Meta美东时间周二发布最新款AI模型Llama 3.1 405B,将矛头对准OpenAI和谷歌公司开发的大模型。扎克伯格称其为“艺术的起点”,表示Llama 3.1拥有大范围新的能力,包括改善推理以帮助处理复杂的数学问题、或即时合成一整本书,这是Meta迄今为止最大的模型。同时,英伟达AI Foundry将为全球企业提供Llama 3.1模型的定制服务。
对标GPT4-o、Claude 3.5 Sonnet
媒体报道,Llama 3.1 405B模型包含4050亿个参数,是近年来参数规模最大的模型之一。通常,参数大致对应于模型的解决问题的能力,参数越多的模型通常表现越好。该模型使用16000个英伟达H100 GPU进行训练,受益于新的训练和开发技术,Meta声称,Llama 3.1 405B在一定程度上可以与OpenAI的GPT-4o和Anthropic的Claude 3.5 Sonnet竞争。
Meta高管表示,该模型主要用于为Meta内部和外部开发人员的聊天机器人提供支持,具备广泛的新功能,包括改进的推理能力,帮助解决复杂的数学问题或瞬间综合整本书的文本。它还具有生成式AI功能,可以通过文本提示生成图像。一项名为“想象自己”的功能允许用户上传他们的面部图像,然后生成他们在不同场景和情境中的描绘。
与Meta之前的模型一样,Llama 3.1 405B可以下载或在云平台(如AWS、Azure和Google Cloud)上使用。它还在WhatsApp和Meta.ai上使用,为美国用户提供聊天机器人体验。
扎克伯格表示,Meta的聊天机器人拥有“数亿”用户,并预计到年底将成为世界上使用最广泛的聊天机器人。他希望Meta以外的公司也能使用Llama来训练他们自己的AI模型。
Meta在AI上的投资非常大。扎克伯格表示,训练Meta的Llama 3模型花费了“数亿美元”的计算资源,但他预计未来的模型成本将更高。“未来这将需要数十亿甚至更多的计算资源,”他说。2023年,Meta试图削减一些未来技术和管理层的支出,裁掉了数千个工作岗位,这是扎克伯格称之为“效率之年”的一部分。但扎克伯格仍然愿意在AI竞赛中投入资金。
“我认为现在很多公司都在过度建设,你回头看时可能会觉得‘哦,我们可能都花费了更多的数十亿美元’,”扎克伯格说。“另一方面,我实际上认为所有投资的公司都在做出理性的决定,因为如果落后了,未来10到15年你将在最重要的技术上处于劣势。”
“如果AI在未来像移动平台一样重要,那么我不想通过竞争对手访问AI,”扎克伯格说,他长期以来对Meta依赖于Google和苹果手机和操作系统来分发其社交媒体应用感到不满。“我们是一家技术公司,我们需要不仅在应用层面上构建东西,还要在整个技术栈上进行构建。为此进行这些巨大的投资是值得的。”
目前仅支持文本 将尝试多模态
像其他开源和闭源生成式AI模型一样,Llama 3.1 405B可以执行各种任务,可以编程、回答基本数学问题,也可以用八种语言(英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语)总结文件。该模型目前仅支持文本操作,这意味着它不能回答图像问题,但大多数基于文本的工作负载(如分析PDF和电子表格)都在其能力范围内。
Meta表示,该公司正在尝试多模态模型。在周二发表的一篇论文中,公司研究人员表示,他们正在积极开发可以识别图像和视频并理解(和生成)语音的Llama模型。然而,这些模型尚未准备好公开发布。
为了训练Llama 3.1 405B,Meta使用了一个包含15万亿个标记的数据集,这些标记的数据更新到2024年(15万亿个标记相当于7500亿个单词)。这不是一个新的训练集,因为Meta使用了这个基本集来训练早期的Llama模型,但公司声称它改进了数据管理管道,并采用了“更严格”的质量保证和数据过滤方法来开发这个模型。
同时,Meta还使用了由其他AI模型生成的合成数据来微调Llama 3.1 405B。目前,包括OpenAI和Anthropic在内的大多数主要AI供应商都在探索合成数据的应用,以扩大AI训练规模,但一些专家认为合成数据应该作为最后的手段,因为它可能会加剧模型偏见。
在上述论文中,Meta研究人员写道,与早期的Llama模型相比,Llama 3.1 405B的训练包含了更多的非英语数据(以提高其在非英语语言上的表现)、更多的“数学数据”和代码(以提高模型的数学推理能力)以及最近的网络数据(以增强其对当前事件的了解)。
“在许多方面,训练数据就像是构建这些模型的秘方和酱料,”Meta AI项目管理副总裁Ragavan Srinivasan在接受TechCrunch采访时表示。“所以从我们的角度来看,我们在这方面投入了大量资金。这将是我们会继续精炼的事情之一。”
同时,扎克伯格否认了使用Facebook和Instagram帖子数据训练Llama是一个关键优势的说法。“这些服务上的许多公共数据我们允许被搜索引擎索引,所以我认为Google等公司实际上也有能力使用很多这些数据。”
更大的上下文窗口和工具
另外,Llama 3.1的上下文窗口(context window)涵盖128000个标记,比以前的Llama模型更大,大约相当于一本50页书的长度。
模型的上下文或上下文窗口指的是模型在生成输出(如文本)之前考虑的输入数据(如文本)。具有较大上下文窗口的模型,可以总结更长的文本片段和文件。在为聊天机器人提供动力时,这种模型也不太可能忘记最近讨论的主题。
Meta周二还推出了另外两个新的较小模型Llama 3.1 8B和Llama 3.1 70B,这两款模型是Meta在4月发布的Llama 3 8B和Llama 3 70B模型的更新版本,它们也有128,000个标记的上下文窗口。相比之下,以前的模型上下文窗口最大为8,000个标记。
与Anthropic和OpenAI的竞争模型一样,所有Llama 3.1模型都可以使用第三方工具、应用程序和API来完成任务。此外,Meta声称Llama 3.1模型可以在一定程度上使用某些之前未见过的工具。
建立生态系统
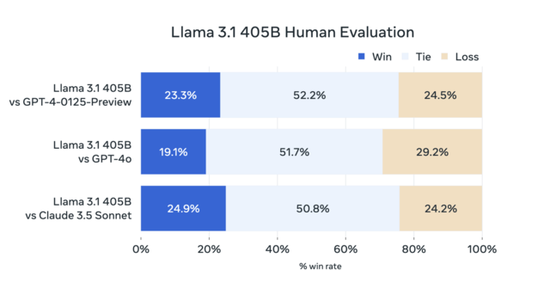
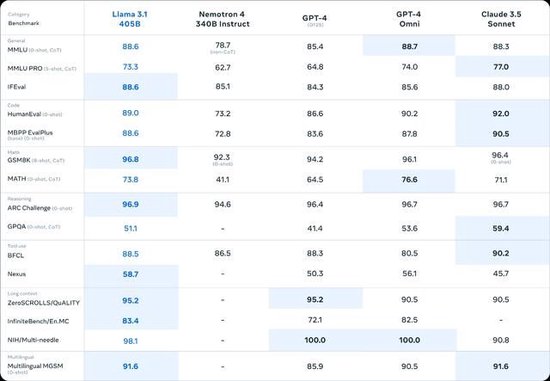
Meta在论文中表示,Llama 3.1 405B的性能与OpenAI的GPT-4相当,在与GPT-4o和Claude 3.5 Sonnet的比较中取得了“混合结果”。尽管Llama 3.1 405B在执行代码和生成图表方面优于GPT-4o,但其多语言能力整体较弱,在编程和一般推理方面也落后于Claude 3.5 Sonnet。
由于其规模庞大,它需要强大的硬件来运行。Meta建议至少使用一个服务器节点。Meta表示,Llama 3.1 405B更适合用于模型蒸馏——将大型模型的知识转移到较小、更高效的模型上——以及生成合成数据来训练(或微调)其他模型。
为了鼓励合成数据的使用,Meta表示已经更新了Llama的许可,允许开发者使用Llama 3.1模型系列的输出来开发第三方AI生成模型。重要的是,该许可仍然限制了开发者如何部署Llama模型:月活用户超过7亿的应用开发者必须向Meta申请特别许可,由公司自行决定是否授予。
除了Llama 3.1系列,Meta还发布了所谓的“参考系统”和新的安全工具,其中一些工具阻止可能导致Llama模型行为不可预测或不理想的提示,以鼓励开发者在更多地方使用Llama。公司还预览并征求对Llama Stack的意见,这是一个即将推出的API,用于微调Llama模型、使用Llama生成合成数据以及构建“代理”应用程序——由Llama驱动的可以代表用户采取行动的应用程序。
争夺市场份额 正在研发Llama 4
在周二早上发布的一封公开信中,Meta CEO马克·扎克伯格描绘了一个未来的愿景,即AI工具和模型能够到达世界各地更多的开发者手中,确保人们能够享受到AI的“好处和机会”。
扎克伯格既捍卫自己的开源策略,又大规模投资AI。“我认为对于一个AI助手来说,最重要的产品特性将是它的智能程度,”扎克伯格在接受媒体采访时说道。“我们正在构建的Llama模型是世界上最先进的模型之一。”
扎克伯格补充说,Meta已经在研发Llama 4。
目前,Meta采用了一个久经考验的策略:免费提供工具以培养生态系统,然后逐渐添加一些付费的产品和服务。在模型上花费数十亿美元,然后将其商品化,还可以降低Meta竞争对手的价格,并广泛传播公司的AI版本。这也让公司可以将开源社区的改进纳入其未来的模型中。
Llama无疑引起了开发者的注意。Meta声称,Llama模型已经被下载了超过3亿次,到目前为止已经创建了超过20,000个Llama派生模型。
目前,Meta正在花费数百万美元游说监管机构接受其偏好的“开放”生成式AI。虽然,Llama 3.1模型并没有解决当今生成式AI技术的根本问题,如其容易编造内容和重复训练数据中的问题。但它们确实推进了Meta的一个关键目标:成为生成式AI的代名词。
与英伟达联手 AI Foundry将提供定制Llama 3.1模型服务
此外,Meta还联合AI芯片领头羊英伟达周二宣布,英伟达AI Foundry将为全球企业定制Llama 3.1生成式AI模型,将他们的数据与Llama 3.1 405B和英伟达Nemotron模型结合,创建“超级模型”。
英伟达AI Foundry将提供全面的生成式AI模型服务,涵盖数据管理、合成数据生成、微调、检索、安全防护和评估,以部署定制的Llama 3.1 NVIDIA NIM微服务,并提供新的NVIDIA NeMo检索微服务以实现准确的响应。
Meta是英伟达的顶级客户之一,由于没有运行自己的面向企业的云服务,Meta需要最新的芯片来训练其AI模型,这些模型内部用于目标定位和其他产品。例如,Meta表示,Llama 3.1模型的最大版本是在16,000个Nvidia H100显卡上训练的。
分析认为,这种关系对两家公司来说是各取所需。对于英伟达来说,Meta正在训练其他公司可以使用和调整的开源模型,而无需支付许可费用或请求许可,这可能会扩大英伟达自身芯片的使用,并保持需求的高涨。
但开源模型的创建可能耗资数亿美元或数十亿美元。没有多少公司能够以类似的投资金额开发和发布这样的模型。虽然Google和OpenAI是英伟达的客户,但他们将其最先进的模型保持私有。
另一方面,Meta需要稳定供应的最新GPU来训练越来越强大的模型。与英伟达一样,Meta也试图培养一个以公司开源软件为中心的AI应用程序开发者生态系统,即使Meta不得不基本上免费提供昂贵的代码和所谓的AI权重。
媒体报道,埃森哲将是使用新服务为客户构建定制Llama 3.1模型的首家企业,沙特阿美石油公司、AT&T、Uber和其他行业领袖也成为首批访问新Llama NVIDIA NIM微服务的用户。
Meta的25个Llama相关企业合作伙伴包括Amazon Web Services、Google Cloud、Microsoft Azure、Databricks和Dell。
网友:伟大的杰作 开源的胜利
英特尔首先发来贺电:“恭喜MetaAI!我们很激动能用Llama 3.1的发布来优化我们的AI产品组合。”
有网友表示,“非常棒的研究和进步,正在向着开源通用人工智能迈进!”
大部分网友对Meta表示祝贺,认为Llama 3.1是伟大的杰作,是开源社区的胜利。
也有网友质疑,规模如此巨大的模型,运行的时候要耗费多少电能?会对环境造成多大影响?