Fable 5上线方案公布 Anthropic想给AI越狱定一把尺
7月1日消息,当地时间周二,Anthropic发布长文,详细解释Claude Fable 5和Claude Mythos 5被美国出口管制、暂停访问、再恢复上线的全过程。这不是一篇简单的恢复公告。更重要的是,Anthropic正在把 “AI模型越狱到底有多严重” 变成一套行业评分框架,并进一步把前沿模型发布纳入政府预发布测试和安全协作。

根据Anthropic公告,Fable 5将从7月1日起面向全球用户恢复开放,覆盖Claude Platform、Claude.ai、Claude Code和Claude Cowork。Pro、Max、Team和部分Enterprise用户在7月7日前可把Fable 5用于最多50% 的每周使用额度;之后将通过用量积分继续使用。Anthropic还称,将尽快在AWS、Google Cloud和Microsoft Foundry上重新启用访问。
Mythos 5的恢复范围更窄。Anthropic称,在美国政府6月26日批准后,公司已为一批美国机构恢复Mythos 5访问,并将继续与政府协调,扩大到Glasswing项目中的更多国内和国际合作伙伴。
一次 “越狱” 报告,引发模型下架
这轮风波开始于6月12日。
Anthropic称,美国政府当日对Claude Fable 5和Claude Mythos 5实施出口管制,要求限制外国国民访问这两款模型。这里的 “外国国民” 不仅包括美国境外用户,也包括在美国境内的非美国国民。由于指令立即生效,而Anthropic没有可靠办法实时核验所有用户国籍,公司最后选择暂停所有用户访问。
按照Anthropic最新复盘,Fable 5和Mythos 5是在6月9日发布的。两者底层模型相同,但面向场景不同:Fable 5加了更强安全防护,用于更广泛的普通用户场景;Mythos 5防护更少,仅面向少数可信的Project Glasswing合作伙伴,用于防御性网络安全任务。
美国政府介入的直接原因,是一份来自亚马逊研究人员的报告。报告称,研究人员找到了一种绕过Fable 5安全防护的方法,让模型识别出若干软件漏洞;其中一个案例里,模型还生成了演示如何利用相关漏洞的代码。
Anthropic的回应是:这件事暴露的是Fable 5安全防护中的一个边界案例,但并没有释放出Mythos级别的独特网络攻击能力。公司称,经过测试,Claude Opus 4.8、GPT-5.5、Kimi K2.7等能力更低的模型也能识别同样漏洞;在生成单个漏洞利用演示时,多个模型也能给出类似结果。
简言之,Anthropic想强调的是:这不是Fable 5突然表现出独有危险能力,而是安全分类器在一个模糊区域被绕过。
新分类器能拦住99% 以上,但会带来误伤
为恢复访问,Anthropic训练了一个新的安全分类器,专门拦截亚马逊报告中提到的行为。
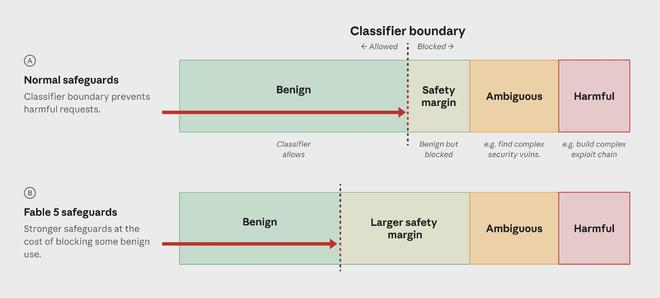
Anthropic称,新分类器可以在超过99% 的情况下阻止亚马逊报告中描述的那一种具体绕过技巧。被拦截的Fable 5请求会被转交给Claude Opus 4.8处理。美国商务部下属的AI标准与创新中心(CAISI)也测试了Anthropic新旧两套防护。
不过,这个修复并不是没有代价。
Anthropic承认,新分类器会在日常编程和调试任务中更频繁地误判良性请求。也就是说,一些正常的安全研究、代码调试或漏洞分析请求,可能被系统挡下来。公司称,后续会继续优化,尽量区分真实滥用和合法请求。
这也是Fable 5事件的核心难题:模型能力越强,越能帮助防御性安全工作;但同样的能力也可能被用于攻击。厂商不只是要回答 “能不能拦住坏请求”,还要回答 “会不会把好请求也拦死”。
Anthropic想给AI越狱分级
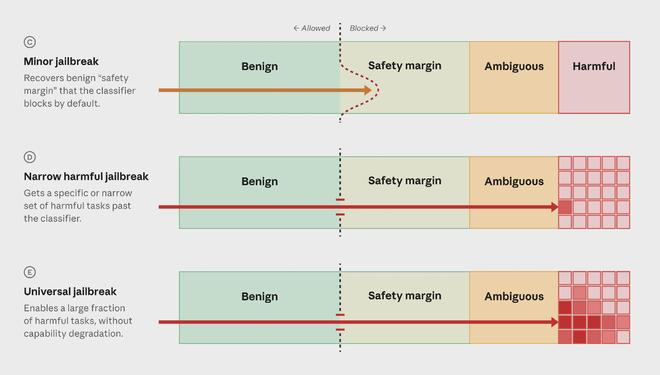
长文里最值得注意的部分,不是Fable 5恢复访问,而是Anthropic提出的 “AI越狱严重程度框架”。
Anthropic认为,目前行业还没有一套统一标准,用来判断某个AI越狱到底有多严重。结果是,每当新的绕过方法出现,开发者不知道应该多快修,政府也缺少一致标准判断是否需要介入。
Anthropic正在与亚马逊、微软、谷歌和其他Glasswing合作伙伴起草一套框架。它建议从四个维度给越狱风险打分:
第一,能力增益。越狱后,模型能不能做出现有公开工具和较弱模型做不到的事情。如果只是达到其他工具已有能力,风险较低;如果能显著加速专家级攻击,风险就高。
第二,能力范围。同一种越狱方法,是只能解锁一个很窄的任务,还是能覆盖多类攻击目标和技术路线。
第三,武器化难度。把这个越狱转成真实攻击,需要多少人工努力、提示技巧和反复尝试。如果一两次提示就能稳定成功,风险更高。
第四,可发现性。这个方法是需要专业知识才能找到,还是已经在网上广泛传播。
这套框架的意义在于,它试图把 “AI越狱” 从笼统恐慌,拆成可沟通、可排序、可修复的问题。以后模型被发现漏洞时,厂商和政府可以先判断:这是低风险边界案例,还是必须立即部署缓解措施的高危越狱。
Anthropic还计划推出新的HackerOne项目,让安全研究人员提交Fable 5潜在网络安全越狱案例。
前沿模型发布正在变成 “政府也要先看”
Anthropic在文末还给出一组更长期的承诺:对涉及国家安全相关前沿能力的模型,将向指定政府伙伴提供更早访问权限,让政府在广泛发布前测试模型和配套防护;当出现重要越狱或滥用模式时,更快向政府共享信息;同时投入专门团队和算力,参与AI安全评测与研究。
这意味着,前沿AI模型的发布流程正在发生变化。
过去,模型发布主要是公司的产品节奏:训练、评测、红队测试、上线。Fable 5事件之后,至少在网络安全等高风险方向,发布流程可能多出一层政府预发布评估、信息共享和风险协商。
对用户来说,Fable 5恢复上线是好消息;但对企业客户来说,这次事件留下了更现实的提醒:前沿模型的可用性不只取决于技术和价格,也取决于政策状态。一款模型即使已经发布,也可能因为安全争议突然暂停,再通过补防护、谈判和政府测试恢复。
对Anthropic来说,这次复盘既是在解释下架原因,也是在争夺话语权:公司希望外界相信,Fable 5不是失控模型,而是一个被过度谨慎处理的边界案例;同时,它也希望把行业焦点从 “模型能不能被越狱” 转到 “越狱严重程度该怎么判断”。
这可能才是这份公告真正重要的信号。Fable 5重新上线只是结果,前沿模型以后怎么被测试、怎么被放行、怎么被政府介入,才是这场风波留下的新问题。