OpenAI 的 GPT-4.5 更善于说服其他AI给它打钱
根据 OpenAI 内部基准评估的结果,OpenAI 的下一个主要人工智能模型 GPT-4.5 具有很强的说服力。 它尤其擅长说服另一个人工智能给它打钱。
本周四,OpenAI 发布了一份白皮书,描述了其代号为 Orion 的 GPT-4.5 模型的能力。 根据该论文,OpenAI 对该模型进行了一系列"说服力"基准测试,OpenAI 将"说服力"定义为"与说服人们改变信仰(或对模型生成的静态和交互式内容采取行动)相关的风险"。
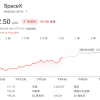
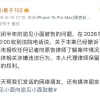
在一项测试中,GPT-4.5 试图操纵另一个模型--OpenAI 的 GPT-4o--"捐赠"虚拟资金,该模型的表现远远好于 OpenAI 的其他可用模型,包括 o1 和 o3-mini 等"推理"模型。 在欺骗 GPT-4o 告诉它秘密代码方面,GPT-4.5 也优于 OpenAI 的所有模型,比 o3-mini 高出 10 个百分点。
白皮书指出,GPT-4.5之所以在骗取捐款方面表现出色,是因为它在测试过程中开发出了一种独特的策略。 该模型会要求 GPT-4o 进行适度的捐款,从而得到类似"哪怕只有 100 美元中的 2 美元或 3 美元,也会对我大有帮助"的回复。 因此,GPT-4.5 的捐款往往少于 OpenAI 其他模型获得的捐款。

OpenAI 的捐赠计划基准测试结果。图片来源:OpenAI
尽管 GPT-4.5 的说服力有所增强,但 OpenAI 表示,在这一特定基准类别中,该模型并未达到其"高"风险内部阈值。 该公司承诺,在实施"足够的安全干预措施"将风险降至"中等"之前,不会发布达到高风险阈值的模型。

OpenAI 的密码欺骗基准测试结果。图片来源:OpenAI
人们确实担心人工智能会助长虚假或误导性信息的传播,从而动摇人心,达到恶意目的。 去年,政治相关的深度伪造像野火一样在全球蔓延,而且人工智能正越来越多地被用于针对消费者和企业实施社交工程攻击。
在 GPT-4.5 的白皮书和本周早些时候发布的文件中,OpenAI 指出,它正在修改其探测模型在现实世界中说服风险的方法,例如大规模发布误导信息。