AMD发布RyzenClaw和RadeonClaw 可在本地硬件运行AI代理
AMD 正在推动一个并非依赖云端的人工智能愿景,其最新发布的 OpenClaw 框架,配合两套硬件参考配置 RyzenClaw 与 RadeonClaw,旨在让开发者和早期尝鲜者在本地 PC 上运行大型语言模型和多智能体工作流。 这一举措隶属于 AMD 更大的“Agent Computer”计划,该计划认为 AI 的未来不应局限于远程数据中心,而是应让用户掌控自己的数据和计算环境,让本地 AI 助手长期运行、降低网络依赖和订阅负担,同时缓解隐私忧虑。

从技术路径看,OpenClaw 目前在 Windows 平台上通过 WSL2(Windows Subsystem for Linux 2)运行,由 LM Studio 搭配 llama.cpp 后端承担本地推理任务。 在这一环境下,用户可以直接在本机上运行包括 Qwen 3.5 35B A3B 在内的模型。 系统还支持名为 Memory.md 的嵌入式记忆框架,用于在本地存储上下文信息,无需依赖云端同步。 AMD 将官方教程定位为一条相对精简的配置路径,方便开发者在 Windows 上搭建完整的 OpenClaw 环境并测试 AI 智能体架构,不过文档并未给出明确的预计配置耗时。

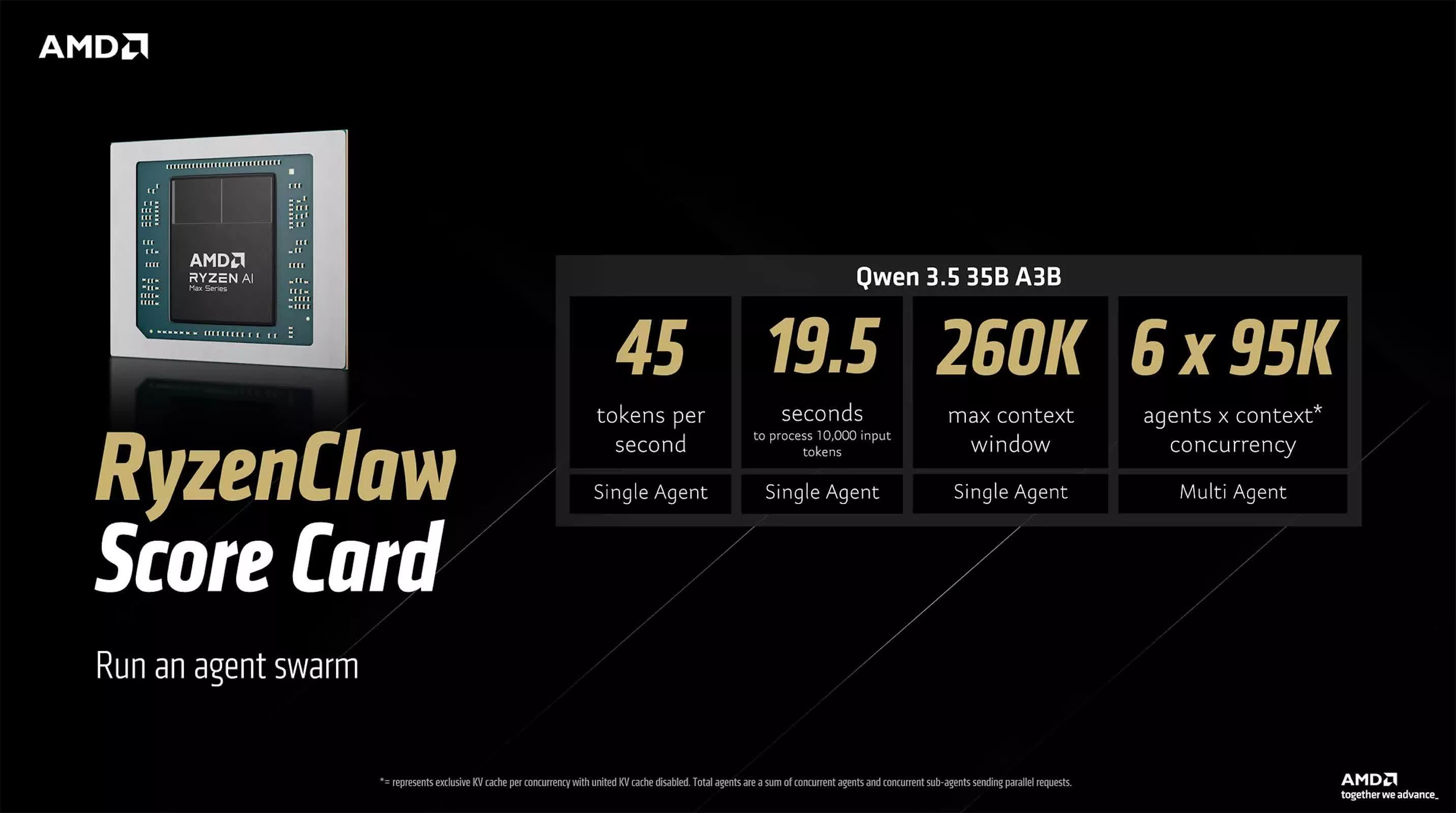
AMD 提出的两种 OpenClaw 参考方案代表了通往“高性能本地 AI”的不同路线。 RyzenClaw 方案围绕 Ryzen AI Max+ 处理器构建,配备 128GB 统一内存,AMD 建议其中约 96GB 作为可变显存分配,以保证大模型推理效率。 在该配置下,Qwen 3.5 35B A3B 的生成速度约为每秒 45 个 token,处理 1 万 token 输入大约需要 19.5 秒,支持约 26 万 token 的上下文窗口,可用于多智能体工作流或“智能体集群”实验环境。 AMD 表示,这一平台最多可同时运行 6 个本地 AI 智能体,这在非数据中心级系统中颇具代表性。

另一套 RadeonClaw 配置则将算力重心转移到独立 GPU —— Radeon AI PRO R9700。 这款工作站级显卡提供 32GB 专用显存,显著提升了推理吞吐量。 在同一模型下,其生成速度可提升至每秒约 120 个 token,将处理 1 万 token 输入的时间缩短至约 4.4 秒。 不过,这种性能增益伴随一定取舍:最大上下文窗口缩减至约 19 万 token,并发智能体数量降至 2 个。 这些差异凸显了 AMD 试图提供不同调优路径的思路——开发者可根据自身需求,在更大上下文深度和更高推理速度之间做出权衡。
就定位而言,无论是 RyzenClaw 还是 RadeonClaw,都不是面向普通消费者的入门配置。 以 RyzenClaw 为例,一台基于 Ryzen AI Max+ 395 芯片并搭载 128GB 内存的台式机(例如 Framework Desktop 方案)起步价格约为 2700 美元。 如若选择 RadeonClaw 路线,还需额外购买 Radeon AI PRO R9700 显卡,仅该卡建议零售价就约为 1299 美元。 AMD 目前也坦言,OpenClaw 的主要目标用户是正在尝试本地 AI 智能体的工程师和早期采用者,而非主流 PC 用户。

尽管如此,OpenClaw 传递的讯息已超出具体硬件本身。 AMD 押注于这样一种趋势:开发者会更重视自治与隐私,而不仅仅是云端规模的扩张,希望通过运行在消费级芯片上的本地智能体,在个人计算与分布式 AI 之间搭建桥梁。 若这一思路获得生态的认可,AMD 有望在快速演进的 AI 版图中占据一个独特位置,让部分高端桌面与工作站逐渐具备接近数据中心的 AI 处理能力,同时保持用户侧的掌控感与灵活性。