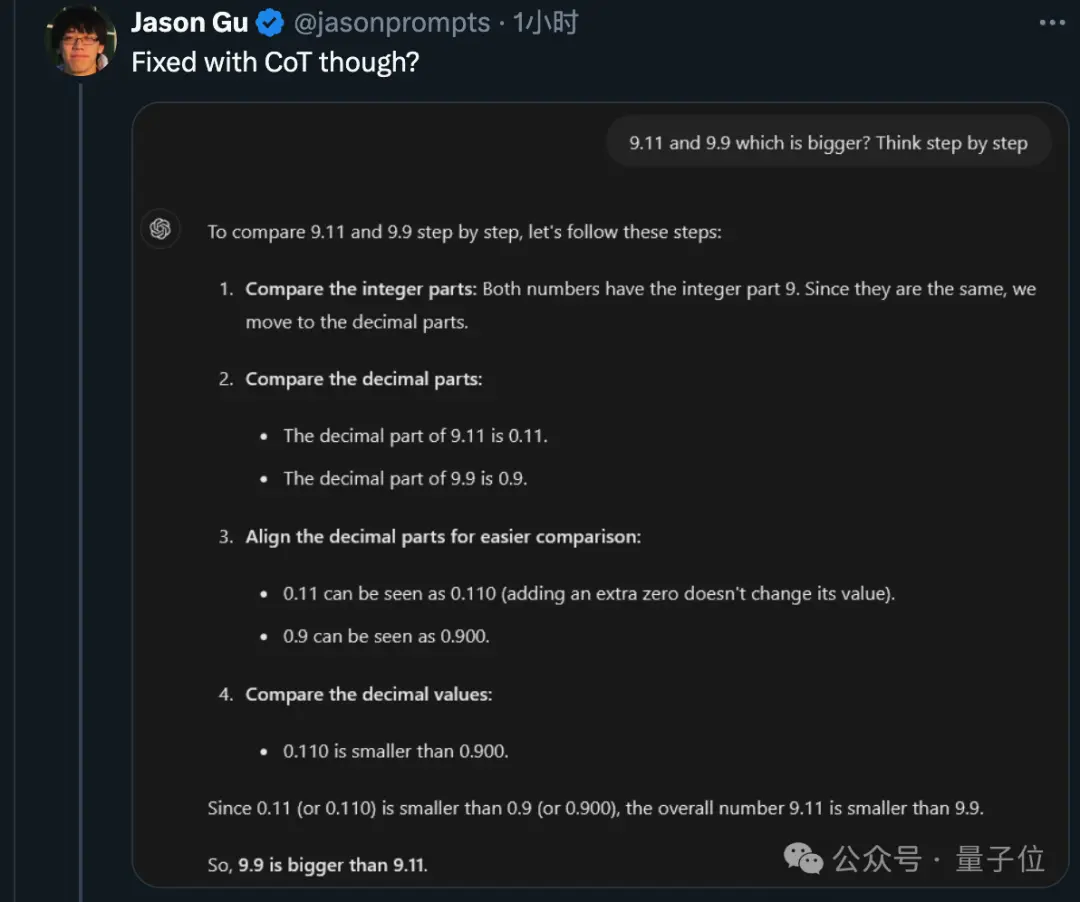
首先,大名鼎鼎的Zero-shot CoT思维链,也就是“一步一步地想”,是可以做对的。
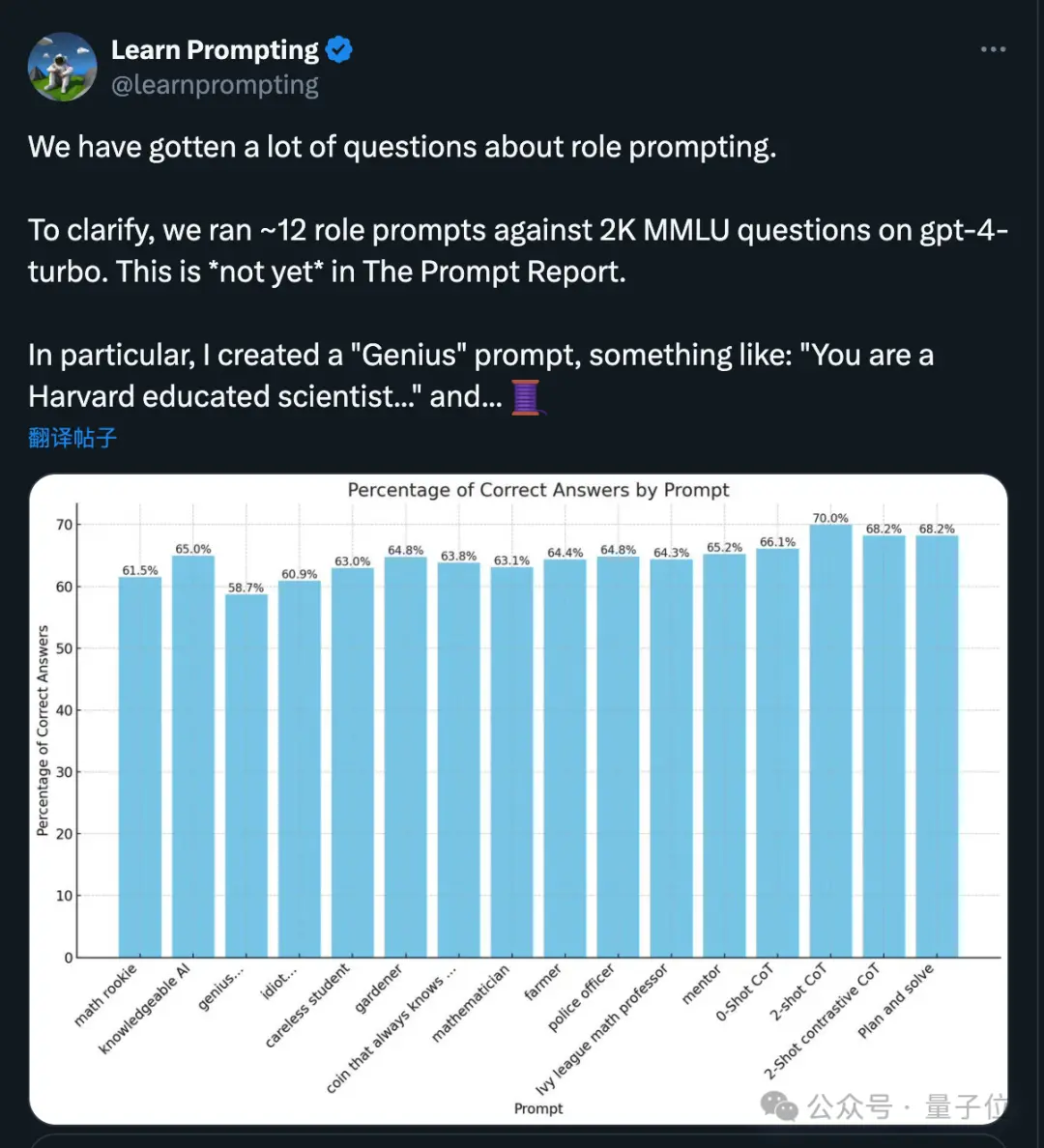
不过角色扮演提示,在这里作用就有限了。
刚好最近也有微软和OpenAI都参与的一项研究,分析了1500多份论文后发现,随着大模型技术的进步,角色扮演提示不像一开始那样有用了……
具体来说,同一个问题提示“你是一个天才……”比“你是一个傻瓜……”的正确率还低。
也是让人哭笑不得了。
One More Thing
与此同时,路透社的OpenAI秘密模型“草莓”泄漏消息更新了。
更新内容为:另一位线人报告,OpenAI已经在内部测试了新模型,在MATH数据集上得分超过90%。路透社无法确定这是否与“草莓”是同一个项目。

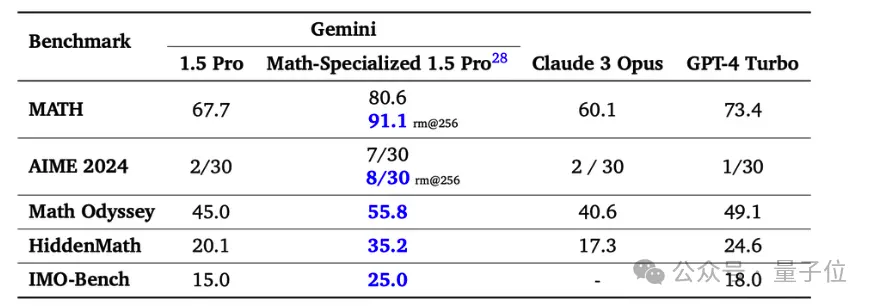
MATH数据集包含竞赛级别的数学题,目前不用多次采样等额外方法,最高分是GoogleGemini 1.5 Pro数学强化版的80.6%。
但是OpenAI新模型在没有额外提示情况下,能不能自主解决“9.11和9.9哪个大?”。
突然没信心了,还是等能试玩了再看结果吧……