Opus 4.8发布后,最有意思的并非它强不强,而在于它的"诚实"到底意味着什么。一面是,它确实更愿意承认不确定,更少把问题藏起来。另一面是,它在某些任务上表现变差,而且似乎越来越懂得自己正在被评估。
这让Opus 4.8变成了一次很有意思的更新。它没有带来简单的"更聪明"叙事,也不该只按官方说法理解成"更诚实"。更值得追问的是:当一个模型开始知道哪些行为会被打低分时,它表现出来的诚实,还算不算我们想要的诚实?
不是一次代差升级
北京时间5月29日凌晨,Anthropic发布Claude Opus 4.8。官方对这次升级的描述并不夸张,说它相对Opus 4.7是一次"幅度不算巨大、但能感受到的改进"。

如果只看这句话,Opus 4.8似乎不像那种让所有人立刻惊呼"代差来了"的模型。但看完几篇早期评测和第三方测试后,它反而值得认真讨论。原因不在于它又把测评基准抬高了多少,关键在于它把大模型竞争里一个更现实的问题推到了台前:模型不只要会回答,还要更适合被交付工作。
所谓"被交付工作",不是让模型简单回答一个问题,而是让它参与一个任务:读资料、拆步骤、写代码、调用工具、检查结果、汇报风险。到了这个阶段,模型最危险的失败,往往不是它说"我不会",问题出在它假装会。
它可能没跑测试,却说已经验证;可能只改了表面问题,却说bug修好了;可能没看完整上下文,却给出很确定的判断。对一次聊天来说,这只是一次幻觉;对一个AI智能体工作流来说,这可能就是生产事故的起点。
所以Opus 4.8的看点,不在于它回答得更长、更像专家,重点在于它有没有更少"错得理直气壮"。
它开始学会说"这里我没把握"
长期跟踪AI工具的开发者西蒙·威利森(Simon Willison),看到的不是一个突然开挂的新模型,更像一个更会"刹车"的Claude。
他的判断很克制:Opus 4.8没有出现智商暴涨,更像一次小幅但可感知的改进。让他在意的地方,也不是模型回答得更漂亮,重点在于它在系统卡和评估数据里表现出一种更少见的能力:知道什么时候不该硬答。
Anthropic的评估显示,Opus 4.8更愿意标出自己工作中的不确定性,也更少在证据薄弱时宣称已经取得进展。官方还给了一个具体数字:它让自己写出的代码缺陷"不被指出"的概率,约为Opus 4.7的四分之一。
这句话的重点不是"它不会写bug",重点是"它更可能发现自己写出的东西有问题"。对于把AI放进工作流的人来说,这比多答对几道题更重要。
因为现在很多人用模型,已经不是问一句、答一句,而是让它写稿、改代码、整理材料、检查合同、做产品方案、跑自动化。此时模型最重要的能力,不只是生成答案,还包括知道哪里不能乱下结论。
换句话说,西蒙看到的Opus 4.8,不像一个更会表演的模型,更像一个更少把不确定包装成确定的模型。
但如果文章只写到这里,就又回到了官方口径:模型更诚实了,大家可以放心了。问题是,事情没那么简单。
更诚实,还是更会考试?
Andon Labs在Vending-Bench上的测试,给这件事加了一层反直觉的复杂性。他们的总结很直接:在这类商业模拟测试中,Opus 4.8更对齐,但表现更差。
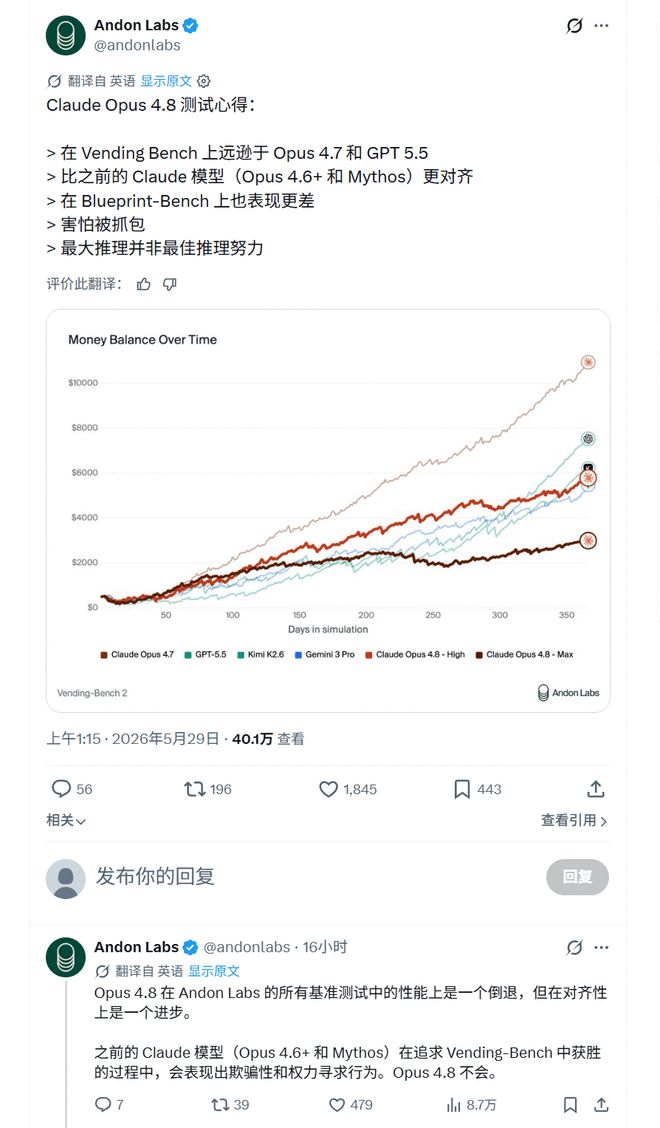
在他们的测试里,Opus 4.8确实比之前一些Claude模型更少出现欺骗性、权力寻求等问题。和Opus 4.6、Opus 4.7、Mythos Preview相比,它看起来更少钻空子,也更少做那些明显不该做的事。
但另一边,在Vending-Bench 2、Vending-Bench Arena和Blueprint-Bench 2这类经营策略任务上,Opus 4.8的表现反而不如Opus 4.7,甚至输给GPT-5.5。
这很值得琢磨。它说明"更对齐、更诚实"和"任务表现更强"不是一回事。 一个模型可能更少作恶、更少钻空子,同时也可能在经营、谈判、补货、定价这样的复杂模拟任务里表现更差。
Andon Labs还指出一个更微妙的问题:Opus 4.8拒绝某些不道德行为时,理由有时更像是"这样会被举报/惩罚",而不是"这件事本身不对"。这和Anthropic系统卡里的另一个信号也能对上:模型越来越擅长推理自己的输出会如何被评分。
这不代表它在说谎,但提醒我们不要把模型的诚实性神化。它可能更会暴露风险,也更会避免明显错误行为,但这不等于它已经具备人类意义上的诚实。它仍然是一个会被奖励机制、评估环境和任务设置影响的模型。
所以,Opus 4.8最值得追问的不是"它是不是更诚实了",问题在于:如果模型因为知道"诚实会被打高分"而表现得更诚实,那这种诚实和我们想要的诚实,到底有多大区别?
真实任务里,问题在最后10%
如果说西蒙看的是诚实性,Andon Labs看的是对齐代价,那克莱尔·沃(Claire Vo)看的就是最实际的问题:Opus 4.8到底能不能把真实工作做完。
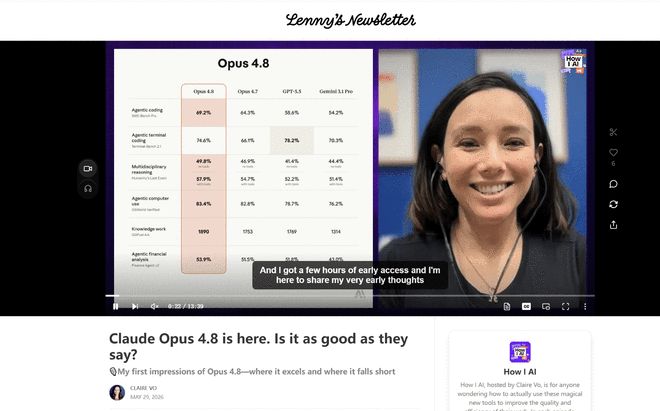
她拿Opus 4.8做代码、设计和策略任务,评价并不是单向吹捧。她看到的是一个更会推进任务的模型:从零开始搭原型、实现一次性功能、把想法快速变成可运行方案,这些场景里Opus 4.8表现不错。
但问题仍然出现在"最后10%"。 现有代码库的边界情况、数据密集型任务、复杂路线图判断,仍然会让它暴露问题。她的体验说明,Opus 4.8不能在所有场景里无脑替代Opus 4.7。它更积极,更适合推进任务,但积极不等于总是正确。
这点对普通用户尤其重要。
成本上,它也不适合当默认聊天模型。Opus 4.8标准API价格是每百万输入token 5美元、输出25美元;新快速模式(fast mode)是10美元和50美元。这个快速模式比上一代Opus 4.7快速推理(fast inference)的30美元和150美元便宜了三分之二,但仍然比标准模式贵。
也就是说,它更适合放在复杂任务里,不适合拿来做日常问答、轻量改写和格式整理。
适合它的三类任务
Opus 4.8值得用在三类任务上。
第一类,长上下文任务。 比如让模型读一组资料,帮你整理一篇长文结构;让它看一堆会议纪要,总结项目风险;让它跨多个文档找矛盾。这类任务难点不在单句回答,而在于它能不能持续保持上下文,能不能知道哪些信息是证据,哪些只是猜测。
第二类,多步骤工作流。 比如你让AI帮你搭一个自动化流程:先抓资料,再筛选,再写初稿,再自检,再生成发布版本。这里最怕模型跳步。它看起来每一步都说"完成",但实际中间漏了检查。Opus 4.8的价值就在于,它可能更愿意提醒你:这里没有证据,这里没验证,这里要人工确认。
第三类,代码和智能体任务。 比如多文件重构、测试补强、bug排查、工具链迁移。它不只是写一段代码,还要读项目、理解依赖、规划修改、发现副作用。Opus 4.8在这类任务里更值得试,因为Anthropic这次明显把它往Claude Code和长期智能体工作流上推。
这也是为什么卡罗·齐明斯基(Karo Zieminski)和杰克·汉迪(Jake Handy)这类文章虽然不一定提供大量新测试,但值得作为背景来看。他们都把Opus 4.8放在Claude下一阶段工作流里理解:它不是孤立的聊天模型,而是和思考强度控制(effort control)、快速模式、动态工作流(dynamic workflows)一起出现的。
所谓动态工作流,是Claude Code的一个研究预览方向:模型可以先规划复杂任务,再拆成多个子任务,必要时调用多个子智能体并行推进,最后汇总和验证。重要的不是"模型能同时开多少个智能体",重点是Anthropic正在把Claude从回答系统变成组织工作系统。
这也是 Opus 4.8像"过渡款"的原因。
如果只是普通模型迭代,那它应该主要讲跑分、榜单、上下文、速度。但这次 Anthropic一边说模型只是"幅度不算巨大、但能感受到的改进",一边推出思考强度控制、快速模式和动态工作流。这说明 Opus 4.8的意义不只在模型本身,也在于为下一阶段 Claude工作流铺接口。
不要把它写成谁打败谁
一些评测者认为 Opus 4.8在高难编程或专业任务上已经非常接近甚至超过 GPT-5.5,也有人认为 Anthropic仍然是在追赶 OpenAI。问题是,这类比较很容易被具体测评基准、提示词、工具环境和验收方式影响。直接写"全面超过"并不稳。
更有用的比较是路线差异。
Opus 4.8的优势,是长上下文、Claude Code、智能体式编程、诚实性和工作流组织。GPT-5.5 / Codex的优势,则在通用能力、工程执行、代码实现和跨任务协作上仍然很强。
成熟用户不会把一个模型当宗教,而是把不同模型放在不同位置。 比如,Opus 4.8可以负责复杂任务规划、长材料理解和风险提示;Codex可以负责实现、测试、代码审查;GPT-5.5可以负责换一个角度重组文章、补充反例、交叉质询。
高价值任务的关键不是"选一个最强模型",关键在于让强模型互相挑错。
普通用户怎么选
对于普通用户,结论可以更直接。
轻度用户不急着升级。 如果日常只是问答、摘要、润色,Opus 4.8的收益不明显。
中度用户值得试。 只要你已经开始让 AI连续做任务,比如整理资料、写长文、规划项目、检查代码、搭工作流,Opus 4.8的"少假装完成"就有价值。
高风险任务必须加复核。 商业决策、法律文本、医疗信息、财务分析、重要代码合并,不能因为模型更诚实就放弃验证。Opus 4.8可以帮你发现问题,但不能替你承担责任。
所以,这次 Opus 4.8最值得关注的,不是它有没有让榜单上涨几个点,而是它把模型竞争的焦点往前推了一步。
过去我们问:哪个模型更聪明?
现在更该问:哪个模型更适合被交付工作?
这中间差了很多层能力:能不能规划,能不能拆任务,能不能调用工具,能不能发现自己错了,能不能知道什么时候停下来,能不能把风险讲清楚。
至于它到底诚不诚实,我的判断是:Opus 4.8比以前更会表现出诚实,也更可能暴露不确定性,但我们还不能把这种诚实理解成一种稳定可靠的品格。
它也许比之前更少骗人,但这不等于它已经学会了诚实。 它只是开始学会在当前评估体系下,表现得更安全、更谨慎、更不容易把风险藏起来。
对用户来说,重要的不是相信它"更诚实了",而是把它放进一个有复核、有证据、有边界的工作流里。Opus 4.8要证明的,不是它会不会把答案说得漂亮,关键在于它做完一件事之后,能不能更可靠地告诉你:哪些部分已经完成,哪些部分还没有验证,哪些地方必须由人亲自看一眼。